ADO.NET操作数据库(三)
连接对象、命令对象 、Sql参数对象
SqlDataAdapter其实是对数据操作的封装,让我们写代码变得简单了,adapter是转换器的意思,不需要关心适配器内部是怎么实现的,它能够把数据库中的数据获取到内存里面。
分表存储、分区存储。
使用主从数据库:主数据库专门用来进行查询操作;从数据库专门用来做增删改操作。
————————————————————————————————————>
一:DataSet与DataTable
1)DataSet类:内存数据库、临时数据库。不仅仅是一个就集合。里面保存的是一张张表,表中是一条条记录。可以通过代码设置主键、外键、约束等。
2)DataTable类 数据表类
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.SqlClient;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ado.net练习四
{
class Program
{
static void Main(string[] args)
{
//动态创建数据库,数据表,列,记录;并且添加到表中。
string connStr = @"Data source=172.16.20.1\dev;initial catalog=MyFirstData;User ID=****;PASSWORD=****";
string sql = "select * from Teacher";
//用于存储查询到的结果集
DataTable dt = new DataTable();
//DataSet就是一个集合,内存数据库,临时数据库。
//参数为数据库的名称
DataSet ds = new DataSet("Teacher");
//创建一张表:指定表名
DataTable dt1 = new DataTable("Salary");
//现在不知道表中有几列几行? 向表中创建几列
DataColumn column = new DataColumn("AutoID", typeof(int));
//设置列为自动编号
column.AutoIncrement = true;
//设置自动编号的起始值为1
column.AutoIncrementSeed = 1;
//设置自动编号的步长为1
column.AutoIncrementStep = 1;
//把列添加到表里面
dt1.Columns.Add(column);
//增加一个性名列
//返回值为刚刚增加的列对象
DataColumn userColumn = dt1.Columns.Add("UserName", typeof(string));
//设置这一列的值不允许为空(姓名这一列的值不允许为空)
userColumn.AllowDBNull = false;
//增加一个 年龄列
DataColumn ageColumn = dt1.Columns.Add("UserAge", typeof(int));
//向表中增加一些记录
//创建一个行对象 DataRow这个类如何创建对象
//应该根据表的结构来创建行
DataRow dr = dt1.NewRow(); ;
dr["UserName"] = "陈如水";
dr["UserAge"] = 25;
dt1.Rows.Add(dr);
//向表中加入第二行数据
DataRow dr2 = dt1.NewRow(); ;
dr2["UserName"] = "陈诗音";
dr2["UserAge"] = 21;
dt1.Rows.Add(dr2);
//把表添加到数据库里面
ds.Tables.Add(dt1);
//遍历每张表以及每张表中的数据
//总共有几张表
for (int i = 0; i < ds.Tables.Count; i++)
{
//输出每个表的表名
Console.WriteLine("表名“{0}", ds.Tables[i].TableName);
//遍历表中的每一行
for (int j = 0; j < ds.Tables[i].Rows.Count; j++)
{
DataRow currentRow = ds.Tables[i].Rows[j];
//拿到当前行后,把每一列的值进行输出
for (int r = 0; r < ds.Tables[i].Columns.Count; r++)
{
Console.Write(currentRow[r]+"\t");
}
Console.WriteLine();
}
}
Console.WriteLine("OK");
Console.ReadKey();
//把查询数据库得到的数据放到内存当中
//using (SqlDataAdapter adapter = new SqlDataAdapter())
//{
// //实现了从数据库中读取数据,并加载到DataTable中 Fill()内部封装了最基本的操作
// adapter.Fill(dt);
//}
}
}
} //4)查询数据返回DataTable
public static DataTable ExecuteDataTable(string sql,params SqlParameter[] pms) {
DataTable dt=new DataTable();
