作者 | Eugenio Culurciello
翻译 | AI科技大本营(rgznai100)
深度神经网络和深度学习是既强大又受欢迎的算法。这两种算法取得的成功主要归功于神经网络结构的巧妙设计。
我们来回顾一下,神经网络设计在过去几年以及在深度学习中的发展历程。
这篇文章对所有网络进行了一次更为深入的分析和比较,详情请阅读我们发表的文章:
https://arxiv.org/abs/1605.07678
这是文章中的一张具有代表性的图表,如下所示:
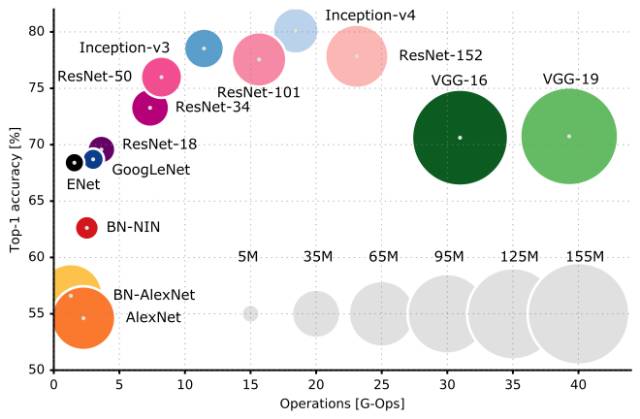
在多种受欢迎的神经网络结构中,大部分的操作需要进行一个简单的向前推算,从而得出单一的 Top-1 准确率。
LeNet5
LeNet5 网络于1994年问世,是最早的卷积神经网络之一,推动了深度学习领域的发展。自1988年起,在经过多次先前成功的迭代发展之后,扬·勒丘恩(Yann LeCun)开创性的研发出了 LeNet5 网络。

LeNet5 结构是非常基础的,特别是观察那些分布在整个图像上的图像特征时,其可以利用卷积神经网络中可学参数在多位置上利用少量参数有效地抽取相似特点。与此同时,这里没有 GPU 帮助训练,而且 CPUs 运行速度也非常缓慢。因此,LeNet5 最为重要的优势就是能够精简参数和计算。
这与把每个像素当做一个庞大多层神经网络的单独输入的理念完全相悖。LeNet5 结构表明,不应该在第一层中使用像素,因为图像与空间相关度非常高,所以把图像的单独像素作为单独输入特性将导致无法使用相关的图像。
LeNet5 结构特点如下:
卷积神经网络利用3个层式的序列:卷积,池以及非线性——根据这篇文章所讲述的内容,我们知道这可能就是深度学习中图像的关键特性;
利用卷积网络提取空间特征;
子样品利用空间平均地图;
tanh 和 signoids 函数的非线性特征;
多层神经网络(MLP)作为最终分类器;
在层式之间放置零星的连接矩阵来规避大量计算。
总体来说,LeNet5 结构不但是近代大部分神经网络结构的鼻祖,而且也极大地鼓舞着该领域的研究工作人员。
The gap
从1998年到2010年,这段时间神经网络处于蓄势待发的状态。因为许多其他领域研究人员的研究进展缓慢,所以大部分人没有留意神经网络的功能日益强大。由于手机相机和廉价数码相机的兴起,神经网络获得了越来越多的数据。同时,计算能力有所提高,CPU 运行速度加快,GPU 也成为了通用的计算工具。
Dan Ciresan Net
2010年,Dan Claudiu Ciresan 和 JurgenSchmidhuber 联合发布了其中一个最早问世的 GPU 神经网络实现。实现了在一个运行高达九层神经网络的 NVIDIA GTX 280 图形处理器中执行前向和后向推算的功能。
AlexNet
2012年,Alex Krizhevsky 发布了比 LeNet 网络功能更强大的 AlexNet 网络,并且 AlexNet 网络在高难度的 ImageNet 比赛中以绝对的优势获胜。
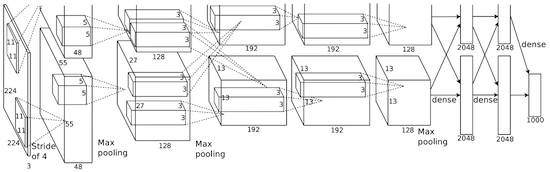
