Spring batch 的高级特性--监听,异常处理,事务
导 言
Spring batch是在Accenture(埃森哲)公司的批处理体系框架的基础上,再由SpringSource团队(原Interface21公司)大量参考和优化后所得的Java批处理产品。spring batch让java大数据批处理的标准化变得更好更容易。
本技术文档会以spring batch目前新稳定版本(2017年初的新稳定版本为V3.0.7)为基础,重点介绍spring batch的高级特性,并且都是以最新的规范使用注解来配置。

1 Spring batch的基本概念和配置
1.1 Spring batch的基本组件
在使用Spring batch的时候,需要用到一些类和接口以及组件等,这里给出简单的介绍:
| 名 称 | 用 途 |
| JobRepository | 用于注册和存储Job的容器 |
| JobLauncher | 用于启动Job |
| Job | 实际要执行的作业,包含一个或多个step |
| step | 步骤,批处理的步骤一般包含ItemReader, ItemProcessor, ItemWriter |
| ItemReader | 从给定的数据源读取item |
| ItemProcessor | 在item写入数据源之前进行数据整理 |
| ItemWriter | 把Chunk中包含的item写入数据源。 |
| Chunk | 数据块,给定数量的item集合,让item进行多次读和处理,当满足一定数量的时候再一次写入 |
| TaskLet | 子任务表, step的一个事务过程,包含重复执行,同步/异步规则等。 |
1.2 Job的实例定义,以及各个组件间的关系
1,Job的实例是Job的具体化,即作业,是由JobName + JobParameters来确定唯一,如果JobName和JobParameters相同,则定义为同一个Job实例。
2,相同的作业只能成功运行一次,如果需要再次运行,则需要改变JobParameters。
3,Job是由一个或者多个step组成,一般的,每个step由一组ItemReader-ItemProcessor-ItemWriter组成。 将这些概念图形化可以得到下面的几张图:

Job 实例示意图
------------------------------------------------------------------------------------------
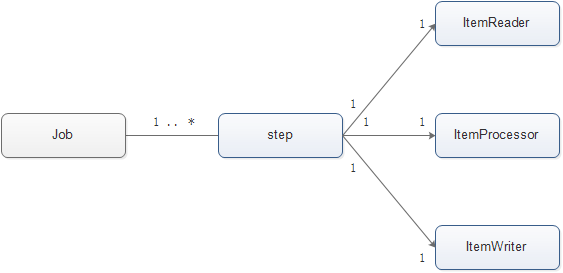
Job与step的关系图
-------------------------------------------------------------------------------------------

step内部结构关系图
1.2 spring batch的配置
在Spring boot架构下的项目,引入Spring batch非常简单,直接在pom.xml文件中,加入以下的依赖即可,参考配置如下:
org.springframework.boot
spring-boot-starter-batch
Spring boot会自动为我们初始化spring batch的数据库和数据表。当我们程序启动的时候,spring batch的job会持久化到数据库中。
如果需要修改spring boot为我们而设置的默认配置,可以前往application.yaml文件中,加入下面的配置,参考配置如下:
spring:
batch:
table-prefix: #这里是设置spring batch数据库表的前缀
initializer:
enabled: true #这里是允许自动初始化spring batch的数据库
job:
enabled: false #这里是设置不会自动先执行一次定义的job
1.3 Spring batch中的job的配置
新版本的Spring一直提倡“约定优于配置”的观点,所以对于以前xml形式的配置,都大部分改为了注解,Spring batch的新版本也一样,许多配置都可以通过注解进行。Spring batch用到的注解除了@Bean、@Service、@Component外,还有@StepScope、@BeforeJob、@AfterJob等注解。
以下是一个简单的Spring Batch Job的配置参考代码:
@Configuration
@EnableBatchProcessing
public class BatchConfig {
@Autowired
private GlobalStepValueMap globalStepValueMap;
@Autowired
private MessageService messageService;
@Autowired
private RedisService redisService;
@Autowired
private ApplicationService applicationService;
@Bean
public JobRepository jobRepository(DataSource dataSource,PlatformTransactionManager transactionManager) throws Exception{
JobRepositoryFactoryBean jobRepositoryFactoryBean = new JobRepositoryFactoryBean();
jobRepositoryFactoryBean.setDataSource(dataSource);
jobRepositoryFactoryBean.setTransactionManager(transactionManager);
jobRepositoryFactoryBean.setDatabaseType("MYSQL");
return jobRepositoryFactoryBean.getObject();
}
@Bean
public SimpleJobLauncher jobLauncher(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception{
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository(dataSource, transactionManager));
System.out.println(">>>>>>>>>>" + transactionManager.getClass());
return jobLauncher;
}
//------ ItemReader, ItemProcessor, ItemWriter ------
//读数据
@Bean
@StepScope
public ListItemReader firstStepReader(@Value("#{jobParameters['request']}") String request) throws UnexpectedInputException, ParseException, NonTransientResourceException, Exception {
System.out.println("------1st step Reader--------");
......
