爬虫requests高级用法
一 文件上传
1 代码
import requests
#favicon.ico需要和当前脚本在同一目录下。
files = {'file': open('favicon.ico', 'rb')}
r = requests.post("http://httpbin.org/post", files=files)
print(r.text)2 运行结果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/3_2_2.py
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64,AAABAAIAEBAAAAEAIAAoBQAAJgAAACAgAAABACAAKBQAAE4
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "6665",
"Content-Type": "multipart/form-data; boundary=ea9414f1b8ae442f768c08b6a62b8082",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.21.0"
},
"json": null,
"origin": "106.36.218.77",
"url": "http://httpbin.org/post"
}
Process finished with exit code 03 说明
这个网站会返回响应,里面包含files这个字段,而form字段是空的,这证明文件上传部分会单独有一个files字段来标识。
二 Cookies
1 代码
import requests
r = requests.get("https://www.baidu.com")
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)2 运行结果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/3_2_2.py
3 说明
首先调用cookies属性即可成功得到Cookies,可以发现它是RequestCookieJar类型。然后用items()方法将其转化为元组组成的列表,遍历输出每一个Cookie的名称和值,实现Cookie的遍历解析。
三 Cookie来维持登录状态
1 首先登录知乎,将Headers中的Cookie内容复制下来。
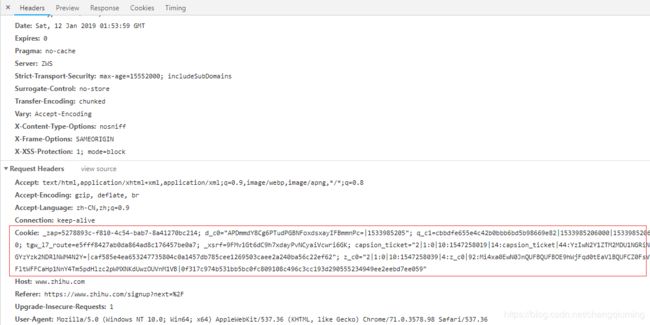
2 代码
import requests
headers = {
'Cookie': '_zap=5278893c-f810-4c54-bab7-8a41270bc214; d_c0="APDmmdY8Cg6PTudPGBNFoxdsxayIFBmmnPc=|1533985205"; q_c1=cbbdfe655e4c42b0bbb6bd5b98669e82|1533985206000|1533985206000; tgw_l7_route=e5fff8427ab0da864ad8c176457be0a7; _xsrf=9FMv1Gt6dC9h7xdayPvNCyaiVcwri6GK; capsion_ticket="2|1:0|10:1547258019|14:capsion_ticket|44:YzIwN2Y1ZTM2MDU1NGRiN2I3MGYzYzk2NDRlNWM4N2Y=|caf585e4ea653247735804c0a1457db785cee1269503caee2a240ba56c22ef62"; z_c0="2|1:0|10:1547258039|4:z_c0|92:Mi4xa0EwN0JnQUFBQUFBOE9hWjFqd0tEaVlBQUFCZ0FsVk50cFltWFFCaHp1NnY4Tm5pdHlzc2pWMXNKdUwzOUVnM1VB|0f317c974b531bb5bc0fc809108c496c3cc193d290555234949ee2eebd7ee059"',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
r = requests.get('https://www.zhihu.com', headers=headers)
print(r.text)3 结果
我们发现,结果中包含了登录后的结果,如图3-7所示,这证明登录成功。
![]()
四 会话维持
1 点睛
在requests中,如果直接利用get()或post()等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开了不同的页面。
设想这样一个场景,第一个请求利用post()方法登录了某个网站,第二次想获取成功登录后的自己的个人信息,你又用了一次get()方法去请求个人信息页面。实际上,这相当于打开了两个浏览器,是两个完全不相关的会话,能成功获取个人信息吗?那当然不能。
有小伙伴可能说,我在两次请求时设置一样的cookies不就行了?可以,但这样做起来显得很烦琐,我们有更简单的解决方法。
其实解决这个问题的主要方法就是维持同一个会话,也就是相当于打开一个新的浏览器选项卡而不是新开一个浏览器。但是我又不想每次设置cookies,那该怎么办呢?这时候就有了新的利器——Session对象。
2 代码
import requests
requests.get('http://httpbin.org/cookies/set/number/123456789')
r = requests.get('http://httpbin.org/cookies')
print(r.text)
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)3 说明
所以,利用Session,可以做到模拟同一个会话而不用担心Cookies的问题。它通常用于模拟登录成功之后再进行下一步的操作。
Session在平常用得非常广泛,可以用于模拟在一个浏览器中打开同一站点的不同页面