AlexNet 网络将 LeNet 网络改造成了一个更为庞大的神经网络,这样 AlexNet 网络就能够用于学习更为复杂的对象以及对象的层次结构。以下是 AlexNet 网络结构的贡献:
把被修正的线性单元(ReLU)当作非线性。
在进行训练时,利用 dropout 技术有选择性的忽略单个神经元,避免模型过度拟合。
叠加 max pooling,避免平均 pooling 的平均效应。
利用 GPUs(图形处理器) NVIDIA GTX 580 来缩短训练时间。
此时,GPU 所提供的内核数量远大于 CPU 并且将培训时间缩减成了原来的十分一,也就是说,此时我们可以使用更大的数据集和图像了。
AlexNet 网络的成功掀起了一场小型的革命。卷积神经网络成为“能解决现今有意义任务的大型神经网络”的新名称。如今,卷积神经网络是深度学习的研究主力。
Overfeat
2013年12月,Yann LeCun 在纽约大学实验室提出了 AlexNet 网络的衍生品 Overfeat 算法。本篇文章还建议学习之后经常在其它相同课题的文章中出现的边界盒。我觉得最好还是去学习分割对象而不是学习人工边界盒。
VGG
由牛津大学提出来的 VGG 网络是首款在每层卷积网络中使用比 3*3 还要小的过滤器的网络,而且还把它们组合成了一系列的卷积。
这看起来与 LeNet 网络利用大量的卷积捕捉图像中相似特征的原则相悖。过滤器开始变得越来越小,LeNet 网络想要避免越靠近 infamous1*1 卷积就越危险的情况,至少不能在在网络第一层中发生这种状况,所以只能替换掉 AlexNet 网络 9*9 或者 11*11 的过滤器。但是,VGG 网络的优势在于可以观察按照一定次序多重 3*3 的卷积来仿真诸如 5*5 和 7*7 这样更大的接受域的效果。在 Inception 和 ResNet 这样较新的网络结构中也会应用到这些想法。

VGG 网络利用多重 3*3 卷积层来呈现复杂的特性。请注意 VGG-E 模块 3、4、5 的数值分别是 256*256 和 512*512,在序列里多次使用 3*3 过滤器来提取更为复杂的特性以及这些特性的组合。实际上,这就像是利用3层获得了大的 512*512 分类器。这就是卷积!这显然是大量参数以及学习力共同作用的结果。但是训练这些网络非常困难,而且必须把这些网络分解成更小的神经网络,对他们进行逐层训练。这么做的原因就是缺少强力有效地办法来调整模型或者在某种程度上是对利用大量的参数来提高大量搜索空间的办法予以限制。
VGG 网络在许多层都使用了大特征尺寸,因此在运行期间,推断造成的损耗异常严重。如 Inception 瓶颈效应那样,减少特性的数量会缩减计算成本。
Network-in-network
Network-in-network(NiN)能够简便有效地观察利用 1*1 卷积给卷积层特性提供更强的组合力量。
NiN 结构在每个卷积后使用MLP空间层是为了在另一个层中更好的组合特性。旧事重提,有人可能想起 1*1 卷积与 LeNet 初始原则相悖,可是,实际上,这两种结构用更好的方式帮助组合卷积特性,单纯的堆积更多的卷积层是不可能完成这项任务的。这就是利用原生像素输入到下一层的不同之处。在这里,卷积之后,利用 1*1 卷积在特性图谱上进行空间性的组合特性,所以他们有效地使用了少量参数,分享了这些特性的所有像素!