List listMsgCfgBean = new ArrayList();
listMsgCfgBean.add(newMsgConfigBean);
ListItemReader reader = new ListItemReader(listMsgCfgBean);
return reader;
}
@Bean
@StepScope
public ListItemReader secondStepReader(@Value("#{jobParameters['request']}") String request) throws UnexpectedInputException, ParseException, NonTransientResourceException, Exception {
System.out.println("------2nd step Reader--------");
......
ListItemReader reader = new ListItemReader(listAudiences);
return reader;
}
//处理数据
@Bean
@StepScope
public MsgCfgToMsgModelItemProcessor firstStepProcessor(@Value("#{jobParameters['request']}") String request) throws JsonParseException, JsonMappingException, IOException {
System.out.println("------1st step Processor--------");
......
MsgCfgToMsgModelItemProcessor m2mProcessor = new MsgCfgToMsgModelItemProcessor();
m2mProcessor.setJobId(requestModel.getJob());
return m2mProcessor;
}
@Bean
@StepScope
public ItemProcessor secondStepProcessor(@Value("#{jobParameters['request']}") String request) throws JsonParseException, JsonMappingException, IOException {
System.out.println("------2nd step Processor--------");
return new AliasesToFullMsgModelItemProcessor();
}
//写数据
@Bean
@StepScope
public ItemWriter firstStepItemWriter(@Value("#{jobParameters['request']}") String request) throws JsonParseException, JsonMappingException, IOException {
System.out.println("------1st step writer--------");
......
MessageFullSetItemWriter writer = new MessageFullSetItemWriter();
writer.setRequestJobId(requestModel.getJob());
return writer;
}
@Bean
@StepScope
public ItemWriter secondStepItemWriter(@Value("#{jobParameters['request']}") String request) throws JsonParseException, JsonMappingException, IOException {
System.out.println("------2nd step writer--------");
......
MQChannelModelItemWriter writer = new MQChannelModelItemWriter();
return writer;
}
//--------------- job & step ----------------
@Bean
public Job messageCoreBatch(JobBuilderFactory jobs, @Qualifier("step1")Step firstStep, @Qualifier("step2")Step secondStep, JobExecutionListener listener) {
return jobs.get("messageCoreBatch")
.incrementer(new RunIdIncrementer())
.listener(listener)
.start(firstStep).next(secondStep)
.build();
}
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory, @Qualifier("firstStepReader")ListItemReader reader,
@Qualifier("firstStepItemWriter")ItemWriter writer, @Qualifier("firstStepProcessor")ItemProcessor processor, StepListener stepListener) {
return stepBuilderFactory.get("step1")
. chunk(100)
.reader(reader)
.processor(processor)
.writer(writer).listener(stepListener)
.build();
}
@Bean
public Step step2(StepBuilderFactory stepBuilderFactory, @Qualifier("secondStepReader")ListItemReader reader,
@Qualifier("secondStepItemWriter")ItemWriter writer, @Qualifier("secondStepProcessor")ItemProcessor processor) {
return stepBuilderFactory.get("step2")
