Hadoop从零开始搭建高可用(HA)集群——3.zookeeper集群搭建(一主两从)
前言
本篇采用的软件及版本VmWare14、Centos7、xshell6、xftp6。已在本系列的第一篇中介绍下载。
开始
1.使用yum安装jdk 1.8
我们新装好的环境是不带jdk的,不信你试试使用命令 java -version查看一下
我们可以使用yum一行命令下载并安装好Jdk
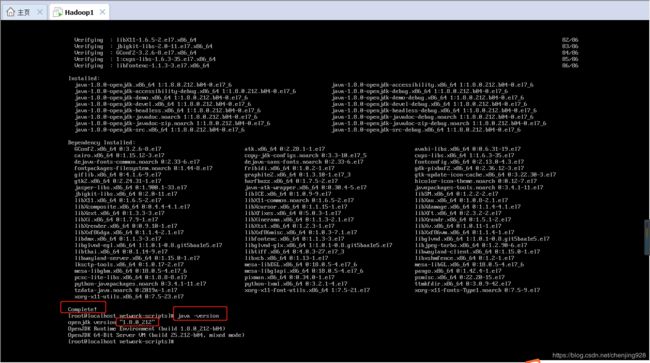
yum -y install java-1.8.0-openjdk*执行完成后,使用如下命令查看是否已经搞定
java -version如果成功,将会显示如下图所示
2.zookeeper安装
zookeeper集群整体步骤:因我们搭建的是zookeeper集群,一主两从模式,因此我们总共需要三台虚拟机,先在这个192.168.0.101 (Hadoop1) 机器上安装配置好通用的zookeeper配置,然后我们再克隆2台虚拟机,克隆的虚拟机跟Hadoop1的所有文件和配置都是一样的,因此我们需要更改克隆的Hadoop2虚拟机的Ip和zookeeper的非通用的配置。
第一篇中我们已经下载好了zookeeper在本地系统中,我们现在如何把它从本地windows传到虚拟机Linux里呢?
使用xftp,这个工具的使用方式和xshell差不多,相信聪明的你,会了xshell,那这个肯定也会,首先我们连接到虚拟机,然后你发现界面是分左右两边的,左边是我们的本地windows系统,右边是虚拟机Linux系统。
找到第一篇中已经下载好的zookepper的路径,对着文件点击右键,传输到linux的 /root目录下即可(打开后默认就是这个目录)

传输完成后,我们使用xshell连接到Hadoop1这个虚拟机。
按如下步骤操作
1.解压zookeeper
tar zxvf zookeeper-3.4.14.tar.gz2.给解压好的zookeeper换个简短点的名字
mv zookeeper-3.4.14 zookeeper3.进入到zookeeper的conf目录
cd zookeeper/conf4.修改 zoo_sample.cfg 文件名为 zoo.cfg
mv zoo_sample.cfg zoo.cfg5.编辑zoo.cfg
vi zoo.cfg
编辑内容如下,(按 i 进入编辑模式,编辑完成后 按ESC退出编辑模式,输入:wq 回车 保存并退出)
tickTime=2000
initLimit=10
syncLimit=5
dataLogDir=/root/zookeeper/logs
dataDir=/root/zookeeper/data
clientPort=2181
server.1= 192.168.0.101:2888:3888
server.2= 192.168.0.102:2888:3888
server.3= 192.168.0.103:2888:3888dataLogDir是指日志存放的目录
dataDir是指数据存放的目录
server.x 是指zookeeper集群的各个机器的ip端口及serverId标识
我们这里写的是server.1 是 192.168.0.101 ,那么我们需要在192.168.0.101这台机器上配置serverId标识 为1.(具体操作请看步骤7)
6.创建data目录(在我们配置zoo.cfg的dataDir 路径)
mkdir /root/zookeeper/data7.在data目录下创建myid文件,并写入值1,这个是serverId标识,用来表明当前的这个机器是哪个节点,对应zoo.cfg里写的
server.1,server.2,server.3,我们当前机器是server.1,那么myid里写1即可
echo "1" >> /root/zookeeper/data/myidOK,我们的Hadoop1这台机器已经搞定
8.关闭Hadoop1机器

9.克隆虚拟机
额
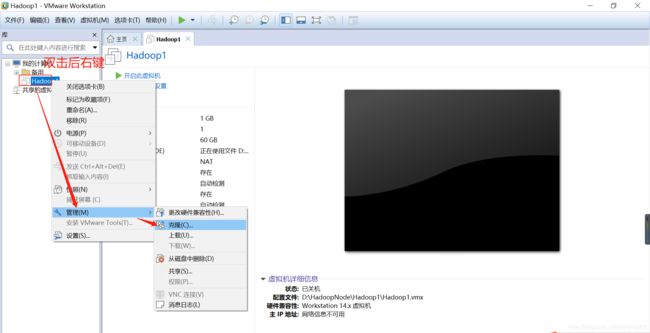
前面两个下一步都不需要改动,到这来我们选择创建完整的克隆
更改虚拟机名称和位置
我克隆了4台虚拟机,实际上目前只需要用得上3台,但是搭建Hadoop时候需要4台,于是我为了方便,就一起克隆了。
10.修改Hadoop2和Hadoop3的Ip
开启Hadoop2,账号和密码跟Hadoop1的一样,进去后,修改ifcfg文件的IPADDR
vi /etc/sysconfig/network-scripts/ifcfg-ens33再次说明一下,这里我的文件名后缀为ens33,我们的可能不相同,按照自己的进入文件
将 IPADDR 改为192.168.0.102
IPADDR=192.168.0.102改完后,别忘了重启服务
service network restartIp改为后,我们zookeeper的serverId标识别忘了修改,覆盖写入到myid文件中
echo "2" > zookeeper/data/myid使用同样的道理更改Hadoop3,将Hadoop3的ip改为192.168.0.103,myid改为3.
11.启动zookeeper集群
Hadoop1、Hadoop3、Hadoop3三台虚拟机都执行如下命令
cd /root/zookeeper/bin
./zkServer.sh start三台虚拟机都执行完上面两个命令后,随便查看一台zookeeper的状态
./zkServer status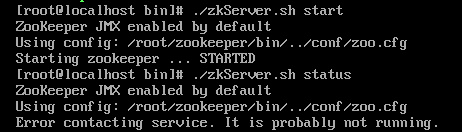
如果跟我一样的显示 Error contacting service.那么恭喜你,没有启动成功。
原因有两种可能,
1.没有关闭防火墙。
2.zoo.cfg 或 myid 配置有问题。
12关闭防火墙
三台虚拟机都执行如下命令
systemctl stop firewalld.service都关闭防火墙之后,再在随便一台虚拟机上查看 zookeeper状态,其中两台的会是follower,一台是leader,leader表明他是主,follower两台是从。

如果关闭防火墙后仍然不行,那么就是第二个问题,建议拉到上面按我的挨个执行一次,检查一下自己的各个虚拟机的ip跟zoo.cfg里配置的是否一样,myid是否对应上了。