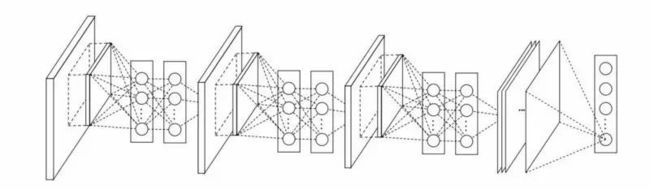
MLP 的性能通过把这些卷积特性组合成更为复杂的群组来大大的提高单个卷积特性的有效性。这一想法近期将会被应用在诸如 ResNet、Inception 以及相关衍生品的最新结构中。
NiN 还利用平均池化层(average pooling layer)作为最终分离器的一部分,另外一项活动就会变得普通。这样做是为了在分类之前使平均网络对输入的图片进行多路回应。
GoogLeNet 和 Inception
Google 公司的 Christian Szegedy 进行一项致力于减轻深度神经网络的计算负担研究,然后设计了首款名为 GoogLeNet 的 Inception 结构。
到2014年的秋天为止,深度学习模块分类在图像内容和视频帧方面表现的非常优异。大部分的怀疑者都已经承认,深度学习和神经网络的热潮已经回来了。如果了解这些技术所能发挥的作用,那么像 Goolge 这样的互联网巨头就会非常有兴趣在他们的服务器农场中大规模的部署这些有效地结构。
Christian 想出了许多既能保证运行的性能,又能减轻深度神经网络计算负担的方法(比如在 ImageNet 上)。又或者,在提升性能的同时保持计算成本不变。
Christian 和他的团队研究出了 inception 模块,如图所示:
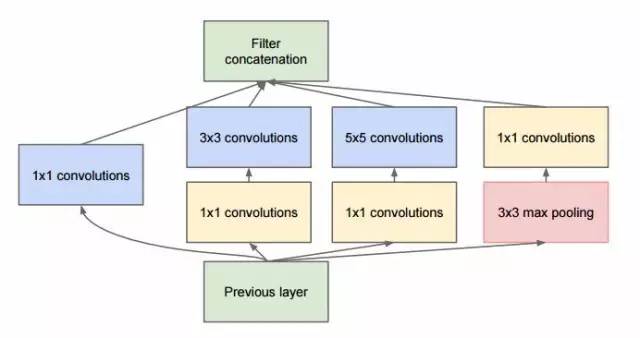
基本上,第一眼看到的就是平行组合的 1*1、3*3 以及 5*5 的卷积过滤器。但是 inception 模块的观察力杰出是因为在消耗平行块之前就已经利用了1*1卷积块(NiN)来减少特性的数量。我们通常将其称为“瓶颈”。这需要单独讲解:请阅读下面“瓶颈层”的相关内容。
Google 选取 stem 以及与 NiN 相似的平均池化(average pooling)和 softmax 分类器作为初始层,而未选用 inception 模块。与 AlexNet 和 VGG 中的分类器相比,softmax 分类器的操作数量非常低。这要归功于一个非常有效的网络设计。
Bottleneck layer(瓶颈层)
受到 NiN 网络的启发,Inception 的瓶颈层正在削减每一层的特性数量以及操作步骤,所以能够持续缩短推理时间。在还没有把数据传输到消耗卷积模块中的时候,特性的数量就锐减到了原来的 1/4。这就使得计算成本得以大幅度缩减,同时又推动了这种结构的成功。
让我们来仔细的检查一下。假设有256个特性输入,又有256个特性输出,而且 Inception 层只能运行3*3卷积。那么256*256*3*3卷积必须执行(使用乘法累加器或者 MAC 操作所得结果是589000s)。这可能就不只是计算负担的问题,需要在 Google 的服务器上以0.5毫秒的速度来运行这一个层。反其道行之,我们决定通过卷起这些特性的方法来消减其数量,也就是说256变成64。假若如此,我们首次运行256-> 64 1×1卷积后,Inception 的所有分支都是64个特性的卷积,然后我们再一次利用1*1卷积从64个特性变回到256个特性。操作过程如下:
256 × 64 × 1 × 1 = 16,000s
64 × 64 × 3 × 3 = 36,000s
64 × 256 × 1 × 1 = 16,000s
我们之前的计算成本约为 600,000,而现在只有 70,000!竟相差了近十倍!
