[Learning-from-data]无限假设空间的可学性以及模型泛化
Theory of Generalization
样本外误差 E o u t E_{out} Eout测量了训练集D上学习的模型在unseen data上的泛化能力. E o u t E_{out} Eout是基于整个输入空间X上的表现来测量的.如果使用样本集来计算模型的 E o u t E_{out} Eout,这些样本点必须是"unseen",没有在训练集中出现过.
对应的,样本内误差 E i n E_{in} Ein是基于训练集中的样本点,它评估模型在训练集上的表现.
Generalization error泛化误差. 泛化是学习中的一个关键问题.Generalization is a key issue in learning.泛化误差可以定义为 E i n E_{in} Ein和 E o u t E_{out} Eout两者之间的差异.Hoeffding不等式提供了一个泛化误差概率边界的描述.
P [ ∣ E i n ( g ) − E o u t ( g ) ∣ > ϵ ] ≤ 2 M e − 2 ϵ 2 N P[| E_{in}(g)-E_{out}(g)| > \epsilon] \leq 2Me^{-2\epsilon^2 N} P[∣Ein(g)−Eout(g)∣>ϵ]≤2Me−2ϵ2N for any ϵ > 0 \epsilon > 0 ϵ>0.
同时可以知道, ∣ E i n ( g ) − E o u t ( g ) ∣ ≤ ϵ |E_{in}(g)-E_{out}(g)| \leq \epsilon ∣Ein(g)−Eout(g)∣≤ϵ的概率为KaTeX parse error: Expected '}', got 'EOF' at end of input: …^{-2N\epsilon^2,也就是说 E o u t ( g ) ≤ E i n ( g ) + ϵ E_{out}(g) \leq E_{in}(g) + \epsilon Eout(g)≤Ein(g)+ϵ,选定一个tolerance δ \delta δ,所以 δ = 2 M e − 2 N ϵ 2 \delta = 2Me^{-2N\epsilon^2} δ=2Me−2Nϵ2, ϵ = 1 2 N l n 2 M δ \epsilon = \sqrt{\frac1{2N} ln\frac{2M}{\delta}} ϵ=2N1lnδ2M,最终,
E o u t ( g ) ≤ E i n ( g ) + 1 2 N l n 2 M δ E_{out}(g) \leq E_{in}(g) + \sqrt{\frac1{2N} ln\frac{2M}{\delta}} Eout(g)≤Ein(g)+2N1lnδ2M.
这个不等式提供了一个泛化边界.
∣ E i n − E o u t ∣ ≤ ϵ |E_{in}-E_{out}| \leq \epsilon ∣Ein−Eout∣≤ϵ,同时也保证对于所有的 h ∈ H h \in H h∈H来说, E o u t ≥ E i n − ϵ E_{out} \geq E_{in} - \epsilon Eout≥Ein−ϵ.对于最终的假设函数g既想让它在unseen data上表现良好,又想它是在所有假设集中做的最好的(H中不存在其他假设函数.使得 E o u t ( h ) E_{out}(h) Eout(h)比 E o u t ( g ) E_{out}(g) Eout(g)要好.). E o u t ( h ) ≥ E i n ( h ) + ϵ E_{out}(h) \geq E_{in}(h) + \epsilon Eout(h)≥Ein(h)+ϵ这个边界确保不能做的更好了,因为选择的其他假设h对应 E i n E_{in} Ein都比g要大,因此对应的 E o u t E_{out} Eout也要比g要大,样本外表现相对变差.
误差边界 1 2 N l n 2 M δ \sqrt{\frac1{2N} ln\frac{2M}{\delta}} 2N1lnδ2M依赖于假设空间H的大小M.如果H是无限集合,那么这个边界就没有意义了(边界趋向于无限大).不幸的是,实际情况下大多数学习模型都是无限集合.
为了在无限集合H上继续讨论模型的泛化能力,我们需要对上面的式子做一些变形,想用有限的数量去代替M,这样边界就有意义了.
之前右边界M对应:
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第1张图片](http://img.e-com-net.com/image/info8/20d80e5af0304c11adeafa87140421c2.jpg)
确保最终选择的函数g: ∣ E i n ( g ) − E o u t ( g ) ∣ > ϵ |E_{in}(g)-E_{out}(g)| > \epsilon ∣Ein(g)−Eout(g)∣>ϵ,因为g是H中的一个假设.将 β m \beta_m βm代表事件" ∣ E i n ( h m ) − E o u t ( h m ) ∣ > ϵ |E_{in}(h_m)-E_{out}(h_m)| > \epsilon ∣Ein(hm)−Eout(hm)∣>ϵ",因此,对应不等式变为:
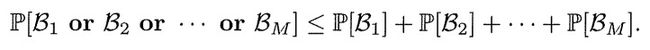
但是如果各个事件之间相互重叠,那么右边界就变得比实际上大得多.比如有3个假设,不同事件的面积代表对应的事件发生的概率, β 1 , b e t a 2 , b e t a 3 \beta_1,beta_2,beta_3 β1,beta2,beta3三个事件的联合边界比3个事件对应面积小得多,尽管面积和的边界是正确的.由此推导,假设空间中如果有假设函数相差不多,就会造成大量的重叠,导致右边界比实际值大得多(放得太多!).我们需要想办法将对应的假设划分开来(归类,分成不同的类别),从而将无限的假设集变成有限的假设集.