. chunk(300)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public static JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}
代码的具体意思会在后面的章节介绍。
通过查阅上面的代码可以看出,对于各个组件的定义,通过@Bean注解,Spring就可以将其自动生成Spring batch的相关配置项,等待其他程序的使用。其中@StepScope是说明该注解下的组件实行后绑定技术,即生成step的时候,才进行该注解下Bean的生成,这时候再进行参数的绑定,JobParameters也在这个时候才传入。
2 Spring batch的监听机制
2.1 Spring batch监听器的简介
Spring batch有如下几个监听器:
1)JobExecutionListener
2)StepExecutionListener
3)ChunkListener
4)ItemReadeListener
5)ItemProcessListener
6)ItemWriteListener
7)SkipListener
1~6中的每一种粒度的listener都有着对应于该粒度的before和after监听方法。例如StepExecutionListener有beforeStep()和afterStep()监听方法,分别用于监听step启动前和step运行后的那一时刻。对于4~6中,还额外有对应的onReadError(), onProcessError(), onWriteError()监听方法。
而剩下的SkipListener则对应着有onSkipInRead(), onSkipInProcess(), onSkipInWrite()三种监听方法。
2.2 创建Spring batch的监听器
由于Spring batch的监听器有许多种,但创建方法都十分相似,所以这里只以StepExecutionListener为例子,来建立Step粒度的监听器。
创建自己的StepExecutionListener的方法,主要有实现StepExecutionListener接口,以及使用StepListener粒度的注解这两种方法。由于实现接口的方式,需要把所有的接口内的方法都需要实现一遍,不太灵活,所以使用注解的方法建立监听器,会比较容易,即我们想使用哪一个监听器的监听方法,就在我们的逻辑方法上面,加上该监听器方法对应的注解即可。
下面是两种创建方法的比较,参考代码如下:
implements 接口方式:
public class NewStepListener implements StepExecutionListener {
@Override
public void beforeStep(StepExecution stepExecution) {
// 写入自己的beforeStep逻辑
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
// 写入自己的afterStep逻辑
return null;
}
}
使用注解方式:
@Component
public class NewStepListener {
@BeforeStep
public void testBeforeStep(){
// 写入自己的beforeStep逻辑
}
@AfterStep
public void testBeforeRead(){
// 写入自己的afterStep逻辑
}
}
我们甚至可以只使用一个Class文件,把多种不同粒度的注解写入,这样就可以一个class监听器包含了多种监听器的多个监听方法。参考代码:
public class NewStepListener{
@BeforeStep
public void beforeStep() {
// 写入自己的beforeStep逻辑
}
@BeforeRead
public void afterStep() {
// 写入自己的BeforeRead逻辑
}
@OnSkipInRead
public void onSkipInRead(Throwable t) {
// 写入自己的SkipInRead逻辑
}
@OnSkipInWrite
public void onSkipInWrite(Object item, Throwable t) {
// 写入自己的SkipInWrite逻辑
}
@BeforeWrite
public void beforeWrite(List items) {
// 写入自己的BeforeWrite逻辑
}
@AfterWrite
public void afterWrite(List items) {
// 写入自己的AfterWrite逻辑
}
@OnWriteError
public void onWriteError(Exception exception, List items) {
// 写入自己的OnWriteError逻辑
}
}
上面这个监听器包含了多种粒度下的不同的监听方法。
2.3 为Spring batch的job加入监听器
不同粒度的监听器,需要放入不同位置。一般我们在配置Spring batch的job和step的时候将监听器放入。
例如job粒度的监听器,是在spring batch的class配置文件BatchConfig中,配置job时放入,参考代码如下:
jobs.get("messageCoreBatch")
.incrementer(new RunIdIncrementer())
.listener(newJoblistener)
.start(firstStep).next(secondStep)
.build();
而对于step或者step以内的粒度的监听器,在配置的时候,可以放到Step中,参考代码如下:
stepBuilderFactory.get("step1")
. chunk(1)
.reader(reader)
.processor(processor)
.writer(writer).listener(newStepListener)
.build();
3 Spring batch的事务处理机制
3.1 Spring batch的事务简介
Spring batch的事务有如下的特点:
1)step之间事务独立。
2、step划分成多个chunk执行,chunk事务彼此独立,互不影响。
3)chunk定义,例如有chunk(N),即读取N条数据作为一个chunk,chunk开始开启一个事务,正常结束提交。