虽然计算成本减少了,但是我们并没有丢弃这个层里的普遍性。事实上,瓶颈层已经被证明是执行 ImageNet 数据集中的先有技术,比如说,瓶颈层稍后也会应用在诸如 ResNet 这样的结构中。
成功的原因是输入的特性相互关联,而后通过利用 1*1 卷积来合理的组合特性从而清除冗余。然后,卷集成数量更少的特性以后,这些特性可以在下一层再次放大进行有意义的组合。
Inception V3 (and V2)
Christian 和其团队成员的研究效率非常高。2015年2月,Batchnormalized Inception被引进,称为 Inception V2。Batchnormalized Inception 负责计算平均值和每层输出中所有特征图谱的标准偏差,而且还规范化了数值之间的回应。这相当于“美化”数据,然后使所有的神经图反应一致,最后调到零均值。因为下一层不必学习输入数据中的偏移而且能够专注于如何形成最佳特性组合,所以这有助于训练。
2015年12月,他们发布了最新版的 Inception 模块和相关结构。这篇文章(网址:http://arxiv.org/abs/1512.00567)更好的解释了初始的 GoogleNet 结构,并且给出了许多设计选择方面更为详细的建议。初始想法列表:
最大化信息涌入网络,通过精心构建网络来保持深度和宽度的平衡。在构建pooling 之前,需要先增加特征图谱。