using (SqlDataAdapter adapter=new SqlDataAdapter(sql, connStr))
{
if (pms!=null)
{
adapter.SelectCommand.Parameters.AddRange(pms);
}
adapter.Fill(dt);
}
return dt;
}二:内连接
--使用连接查询,不仅仅是一条Sql语句。
--将使用内连接查询到的sql语句。两张表对应两个model实体。
--内连接查询
--连接查询:当需要将多张表中的数据在一个表中显示时,就需要使用连接查询。
--连接:把多个表中的列连接起来。
--查询数据时,当需要将多个表中的列共同显示到一个结果集中的时候,就可以使用连接查询。
--这两张表是有主外键关系的。--内连接查询的使用 INNER JOIN ...on... (连接条件 笛卡尔积加上筛选条件)
--内连接:把多张表的数据在一个表中显示
--为什么使用表名.列名,为了防止两张表中存在重名的列名。查询的时候,如果表中有重复的列名,应该在列名前面加上表名。
--查询语句的执行顺序:select* from PhoneNum;执行顺序是:先执行from子句,在执行select子句
SELECT *
FROM dbo.PhoneNum
INNER JOIN dbo.PhotoType ON PhoneNum.pTypeId = PhotoType.ptId;
SELECT PhoneNum.pId ,
PhoneNum.pName ,
PhoneNum.pCellPhone ,
pHomePhone ,
ptName
FROM dbo.PhoneNum
INNER JOIN dbo.PhotoType ON PhoneNum.pTypeId = PhotoType.ptId;
--查询的时候,为表起一个别名。
SELECT pn.pId ,
pn.pName ,
pn.pCellPhone ,
pHomePhone ,
ptName
FROM dbo.PhoneNum AS pn
INNER JOIN dbo.PhotoType ON pn.pTypeId = PhotoType.ptId; //使用内连接查询数据
List list= new List();
string sql = "SELECT pn.pId,pn.pName,pn.pCellPhone,pHomePhone, ptName FROM dbo.PhoneNum AS pn INNER JOIN dbo.PhotoType on pn.pTypeId = PhotoType.ptId";
SqlDataReader reader = SqlHelper.ExecuteReader(sql);
if (reader.HasRows)
{
while (reader.Read())
{
//创建一个对象
PhoneNumber phoneNumber = new PhoneNumber();
phoneNumber.PID = reader.GetInt32(0);
phoneNumber.PName = reader.GetString(1);
phoneNumber.PCellPhone= reader.GetInt32(2);
phoneNumber.PHomePhone= reader.GetInt32(3);
//另一个表中的参数
phoneNumber.PTypeID = new PhoneType();
phoneNumber.PTypeID.PtName = reader.GetString(4);
list.Add(phoneNumber);
Console.WriteLine(phoneNumber.ToString());
}
}
Console.WriteLine("成功遍历");
Console.ReadKey(); 三:使用带参数的SQL语句向数据库中插入空值
//使用带参数的sql语句向数据库中插入空值。
string sql = "insert into Teacher values(@TeaName,@TeaGender,@TeaAge,@TeaBirthdat,@TeaAddress,@TeaEmail,@TeaSalary);";
//SqlDbType 数据库中的数据类型
SqlParameter[] pms = new SqlParameter[] {
new SqlParameter("@TeaName",System.Data.SqlDbType.NVarChar,50) {Value="红尘" },
new SqlParameter("@TeaGender",System.Data.SqlDbType.Bit) {Value=1},
new SqlParameter("@TeaAge", System.Data.SqlDbType.Int, 50) { Value = 25 },
new SqlParameter("@TeaBirthdat", System.Data.SqlDbType.DateTime) {Value=DateTime.Now },
//向数据库中插入空值:不能给C#中的空值null,要给数据库中的空值,必须使用DBNull.Value。
//Value=(height==null?DBNull.Value:(Object)height)
