NLP实践六:Fasttext实现文本分类
文章目录
- 一 Fasttext原理
- 模型架构
- 层次SoftMax
- N-gram子词特征
- 二 Pytorch代码实践
- 模型定义:
- 训练函数定义:
- 数据加载:
- 训练:
一 Fasttext原理
fasttext是facebook开源的一个词向量与文本分类工具,在2016年开源,典型应用场景是“带监督的文本分类问题”。提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
参考FastText算法原理解析
模型架构
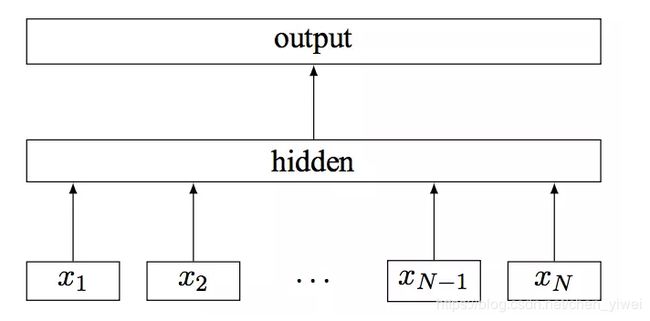
fastText模型架构:
其中 x 1 , x 2 , . . . , x N − 1 , x N x_1,x_2,...,x_{N-1},x_N x1,x2,...,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
层次SoftMax
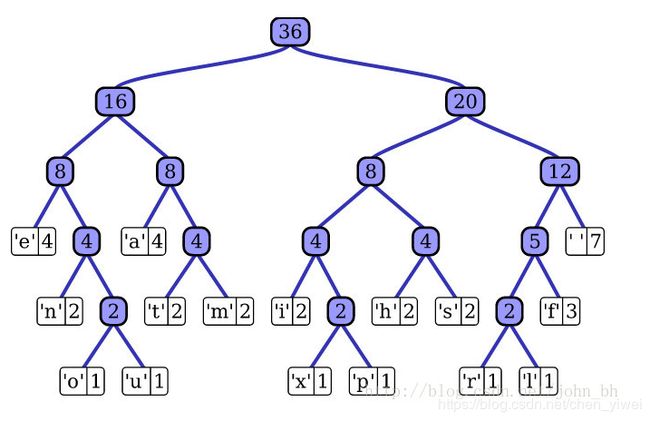
对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高.
N-gram子词特征
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。在 fasttext 中,每个词被看做是 n-gram字母串包。为了区分前后缀情况,"<", ">"符号被加到了词的前后端。除了词的子串外,词本身也被包含进了 n-gram字母串包。以 where 为例,n=3 的情况下,其子串分别为
二 Pytorch代码实践
使用wordembeddings来实现fasttext模型,数据集为ThuCnews
数据预处理部分在我之前的文章有提到分词的基本概念与生成词向量矩阵。
模型定义:
import torch
from torch import nn
import numpy as np
import torch.nn.functional as F
class fastText(nn.Module):
def __init__(self,word_embeddings):
super(fastText, self).__init__()
self.hidden_size=100
self.embed_size=200
self.classes =10
# Embedding Layer
self.embeddings = nn.Embedding(len(word_embeddings),self.embed_size)
self.embeddings.weight.data.copy_(torch.from_numpy(word_embeddings))
self.embeddings.weight.requires_grad = False
# Hidden Layer
self.fc1 = nn.Linear(self.embed_size, self.hidden_size)
# Output Layer
self.fc2 = nn.Linear(self.hidden_size, self.classes)
# Softmax non-linearity
self.softmax = nn.Softmax()
def forward(self, x):
##embedded_sent = self.embeddings(x).permute(1,0,2)
embedded_sent = self.embeddings(x)
h = self.fc1(embedded_sent.mean(1))
z = self.fc2(h)
return self.softmax(z)
训练函数定义:
def train(train_loader, val_loader,
model, device,
criterion, optimizer,
num_epochs, nb_class=10):
model.to(device)
loss_meter = meter.AverageValueMeter()
pre_loss = 1e10
best_avg_f1 = 0.0
best_model_wts = model.state_dict()
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
model.train()
loss_meter.reset()
pred = []
y_true = []
for i, (data, label) in tqdm(enumerate(train_loader)):
data, label = data.to(device), label.to(device)
optimizer.zero_grad()
score = model.forward(data)
loss = criterion(score, label)
loss.backward()
optimizer.step()
loss_meter.add(loss.item())
pred += t.max(score, dim = 1)[1].detach().tolist()
y_true += label.detach().tolist()
running_loss = loss_meter.value()[0]
categories = ['体育', '财经', '房产', '家居', '教育', '科技', '时尚', '时政', '游戏', '娱乐']
classification_report_str = classification_report(y_true, pred, target_names=categories)
precision,recall,avg_f1,support=score_support(y_true,pred,average='macro')
print(f'Train Epoch Loss: {running_loss:.4f} AVG_F1: {avg_f1:.4f}\n {classification_report_str}')
model.eval()
loss_meter.reset()
pred = []
y_true = []
for i, (data, label) in tqdm(enumerate(val_loader)):
data, label = data.to(device), label.to(device)
score = model.forward(data)
loss = criterion(score, label)
loss_meter.add(loss.item())
pred += t.max(score, dim = 1)[1].detach().tolist()
y_true += label.detach().tolist()
epoch_loss = loss_meter.value()[0]
precision,recall,avg_f1,support=score_support(y_true,pred,average='macro')
classification_report_str = classification_report(y_true, pred, target_names=categories)