当深度加深,特性的数量或者层的宽度也会随之按一定规律增长。
在下一层之前,利用每层的宽度增长来提高特性的组合。
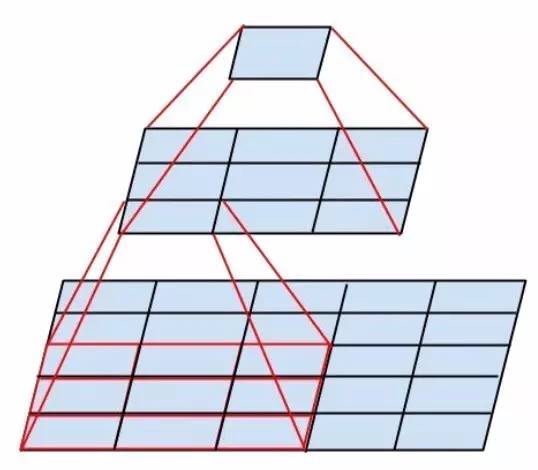
已知 5*5 和 7*7 的过滤器能用多层 3*3 分解,如果可以的话,只使用 3*3 卷积。请看下图:
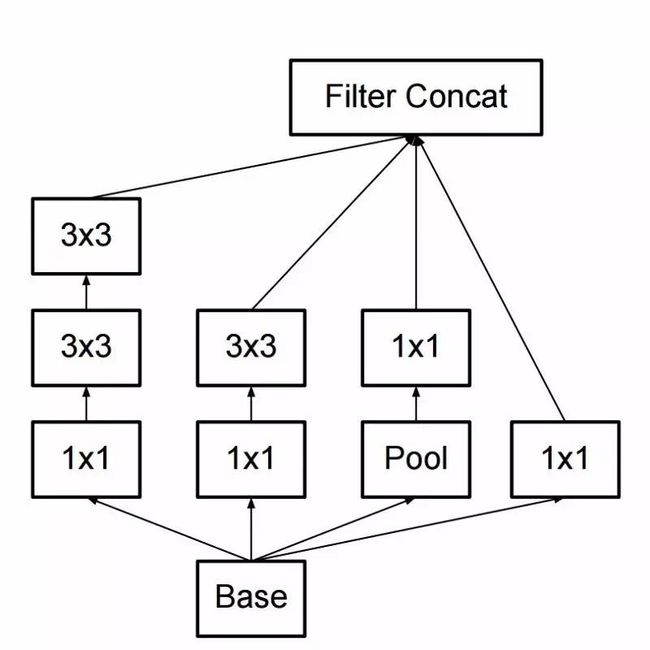
新版的inception模块是这样的,如图所示:
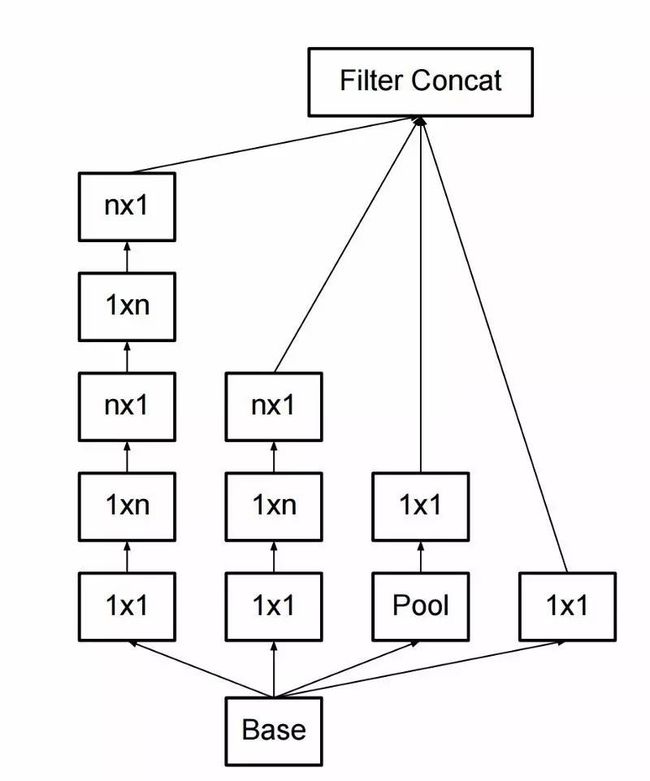
过滤器通过卷积压缩精简也能被分解进入更为复杂的模块,如图所示:
在运行inception计算时,通过支持poolinginception模块也能缩减数据的大小。这基本上与同时利用跨度和一个简单的pooling层运行卷积的原理相同,如图所示:
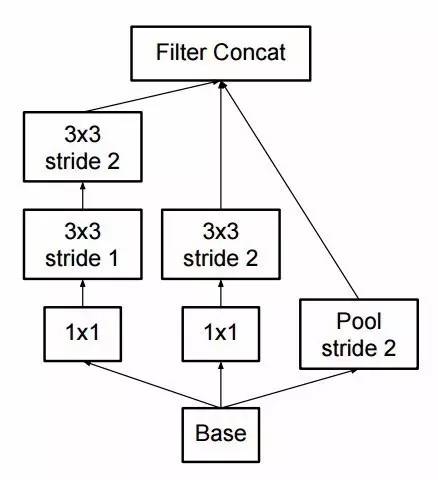
Inception 仍然使用 pooling 层和 softmax 作为其最终的分类器。
ResNet
2015年12月,一场革命悄然而至,Inception V3 也在此时问世。ResNet 有一个简单想法就是:同时供应两个连续的卷积层输出,同时绕开下一层的输入!

