TI openmp target语法讲解
Data: 2017.01.02
Author: cjh
Theme: TI openmp target语法讲解
OpenMP Accelerator模式总来的来说就是在用target关键字,要操作的buff区映射到DSP上进行执行,在将结果返回到ARM上。
常见的设备结构有
#pragma omp target
#pragma omp declare target
#pragma omp target data
#pragma omp target update
接下来将进行逐个举例讲解,在讲解之前先对几个关键字进行讲解
to: 是将主机内存复制到设备内存
from: 是从设备内存复制到主机内存
tofrom:是先将主机内存复制到设备内存,再从设备内存复制到主机内存
local: 是将分配的内存映射到L2 scratchpad memory
1. #pragma omp target
目标结构用于指定需要映射的代码区域,通过将主机缓存区映射到设备区进行执行。执行完成后在从设备区回到主机区,代码如下:
float a[1024];
float b[1024];
float c[1024];
int size;
void vadd_openmp(float *a, float *b, float *c, int size)
{
#pragma omp target map(to:a[0:size],b[0:size],size) map(from: c[0:size]) //通过target map对内存进行映射
{
int i;
#pragma omp parallel for //openmp for循环并行代码
for (i = 0; i < size; i++)
c[i] = a[i] + b[i];
}
}
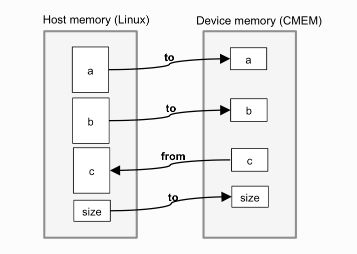
在上面的例子中,变量a,b,c和size最初驻留在主机(ARM Linux)内存中。 遇到目标构造时:
■空间分配在变量a [0:size],b [0:size],c [0:size]和size中的设备内存中。
■任何注释为“to”的变量都从主机存储器→设备存储器复制。
■目标区域在设备上执行。 请注意,#pragma omp parallel for用于在8个DSP内核之间分配for循环的迭代。
■任何标注为“from”的变量都将从设备内存→主机内存中复制。
具体的见下图所示:
2. #pragma omp declare target
#pragmaomp declare target和#pragma omp end declare target配合使用,用于声明在目标设备上执行的函数。具体的见以下例程,其中DSPF_sp_fftSPxSP为DSPLIB库代码,该函数只能在DSP上进行运行。
#pragma omp declare target
/* There must be a host and accelerator target definition for this function */
void DSPF_sp_fftSPxSP(int N,
float *x, float *w, float *y,
unsigned char *brev,
int n_min, int offset, int n_max);
#pragma omp end declare target
void dsplib_fft(int N, int bufsize,
float* x, float* w, float *y,
int n_min, int offset, int n_max)
{
#pragma omp target map(to: N, x[0:bufsize], w[0:bufsize], \
n_min, offset, n_max) \
map(from: y[0:bufsize])
{
DSPF_sp_fftSPxSP (N, x, w, y, 0, n_min, offset, n_max);
}
}
3. #pragma omp target data
可用于将主机端数据映射到设备端。 目标区域可以在设备数据环境中执行。 而且,映射的缓冲区可以被多个封闭的目标区域重新使用,并且对于“目标数据”区域的整个范围有效。 目标数据区域也可以嵌套。/* Create device buffers for a, b, c and transfer data from Host -> Device for a,b */
#pragma omp target data map(to:a[0:size], b[0:size]) map(from:c[0:size])
{
/* Existing device buffers are used and no data is transferred here */
#pragma omp target
{
int i;
#pragma omp parallel for
for (i = 0; i < size; i++)
c[i] += a[i] + b[i];
}
} /* Device -> Host data transfer of buffer c is done here*/
4. #pragma omp target update
用于同步主机端和设备端的数据,以下例程buffer c现在设备端进行操作,在从设备端更新到主机端,在主机端操作完成后,在更新会设备端。具体的见to和from的详解void operate_on_host(int* buffer);
#pragma omp declare target
void operate_on_device_initial(int* srcA, int* srcB, int* result);
void operate_on_device_final(int* srcA, int* srcB, int* result);
#pragma omp end declare target
/* Create device buffers for a, b, c and transfer data from Host -> Device for a,b */
#pragma omp target data map(to:a[0:size], b[0:size]) map(from:c[0:size])
{
/* Existing device buffers are used and no data is transferred here */
#pragma omp target
{
/* Here buffer c is modified with results while operating on input buffers a,b */
operate_on_device_initial(a,b,c);
}
/* Copy modified target data to the host */
#pragma omp target update from(c[0:size])
/* Do some host side processing */
operate_on_host(c);
/* Synchronize c with target device data buffer */
#pragma omp target update to(c[0:size])
/* Offload more computation to target device */
#pragma omp target
{
operator_on_device_final(a,b,c);
}
} /* Device -> Host data transfer of buffer c is done here again*/