new SqlParameter("@TeaAddress",System.Data.SqlDbType.NVarChar,50) { Value=DBNull.Value},
new SqlParameter("@TeaEmail",System.Data.SqlDbType.NVarChar,50) {Value="" },
new SqlParameter("@TeaSalary",System.Data.SqlDbType.Int) {Value=111111 },
};
int row = SqlHelper.ExecuteNonQuery(sql, pms);
if (row > 0)
{
Console.WriteLine("插入成功!");
}
else
{
Console.WriteLine("插入失败!");
}
Console.ReadKey();四:可空值类型
五:使用带参数的SQL语句中的一个问题
//使用带参数的sql语句存在的一个问题:最好不要这样写。
//new SqlParameter("@TeaAge", 0),0类型不确定 推荐第二种写法。六:case查询
--case函数的用法:相当于c#中的if——else
--逻辑语句 并且 使用 and关键字
--相当于switch语句
SELECT '头衔' = CASE WHEN TeaSalary < 2000 THEN '菜鸟老师'
WHEN ( TeaSalary > 2000 )
AND ( TeaSalary < 30000 ) THEN '骨干老师'
ELSE '特级教师'
END
FROM Teacher;
SELECT *
FROM dbo.Teacher;
--案例:表中有abc三列,CASE WHEN THEN END 关键字的使用
INSERT INTO ABC
VALUES ( 20, 20, 20 );
SELECT *
FROM ABC;
SELECT X = CASE WHEN A > b THEN A
ELSE B
END ,
Y = CASE WHEN b > C THEN B
ELSE C
END
FROM ABC;
--统计每个销售员的总金额: 销售员列和总金额列,group 按照销售员进行分组。让你查询什么,先把列名写出来。
--先把大致框架写出来,在慢慢填充内容
--数据透视 横表转纵表
SELECT *
FROM Teacher;

七: 索引
索引的分类:
聚集索引(物理):一个表中只能有一个聚集索引。
非聚集索引(逻辑):一个表中可以有许多非聚集索引。
2)索引意味着排序,排序后则可更高效的查询。无索引的表就是一个无序的行集。
3)当为某列简历唯一索引后,这列的数据就不能有重复。
4)对某一列建立索引,如何对某一列建立索引呢: 创建聚集索引 索引名称 在哪张表的哪一列简历索引:create clustered index IXc4 on TestIndex1002(c4)
5)表下面是有索引结点的:
6)右键单击索引名称,可以直接删除索引。
7)查询条件在哪一列,就在那一列建索引;索引一般配合where条件使用。
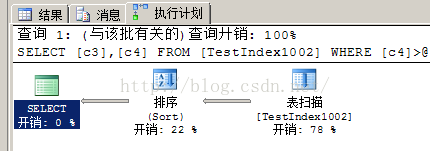
8)如果某一列建了聚集索引,但是查询条件不在这一列上,那么建立索引对性能提高不大。 聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。(相似的数据在物理存储上相邻,索引内部对列按照某种规则进行排序)
9)当索引值唯一时,使用聚集索引查找特定的行也很有效率。
10)建立索引是需要时间的,需要对表中的记录进行排序。
如何建立索引?工具--->数据库引擎优化顾问 (一定要学会建立索引) 选择要优化的数据库和表 . %aa这种写法用不到索引,aa%这种写法用到索引。
主键列自动是物理索引,其他列建立非聚集索引。
索引:index
1)全表扫描:对数据进行检索(select)效率最差的是全表扫表,及时一条一条的找。如果没有目录,查汉语字典就要一页一页的找;而有了目录只要查询目录即可。为了提高检索效率(查询速度),可以为经常进行检索的列添加索引,相当于创建目录。
2)创建索引的方式,在表设计器中点击,选择“索引/键”--->添加--->在列中选择索引包含的列。
3)使用索引能够提高查询效率,但是索引也是占用空间的,而且添加、更新、删除数据的时候也需要同步更新索引,因此会降低插入、更新、删除的效率,。只在经常检索的字段上(where)创建索引。
4)(*)即使创建了索引,仍然有可能全表扫描,比如 like(配合通配符使用 where column like a%)、函数、类型转换等
5)如何删除索引 drop index 表名.索引名 创建索引
八:子查询
1)把一个查询的结果在另一个查询中使用就叫子查询(将一个查询语句作为一个结果集供其他sql语句使用)
2) 子查询的分类———> 独立子查询:子查询可以独立运行。相关子查询:子查询中引用了父查询的结果(两个查询相互关联)。所有的子查询都可以使用相关子查询来实现。相关子查询与独立子查询:子查询语句是否可以独立运行。
select * from (select col1,col2 from tab) as t; 给查询结果起一个别名。 这就是一个独立子查询。
3) in、exists、not in、not exists; exists:如果查到了数据,就返回当前记录.