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第2张图片](http://img.e-com-net.com/image/info8/d32d5b01f12c4d6f90219f5cd57ed0d4.jpg)
Effective Number of Hypotheses假设空间的有效数量
介绍一个概念growth function增长函数–定义假设空间的有效数量.我们用growth function来代替上面不等式中的M,growth function是一个组合量,能度量假设空间H中假设函数之间的差异,也就是图中不同假设之间的重叠面积的大小.
对于一个2分类的目标函数,每个 h ∈ H h \in H h∈H将输入空间X映射到{-1,1}上.growth function的定义是基于假设空间H中不同假设函数的数目,而且是基于有限的样本点,而不是整个输入空间X.
一个假设函数 h ∈ H h \in H h∈H应用到有限样本集上 x 1 , x 2 , . . . , x N ∈ X x_1,x_2,...,x_N \in X x1,x2,...,xN∈X,可以得到一个二分类的N元组 h ( x 1 ) , h ( x 2 ) , . . . , h ( x N ) h(x_1), h(x_2),...,h(x_N) h(x1),h(x2),...,h(xN).N元组将N个样本集分为两类:正类,负类,这个N元组叫做dichotomy(二分)—对数据点一次结果划分.每个 h ∈ H h \in H h∈H在N个数据点上都会产生一个dichotomy,但是不同的假设函数产生的dichotomy可能完全相同.
定义一 x 1 , x 2 , . . . , x N ∈ X x_1,x_2,...,x_N \in X x1,x2,...,xN∈X,在N个数据点上,假设空间H产生的dichotomies定义为:
H ( x 1 , x 2 , . . . , x N ) = { ( h ( x 1 ) , h ( x 2 ) , . . . , h ( x N ) ) ∣ h ∈ H } H(x_1,x_2,...,x_N) = \{(h(x_1),h(x_2),...,h(x_N))|h \in H\} H(x1,x2,...,xN)={(h(x1),h(x2),...,h(xN))∣h∈H}.
H(x_1,x_2,…,x_N)空间是假设空间H中每个假设函数对N个数据点划分产生的dichotomy的集合空间.一个大的H(x_1,x_2,…,x_N)意味着假设空间更加多种多样–在N个数据点上产生的dichotomy更多.growth function基于dichotomies的数目.
定义二 假设空间H上的growth function定义为:
m H ( N ) = m a x x 1 , x 2 , . . . , x N ∈ X ∣ H ( x 1 , x 2 , . . . , x N ) ∣ m_H(N) = max_{x_1,x_2,...,x_N \in X}|H(x_1,x_2,...,x_N)| mH(N)=maxx1,x2,...,xN∈X∣H(x1,x2,...,xN)∣
其中|\cdot|表示集合中元素的数目. m H ( N ) m_H(N) mH(N)表示在任意N个数据点假设空间H可以生成的不同dichotomies的最大数目.为了比较 m H ( N ) m_H(N) mH(N),我们需要考虑输入空间X中N个数据点的所有可能,然后选择能产生最多dichotomies的数据点集.和M类似, m H ( N ) m_H(N) mH(N)是假设空间H中假设函数数目的一种度量,不同之处在于每个假设是在N个输入点上进行衡量,而不是整个输入空间X.对于任意假设空间H,因为 H ( x 1 , x 2 , . . . , x N ) ⊆ { − 1 , + 1 } N H(x_1,x_2,...,x_N) \subseteq \{-1,+1\}^N H(x1,x2,...,xN)⊆{−1,+1}N, m H ( N ) m_H(N) mH(N)最大值为:
m H ( N ) ≤ 2 N m_H(N) \leq 2^N mH(N)≤2N.
如果H能够生成N个数据点上所有的可能的类别分布,也就是说 H ( x 1 , x 2 , . . . , x N ) = { − 1 , + 1 } N H(x_1,x_2,...,x_N) = \{-1,+1\}^N H(x1,x2,...,xN)={−1,+1}N,称假设空间H能shatter(打碎)N个数据点[能覆盖N个数据所有可能的分类集合].
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第3张图片](http://img.e-com-net.com/image/info8/bebc939352724c19aab974fa3e6e36a1.jpg)
图中可以看到, m H ( N ) m_H(N) mH(N)是N个数据点产生不同dichotomies的最大值,(a)图中3点共线时有种情况使用感知机模型不能划分,但是(b)图中3个点可能产生的dichotomies都可以实现,所以 m H ( 3 ) = 8 m_H(3)=8 mH(3)=8,©图中的dichotomy不同通过感知机生成,所以 m H ( 4 ) = 14 m_H(4)=14 mH(4)=14,而不是16.同时可以知道随着假设空间H变得复杂, m H ( N ) m_H(N) mH(N)也逐渐增大–这符合我们的期望.