这是与这个相似的老想法,网址:
http://yann.lecun.com/exdb/publis/pdf/sermanet-ijcnn-11.pdf
但是,在这里,他们绕开两层并且被应用到大尺度上。因为绕开单层无法获得大幅度的提高,所以绕开两层就成了关键点。可以把这两层看作一个小的过滤器或者是一个网中网。
这是首次出现大于百层的网络,需要训练的层甚至达到了 1000 层。
拥有大量层的 ResNet 开始利用与 Inception 瓶颈相似的瓶颈层,如图所示:
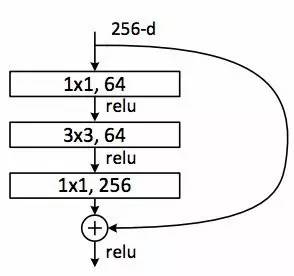
这种层消减特性数量就是在每层通过利用 1*1 卷积伴随着更小的输出(通常是1/4的输入),然后是一个 3*3 的层,接下来再用 1*1 卷积获得相对大量的特性。就像在 Inception 模块中,虽然支持丰富的特征组合,但是却保持了低的计算成本。看完过“GoogLeNet and Inception”这部分之后,请阅读“瓶颈层”。
ResNet 在输入时采用了一个相当简单的初始层(stem):一个7*7卷积层附带着一个标记为2的pool层。我们可以将其与更为复杂更为不直观的 Inception V3、 V4 做一下对比。
ResNet 还是利用一个 pooling 层外加 softmax 作为最终过滤器。
ResNet 结构每天都会有新的见解:
ResNet既可以被看做是平行模块也可以被看做是系列模块,这是因为很多进出的模块都是平行的,然而每个模块的输出都是串联的。
ResNet还可以被认为是平行或者连续模块的多种集成。
我们已经发现,ResNet经常可以在相对较低(大约20-30)的深度块上运行,运行的时候是平行的,而不是连续涌入贯穿整个网络。
当ResNet输出信息把消息反馈给输入信息时,如果在RNN中,那么网络可以被看作是更好的皮质生物仿真模块。
Inception V4
Christian 和他的团队在此基础上再次推出了新版的 Inception。
Inception 模块与 Inception V3 中的 stem 非常相似,如图所示:
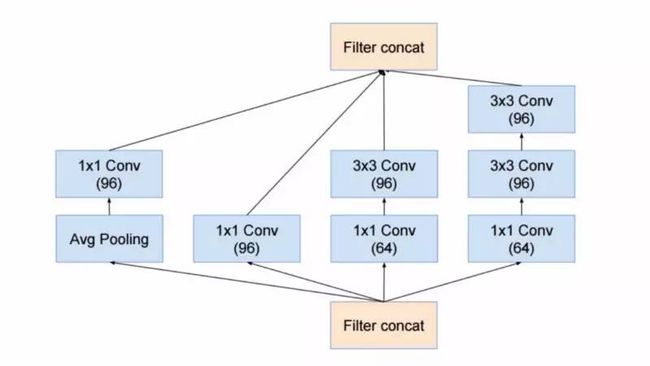
Christian 和他的团队还把 Inception 模块和 ResNet 模块组合在一起,如图所示:
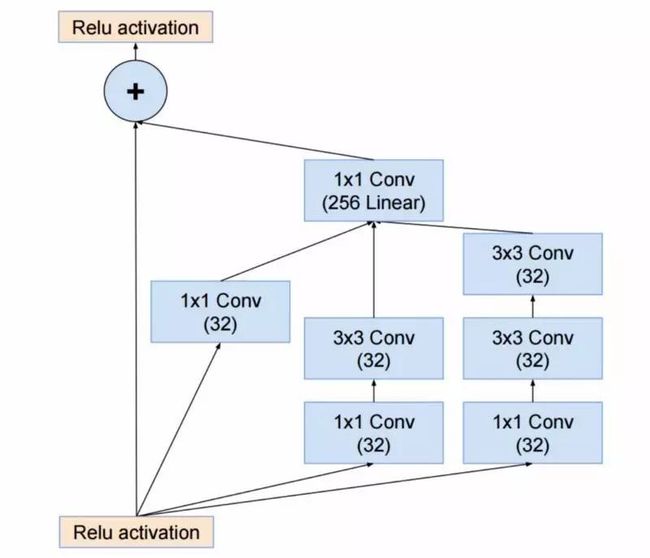