4)事务提交条件:chunk执行正常,未抛RuntimeExecption。
5)默认情况下,Reader、Processor、Writer抛出未捕获RuntimeException,当前chunk事务回滚,step失败,job失败。
6)Spring batch 可以设置retryLimit,即重试次数。如果重试达了指定次数,或者重试策略不满足时,step失败,job失败。
7)Spring batch 可以设置skipLimit,即跳过次数。如果Spring batch 同时设置了retryLimit和skipLimit,则,当retryLimit次数达到后,则进行skip操作。如果重试次数达了指定次数,到或者重试策略不满足时,step失败,job失败。
这些概念可以图形化为下面这几张图:
step中的事务示意图:

监听器组件的事务示意图:

3.2 Spring batch的事务配置
Spring的事务配置方法一般为:
1)先配置好相关的事务管理器。
2)用注解 @EnableTransactionManagement 开启事务支持。
3)在访问数据库的Service方法上添加注解 @Transactional并指定事务管理器。
而Spring batch的事务配置也与之相同,除此之外,还可以在Job仓库和JobLauncher配置中,直接指定好事务管理器,从而省略2~3的步骤。
我们可以在spring batch的class配置文件BatchConfig中,配置相关的事务管理器,参考代码如下:
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
或者
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityMngFactory) {
return new JpaTransactionManager(entityMngFactory);
}
上面的代码分别是两种事务管理器,DataSourceTransactionManager 以及 JpaTransactionManager 。其中DataSourceTransactionManager针对的是JDBC资源的事务管理;JpaTransactionManager针对的是JPA资源的事务管理。如果我们不进行配置,则Spring batch会查找相关配置,自动加入这两个事务管理器中的其中一个。但其实除了这两种事务管理器外,Spring还有其他的几种事务管理器,所以最好显式配置。
还是在spring batch的class配置文件BatchConfig中,我们在下面的两个方法中,分别将事务管理器加入到JobRepository和JobLauncher中。参考代码如下:
@Bean
public JobRepository jobRepository(DataSource dataSource,PlatformTransactionManager transactionManager) throws Exception{
JobRepositoryFactoryBean jobRepositoryFactoryBean = new JobRepositoryFactoryBean();
jobRepositoryFactoryBean.setDataSource(dataSource);
jobRepositoryFactoryBean.setTransactionManager(transactionManager);
jobRepositoryFactoryBean.setDatabaseType("MYSQL");
return jobRepositoryFactoryBean.getObject();
}
@Bean
public SimpleJobLauncher jobLauncher(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception{
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository(dataSource, transactionManager));
return jobLauncher;
}
3.3 Spring batch事务的使用
上一节中,我们已经配置好Spring batch的事务,结合3.1节中我们的介绍可以知道,Step中的chunk,以及chunk中的reader,processor,writer都是开启了事务的。也就是说我们只要再在spring batch的class配置文件BatchConfig中,配置好相关的step以及step的内部组件,那么这些step的组件就会受到事务管理器的管理。
重新打开BatchConfig文件,写入相关的step组件,参考代码如下:
@Configuration
@EnableBatchProcessing
public class BatchConfig {
@Bean
public JobRepository jobRepository(DataSource dataSource,PlatformTransactionManager transactionManager) throws Exception{
JobRepositoryFactoryBean jobRepositoryFactoryBean = new JobRepositoryFactoryBean();
jobRepositoryFactoryBean.setDataSource(dataSource);
jobRepositoryFactoryBean.setTransactionManager(transactionManager);
jobRepositoryFactoryBean.setDatabaseType("MYSQL");
return jobRepositoryFactoryBean.getObject();
}
@Bean
public SimpleJobLauncher jobLauncher(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception{
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository(dataSource, transactionManager));
System.out.println(">>>>>>>>>>" + transactionManager.getClass());
return jobLauncher;
}
......