4)被当做结果集的查询语句被称为子查询。子查询一般在多张表中进行查询,满足多个条件的记录才进行返回。
5)所有可以使用表的地方几乎都可以使用子查询来代替 select * from (select * from Student where sAge > 30) as t;
6)重做Union all中的一道习题:要求在一个表格中查询出学生英语最高成绩、最底成绩、平均成绩。
select (select max(english) from score),(select min(english) from score),(select avg(english) from score) from score;
7)如果想把一个查询的结果集当做另一个查询的数据源,必须给它起一个别名。
子查询返回的值,不止一个。
子查询一般括起来。
select * from Teacher where 1=1;//当条件成立时,把当前行的记录读取出来
查询出所有满足条件的记录。
只有返回且仅返回一行、一列数据的子查询才能当做单值子查询。下面的做法是错误的 select 1 as f1,2 as f2,(select * from Teacher) as f3。 查询结果为一列,和一张表 组合不到一起的。
= 表示是否相等,只能和一个值进行比较。
select * from Teacher where classID =(select classID from Salary); 错
select * from Teacher where classID in (select classID from Salary); 对
九:分页查询(数据库中分页的实现)
1)使用子查询来实现分页,
每页五条数据,查询第四页的数据。
限制结果集
--使用top实现分页:效率不算太高
--遇到分页,一定要先想到排序。
--每页显示3条记录
SELECT *
FROM Teacher
ORDER BY TeaID ASC;
--查询第一页的数据
SELECT TOP 7
*
FROM dbo.Teacher
ORDER BY TeaID ASC;
--查询第二页的数据
SELECT TOP ( 7 * 2 )
*
FROM dbo.Teacher
ORDER BY TeaID ASC;
--思路:把已经看过的第几页id查询出来,比如你要看第二页,那就先查询出第一页的数据的 TeaAge;
SELECT TOP ( 3 * ( 2 - 1 ) )
*
FROM dbo.Teacher
ORDER BY TeaID ASC;
--使用了独立子查询
SELECT TOP 3
*
FROM Teacher
WHERE TeaID NOT IN ( SELECT TOP ( 3 * ( 2 - 1 ) )
TeaID
FROM dbo.Teacher
ORDER BY TeaID ASC )
ORDER BY TeaID ASC;
SELECT TOP 3
*
FROM Teacher
WHERE TeaID NOT IN ( SELECT TOP ( 3 * ( 3 - 1 ) )
TeaID
FROM dbo.Teacher
ORDER BY TeaID ASC )
ORDER BY TeaID ASC;2)使用ROW_NUMBER实现分页查询
要分页查询或分页显示,首先要确定按照什么排序,然后才能确定哪些记录应该在第一页,哪些记录应该在第二页?
使用row_number()实现分页:首先进行排序,对每行记录进行编号。然后根据用户每页要查看的记录以及要查看第几页的记录,确定应该查询第几条到第几条的数据。
--1、先编号再进行查询
SELECT * ,
rn = ROW_NUMBER() OVER ( ORDER BY TeaID ASC )
FROM Teacher
ORDER BY TeaID ASC;
--2、按照指定的规则进行编号。每页显示3条数据 查看第三页的数据。
SELECT * FROM
( SELECT * ,rn = ROW_NUMBER() OVER ( ORDER BY TeaID ASC ) FROM Teacher)
AS T
WHERE T.rn BETWEEN (3-1)*3+1 AND 3*3;十:区分几个概念
预读取 物理读取 逻辑读取
Sql Server存取数据都是以页为单位的(每页总大小为8kb)
逻辑读取:从缓存中读取数据显示出来
物理读取:从磁盘上读取数据到内存
预读取:一种性能优化机制,在执行查询时先预测执行“查询计划”所需要的数据和索引页,然后在查询实际使用这些
页之前将它们读入到缓冲区高速缓存。