在我看来,Christian 和他的团队这次想出来的解决办法虽然不是那么前沿,反而会更加复杂些,但是却能减少使用试探法的次数。很难理解为何做出如此选择,而且研发者也很难对此做出判断。
就这一点而言,奖励应该颁发给像 ResNet 这样的清晰简单且易于理解和调整的网络。
SqueezeNet
近期发布了 SqueezeNet,它对 ResNet 和 Inception 的许多理念进行了优化。与此同时它也表明了,一个更好的结构设计无需复杂的压缩算法也能减少网络的尺寸和相关的参数。
ENet
我们团队打算把近期所有的结构特性整合成一个非常有效且轻质的网络,这个网络利用非常少的参数和计算就能够取得先前的技术成果。这款网络结构被命名为 ENet,它是由 Adam Paszke 设计的。我们已经利用该网络对图片添加标签并对情景进行分析。在这里你可以看到 ENet 中的一些视频正在运行(网址:https://www.youtube.com/watchv=3jq4FnO5Nco&list=PLNgy4gid0G9c4qiVBrERE_5v_b1pu-5pQ)。这些视频不是训练数据集的一部分。
这是 ENet 的技术报告,网址:
https://arxiv.org/abs/1606.02147
ENet 是由编码器和解码器组成的网络。编码器是为 CNN 分类设计的普通软件,但是解码器是上采样网为了把种类回传到分割的原图尺寸中而设计的。这项工作只用到了神经网络,无需使用其他的算法来执行图像分割。
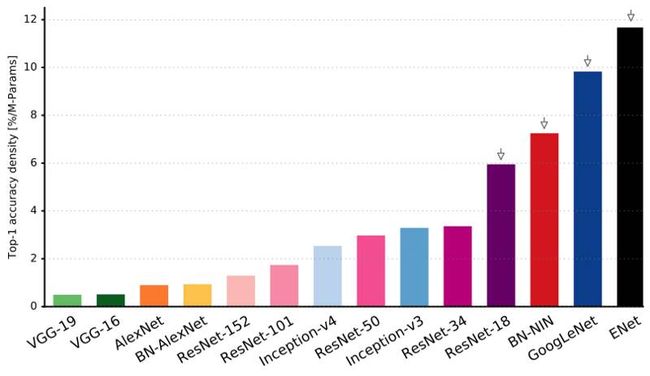
正如你在图表中看到的,ENet 的每个参数都具有极高的准确性,并没有使用任何其他的神经网络。
ENet 的设计初衷就是尽可能的减少资源的使用量。正如它取得的小小的成绩,编码和解码网络利用fp16精度同时运行只占用了0.7MB。
暂用空间如此小,ENet 与上述其他神经网络解决切分正确率的办法相似。
模块分析
CNN 的模块系统评估已经有结果了。发现使用的模块优势在于:
在不利用批量处理规范的情况下使用ELU的非线性特征,或者在利用批处理规范的同时使用ReLU。
应用RGB学习色彩转换。
利用线性学习率使规则衰退。
大量使用平均层和最高 pooling 层。
使用大约128或者256的 mini-batch。对于你的 GPU 来说,如果这个数据太大的话,可以适当地降低学习率以适应批的大小。
利用全层对最后决定的预测进行卷积和平均。