print(f'Val Epoch Loss: {epoch_loss:.4f} AVG_F1: {avg_f1:.4f}\n {classification_report_str}')
if avg_f1 > best_avg_f1 or running_loss < pre_loss:
best_avg_f1 = avg_f1
best_model_wts = model.state_dict()
print('Val Acc or Train Loss improved')
数据加载:
import pickle
import pandas as pd
import torch
import torch.utils.data as data
from sklearn.model_selection import train_test_split
from torch.utils.data.dataset import Dataset
class MyDataset(Dataset):
def __init__(self, data_path,
w2i_path,
max_len=57):
super(MyDataset, self).__init__()
#self.data = pd.read_csv(data_path)
self.data = pickle.load( open (data_path, "rb" ))
self.content = self.data['content'].values
self.labels = torch.from_numpy(self.data['label_id'].values)
self.w2i = pickle.load(open(w2i_path, "rb"))
self.max_len = max_len
def __len__(self):
return self.labels.size(0)
def __getitem__(self, index):
label=self.labels[index]
content = self.content[index]
document_encode = [self.w2i[word] if word in self.w2i else -1 for word in content]
if len(document_encode) < self.max_len:
extended_sentences = [-1] * (self.max_len - len(document_encode))
document_encode.extend(extended_sentences)
document_encode = torch.Tensor(document_encode[:self.max_len])
document_encode += 1
return document_encode.long(),label
def get_data_loader(data_path,
w2i_path,
max_len=100,
batch_size=512,
test_ration=0.2,
random_state=42,
mode='train'):
training_params = {"batch_size": batch_size,
"shuffle": True,
"drop_last": True}
test_params = {"batch_size": batch_size,
"shuffle": False,
"drop_last": True}
if mode == 'train':
dataset = MyDataset(data_path, w2i_path, max_len)
all_idx = list(range(len(dataset)))
training_set = data.Subset(dataset, all_idx)
training_loader = data.DataLoader(training_set, **training_params)
return training_loader
if mode == 'test':
dataset = MyDataset(data_path, w2i_path, max_len)
all_idx = list(range(len(dataset)))
test_set = data.Subset(dataset, all_idx)
test_loader = data.DataLoader(test_set, **test_params)
return test_loader
if mode == 'all':
dataset = MyDataset(data_path, w2i_path, max_len)
all_idx = list(range(len(dataset)))
train_idx, test_idx = train_test_split(all_idx, test_size=test_ration, random_state=random_state)
training_set = data.Subset(all_set, train_idx)
training_loader = data.DataLoader(training_set, **training_params)
test_set = data.Subset(all_set, test_idx)
test_loader = data.DataLoader(test_set, **test_params)
return training_loader, test_loader
w2i_path = 'cnews_w2i.pickle'
train_loader= get_data_loader(data_path='train.pickle',
w2i_path =w2i_path,
max_len =400,
batch_size=512,
mode='train')
val_loader = get_data_loader(data_path='val.pickle',
w2i_path =w2i_path,
max_len =400,
batch_size=512,
mode='train')
embed_weight = pickle.load(open('embedding_matrix.pickle', 'rb'))
embed_num, embed_dim = embed_weight.shape
训练:
import os
os.environ['CUDA_VISIBLE_DEVICES']='0'
t.cuda.set_device(0)
Fasttextmodel = fastText(embed_weight)
criterion = nn.CrossEntropyLoss()
optimizer = optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.001)
train(train_loader, val_loader,
Fasttextmodel, 'cuda',
criterion, optimizer,
num_epochs=20)