//读数据
@Bean
@StepScope
public ListItemReader stepForTranscationReader() throws UnexpectedInputException, ParseException, NonTransientResourceException, Exception {
System.out.println("------tx step Reader--------");
List indexVals = new ArrayList();
indexVals.add("001");
indexVals.add("002");
indexVals.add("003");
indexVals.add("004");
indexVals.add("005");
indexVals.add("006");
indexVals.add("007");
indexVals.add("008008008008");
indexVals.add("009");
indexVals.add("010");
indexVals.add("011");
indexVals.add("012");
ListItemReader reader = new ListItemReader(indexVals);
return reader;
}
.......
//处理数据
@Bean
@StepScope
public ItemProcessor stepForTranscationProcessor() throws JsonParseException, JsonMappingException, IOException {
System.out.println("------tx step Processor--------");
return new StringToStringDoNotingProcessor();
}
......
//写数据
@Bean
@StepScope
public ItemWriter stepForTranscationWriter(JdbcTemplate jdbcTemplate) throws JsonParseException, JsonMappingException, IOException {
System.out.println("------tx step writer--------");
TestTableWriter writer = new TestTableWriter();
writer.setJdbcTemplate(jdbcTemplate);
return writer;
}
//---------------job & step----------------
......
@Bean
public Job testBatchTranscation(JobBuilderFactory jobs, @Qualifier("step1")Step firstStep, @Qualifier("step2")Step secondStep, @Qualifier("stepForTranscation")Step stepForTranscation, JobExecutionListener listener) {
return jobs.get("testBatchTranscation")
.incrementer(new RunIdIncrementer())
.listener(listener)
.start(stepForTranscation)
.build();
}
@Bean
public Step stepForTranscation(StepBuilderFactory stepBuilderFactory, @Qualifier("stepForTranscationReader")ListItemReader reader,
@Qualifier("stepForTranscationProcessor")ItemProcessor processor, @Qualifier("stepForTranscationWriter")ItemWriter writer) {
return stepBuilderFactory.get("stepForTranscation")
. chunk(3)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
......
//@Bean
//public PlatformTransactionManager transactionManager(DataSource dataSource) {
//return new DataSourceTransactionManager(dataSource);
//}
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityMngFactory) {
return new JpaTransactionManager(entityMngFactory);
}
// end::jobstep[]
@Bean
public static JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}
上面的这段代码中,其中有两个被引用的类的参考代码:
StringToStringDoNotingProcessor类:
public class StringToStringDoNotingProcessor implements ItemProcessor {
@Override
public String process(String item) throws Exception {
// TODO Auto-generated method stub
return item;
}
}
这个是一个模拟Processor的代码。一般的,Processor是对reader中的数据item进行处理,例如进行校验,格式转换或者运算等等,然后再把处理好的新数据item给到writer。但我们例子中为了化简了这一过程,直接不做任何事。
所以也将其起名为StringToStringDoNotingProcessor。
另一个TestTableWriter类:
public class TestTableWriter implements ItemWriter {
private JdbcTemplate jdbcTemplate;
public JdbcTemplate getJdbcTemplate() {
return jdbcTemplate;
}
public void setJdbcTemplate(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void write(List indexVals) throws Exception {
System.out.println("-------tx step writer--write()-------");
for(String tmpIndex : indexVals){
String key = "key_" + tmpIndex;
String value = "value_" + tmpIndex;
jdbcTemplate.update("insert into test_tbl values('" + key + "','" + value + "')");
}
}
}
这里我们是一个我们自己实现的wrtier,其中有一个write方法,进行对数据库的写处理。一般的我们设置了chunk的数值后,例如本例中我们设置了3,Spring batch会按这样的机制处理:每当累计有3条数据item到达writer后,会进行一次write()方法的调用,即写一次数据库。(若最后一次不足3条数据的时候,会进行最后一次写的操作把剩余数据item写入)
★其他代码讲解:
@Bean
public Step stepForTranscation(StepBuilderFactory stepBuilderFactory, @Qualifier("stepForTranscationReader")ListItemReader reader,
@Qualifier("stepForTranscationProcessor")ItemProcessor processor, @Qualifier("stepForTranscationWriter")ItemWriter writer) {
return stepBuilderFactory.get("stepForTranscation")