如果你不能增大输入图片的大小,那么减缓在顺向层中的跨度,这与上一条中所说的方法效果大致相同。
如果你的网络拥有诸如 GoolgeNet 这样既复杂又高度优化的结构,那么请注意小心地对待这些结构的变形。
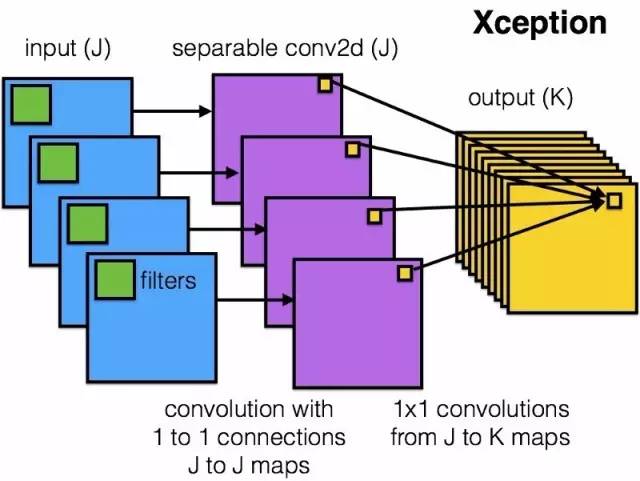
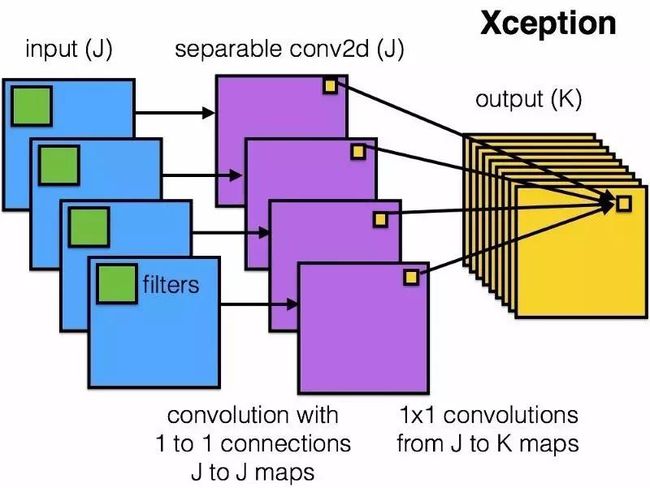
Xception
Xception 网络是利用一个像 ResNet 和 InceptionV4 网络这样既简单又更为优雅的结构对 inception 模块和结构进行优化而来。
Xception 模块,如图所示:
任何人都会喜欢这款具有简单优雅结构的网络,如图所示:
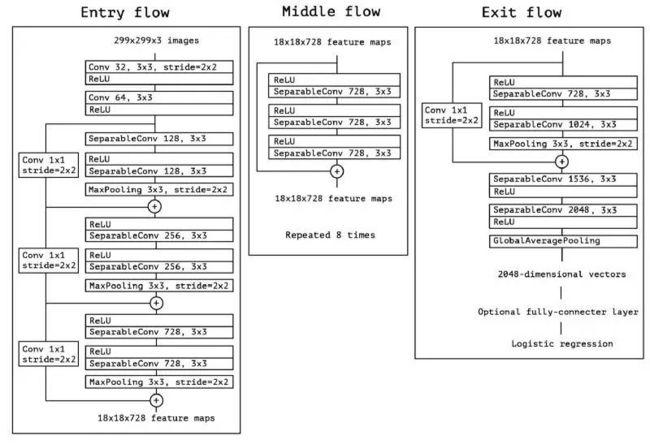
这个结构有36个卷积阶段,与 ResNet-34 非常相似。但是,其模块和代码跟 ResNet 一样简单,而且比 Inception V4 更易于理解。
Xception 网络能够实现 Torch7。也能实现 Keras 或者 TF。
有趣的是,新版 Xception 结构还是受到了我们所研究的分离卷积过滤器的启发。
其它著名的结构
FractalNet 网络利用了递归结构,可是其并未在 ImageNet 中进行测试,FractalNet 网络是 ResNet 网络的衍生品或者可以说是更为通用的 ResNet 网络。
未来
我们相信讲解神经网络机构对深度学习的发展至关重要。我们团队建议大家仔细阅读和理解这个帖子上所有的文章。
但是,现在大家可能会奇怪为什么我们花费这么多时间讲解结构,而没有利用数据告知大家如何选用这些网络以及如何组模型。这是一个循序渐进的过程,需要一步一步地进行。以上我在文章中向大家呈现的内容就是初期比较有趣的研究成功。
在这里大家还需要注意,我们主要讨论的是计算视角下的结构。这与源于其他领域的神经网络结构相似,而且学习其它任务的结构进化也是很有趣的。
本文作者Eugenio Culurciello在2004年,获得了约翰霍普金斯大学电气工程的博士学位,是威尔顿生物医学工程学院、电气与计算机工程学院和健康与人文科学学院的副教授。在2013年,Culurciello 博士创立了 TeraDeep ,一家专注于移动协处理器和神经网络硬件设计的公司。
原文地址:
https://medium.com/towards-data-science/neural-network-architectures-156e5bad51ba