. chunk(3)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
这个代码是Spring batch配置代码中的一小部分,是定义一个step的过程。其中指定了选用的reader,processor,writer组件,以及chunk的大小。这里的chunk设置为3,即每3个数据item为一个chunk。
这里的step的例子,是以批处理读取数据,然后写入到一个test_tbl的表的过程。
其中,stepForTranscationReader中,我们设置了总共读取12条数据item,而step中设置的chunk条数是3,所以,实质上这12条数据item是分了4个chunk,每个chunk读和处理3条,然后将3条数据item一次写入数据库,这里的每个chunk都是一个独立的事务,如果在该step过程中出错了,则单独对当前出错的chunk进行回滚操作。
test_tbl的建表参考代码如下:
CREATE TABLE `test_tbl` (
`key` varchar(10) DEFAULT NULL,
`value` varchar(15) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
即该表只有两个字段,分别为key和value。而且key和value的大小分别为10和15个字符。
回到stepForTranscationReader中,我们设置的12条数据item中,第8条数据是超过了数据库表的限制的:
List indexVals = new ArrayList();
indexVals.add("001");
indexVals.add("002");
indexVals.add("003");
indexVals.add("004");
indexVals.add("005");
indexVals.add("006");
indexVals.add("007");
indexVals.add("008008008008");
indexVals.add("009");
indexVals.add("010");
indexVals.add("011");
indexVals.add("012");
这就是说,当我们使用Spring batch处理到第8条数据的时候,会报数据库异常。那我们运行一下程序,看看Spring batch的事务机制是如何处理的。
启动Spring boot以及Spring batch, 参考代码如下:
@SpringBootApplication(scanBasePackages={"com.ljp.spring.batchtest"})
@EnableConfigurationProperties
@EnableTransactionManagement
public class Starter {
public static void main(String[] args) throws JobExecutionAlreadyRunningException, org.springframework.batch.core.repository.JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException, SchedulerException, BeansException, JsonProcessingException, ParseException, InterruptedException{
ApplicationContext context = SpringApplication.run(Starter.class, args);
JobLauncher jobLauncher = (JobLauncher)context.getBean("jobLauncher");
SimpleJob testBatchJob = (SimpleJob) context.getBean("testBatchTranscation");
JobExecution execution = null;
try {
execution = jobLauncher.run(testBatchJob, new JobParametersBuilder().toJobParameters());
} catch (JobExecutionAlreadyRunningException | JobRestartException | JobInstanceAlreadyCompleteException
| JobParametersInvalidException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (org.springframework.batch.core.repository.JobRestartException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
结果如下: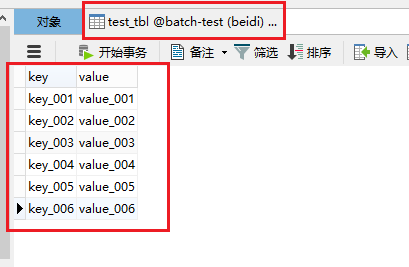
可以看出一共有6条数据写入了test_tbl表。
java后台的运行console有如下信息:
2017-05-08 17:50:21.973 INFO 324136 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=testBatchTranscation]] launched with the following parameters: [{}]
2017-05-08 17:50:22.108 INFO 324136 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [stepForTranscation]
------tx step Reader--------
------tx step Processor--------
------tx step writer--------
-------tx step writer--write()-------
-------tx step writer--write()-------
-------tx step writer--write()-------
2017-05-08 17:50:22.591 INFO 324136 --- [ main] o.s.b.f.xml.XmlBeanDefinitionReader : Loading XML bean definitions from class path resource [org/springframework/jdbc/support/sql-error-codes.xml]
2017-05-08 17:50:23.177 INFO 324136 --- [ main] o.s.jdbc.support.SQLErrorCodesFactory : SQLErrorCodes loaded: [DB2, Derby, H2, HSQL, Informix, MS-SQL, MySQL, Oracle, PostgreSQL, Sybase, Hana]
2017-05-08 17:50:23.286 ERROR 324136 --- [ main] o.s.batch.core.step.AbstractStep : Encountered an error executing step stepForTranscation in job testBatchTranscation
org.springframework.dao.DataIntegrityViolationException: StatementCallback; SQL [insert into test_tbl values('key_008008008008','value_008008008008')]; Data truncation: Data too long for column 'key' at row 1;
nested exception is com.mysql.jdbc.MysqlDataTruncation: Data truncation: Data too long for column 'key' at row 1
at org.springframework.jdbc.support.SQLStateSQLExceptionTranslator.doTranslate(SQLStateSQLExceptionTranslator.java:102) ~[spring-jdbc-4.3.4.RELEASE.jar:4.3.4.RELEASE]
......
......
2017-05-08 17:50:23.695 INFO 324136 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=testBatchTranscation]] completed with the following parameters: [{}] and the following status: [FAILED]
我们对结果的解读是:
数据库一共写入了6条记录,分别是Spring batch的step中的前两个chunk所为(每3个数据item为一个chunk)。然后到处理第3个chunk的时候,007,008008008008,009这3个数据item中,第2个数据item超出了数据库的限制长度,所以Java后台console显示会报出:“Data too long for column 'key' at row 1; ”的提示。由于每一个chunk我们都设置了事务,所以,这个chunk中,哪怕007数据是可以写入数据库的,但由于008008008008这条数据报错,所以导致整一个chunk进行回滚,而007数据也进行了回滚。另外由于每一个chunk的事务独立,所以第3个chunk回滚的事件不会影响到前两个chunk,所以001~006的6条数据item都能成功写入数据库。
此外,我们还可以去到数据库,查找Spring batch持久化的表,进行进一步的了解:
这里的数据库表,告诉我们,的确是发生了回滚。Spring batch总共commit了2次事务,分别有6条数据写入,对应了2个chunk。而总共读取了9条数据,即第3个chunk,但就在这时有数据错误,进行了回滚操作,整个step状态为FAILED。
3.4 Spring batch的容错机制
Spring batch的容错机制是一种与事务机制相结合的机制,它主要包括有3种操作:
1)restart
2)retry
3)skip
其中,restart是针对job来使用,retry和skip是针对step以及其内部组件来使用。
restart是重启job的一个操作。一般的,只有job是失败的情况下,才能restart。前面也说了,相同的作业只能成功运行一次,如果需要再次运行,则需要改变JobParameters。
retry是对job的某一step而言,处理一条数据item的时候发现有异常,则重试一次该数据item的step的操作。
skip是对job的某一个step而言,处理一条数据item的时候发现有异常,则跳过该数据item的step的操作。
我们来更改一下之前step的配置,参考代码如下:
@Bean
public Step stepForTranscation(StepBuilderFactory stepBuilderFactory, @Qualifier("stepForTranscationReader")ListItemReader reader,
@Qualifier("stepForTranscationProcessor")ItemProcessor processor, @Qualifier("stepForTranscationWriter")ItemWriter writer) {
return stepBuilderFactory.get("stepForTranscation")
. chunk(3)
.reader(reader)
.processor(processor)
.writer(writer).faultTolerant().retryLimit(3).retry(DataIntegrityViolationException.class).skipLimit(1).skip(DataIntegrityViolationException.class).startLimit(3)
.build();
}
这个新的step配置中,我们比之前多了一些配置项,如下:
.faultTolerant()
.retryLimit(3)
.retry(DataIntegrityViolationException.class)
.skipLimit(1)
.skip(DataIntegrityViolationException.class)
.startLimit(3)
这里就是retry,skip,restart的配置。
这里设置了允许重试的次数为3次,允许跳过的数据最多为1条,如果job失败了,运行重跑次数最多为3次。
我们重新运行程序,可以得到新的结果:
这次我们看到了,12条数据中总共有11条数据进入到数据库,而过长的008008008008数据,则因为设置了skip,所以容错机制允许它不进入数据库,这次的Spring batch最终没有因为回滚而中断。
我们查阅一下Spring batch的持久化数据表:
我们可以看出,的确是有一条数据被跳过了,但因为是我们允许它跳过的,所以整个job顺利完成,即COMPLETED。
参考文档
1,网文《全面解析spring batch大数据批处理框架》: http://mt.sohu.com/20161116/n473372684.shtml
2,网文《Spring batch的事务处理》: http://blog.csdn.net/karott/article/details/44154501
3,Spring batch 官网信息 : http://projects.spring.io/spring-batch/