计算每个假设空间上的增长函数 m H ( N ) m_H(N) mH(N)并不实际,而且也没有必要,因为我们使用增长函数 m H ( N ) m_H(N) mH(N)来代替不等式中的M,我们可以计算增长函数 m H ( N ) m_H(N) mH(N)的上界,而不是计算增长函数 m H ( N ) m_H(N) mH(N)的确定值,使用增长函数的上界用在不等式中也成立.
定义三 对于假设空间H,如果k个点组成的输入集不能被假设空间shatter(打碎),那么k定义为假设空间H的break point.
如果k是break point,那么 m H ( k ) < 2 k m_H(k) < 2^k mH(k)<2k. 通常情况下,计算假设空间H的break point比计算假设空间的增长函数要容易得多.
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第4张图片](http://img.e-com-net.com/image/info8/c1935a24e878499b95fd18070360c516.jpg)
如果数据点超过k,假设空间更不可能对其shatter,break point更像是对输入情况的一种界限.
我们使用break point k来导出对任意N的增长函数 m H ( N ) m_H(N) mH(N)的一个边界.比如2维感知机不能把4个点shatter,这个知识对于当输入点是5或更多时,对感知机能产生的dichotomies能有一个限制.接下来,讨论 m H ( N ) m_H(N) mH(N)的边界是什么.
Bounding the Growth Function增长函数的边界
关于增长函数而言,如果 m H ( N ) = 2 N m_H(N) = 2^N mH(N)=2N在某个点被打破,那么 m H ( N ) m_H(N) mH(N)对于任意值N可以通过这个break point用一个简单的多项式确定边界.如果不存在break point,对于所有N而言, m H ( N ) = 2 N m_H(N) = 2^N mH(N)=2N总是成立的.如果用 m H ( N ) m_H(N) mH(N)来代替不等式中的M,那么 1 2 N l n 2 M δ \sqrt{\frac1{2N}ln\frac{2M}{\delta}} 2N1lnδ2M泛化误差边界无论训练样本N取多大都不可能趋于零( m H ( N ) = 2 N m_H(N) = 2^N mH(N)=2N);但是如果 m H ( N ) m_H(N) mH(N)可以用一个多项式来代替,那么当训练样本数 N → ∞ N \to \infty N→∞,泛化误差将会趋于零,这意味着在充足样本集下,模型的泛化结果可以非常好.
定理 如果存在k,使得 m H ( k ) < 2 k m_H(k) < 2^k mH(k)<2k成立,那么,
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第5张图片](http://img.e-com-net.com/image/info8/f9274e6bfe1d4d0294369fb12244c326.jpg)
对于所有的N都成立.RHS是一个N的k-1阶多项式.如果增长函数存在break point k,那么就可以使用N的多项式来确定增长函数的上界,因此可以来替换增长函数.
上面定理的含义是指如果假设空间H存在一个break point,我们就可以确保模型的泛化效果, m H ( N ) m_H(N) mH(N)存在一个多项式边界.
The VC Dimension VC维
上面的定理可以使用break point对整个增长函数growth function确定边界.break point越小,边界越好(越小).
VC维 假设空间H的VC维 d V C ( H ) d_{VC}(H) dVC(H),简写为 d V C d_{VC} dVC,是指能被H打散的最大的示例集(数据集)的大小N,N满足 m H ( N ) = 2 N m_H(N)=2^N mH(N)=2N.如果对于所有的N,等式 m H ( N ) = 2 N m_H(N)=2^N mH(N)=2N都成立,那么 d V C = ∞ d_{VC}= \infty dVC=∞.
如果 d V C d_{VC} dVC是假设空间H的VC维,那么break point k = d V C + 1 k = d_{VC}+1 k=dVC+1.因为根据VC维定义,VC维是假设空间H能打碎的最大样本集,所以k就是H的break point,而且不可能存在更小的break point了,因为H可以打碎 d V C d_{VC} dVC个样本点,对于更小的样本点更不在话下.
因为 m H m_H mH的break point k满足 k = d V C + 1 k=d_{VC}+1 k=dVC+1,所以定理可以改写为:
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第6张图片](http://img.e-com-net.com/image/info8/ac9c086c323b499689326b8324cd75b3.jpg)
所以,VC维是增长函数 m H ( N ) m_H(N) mH(N)的多项式阶数.这个多项式边界可以进行简化.可以用归纳法证明:
m H ( N ) ≤ N d V C + 1 m_H(N) \leq N^{d_{VC}} + 1 mH(N)≤NdVC+1.
这样,增长函数growth function可以用VC维来进行约束,接下来就是分析使用增长函数 m H ( N ) m_H(N) mH(N)对M进行替换后,泛化边界的如何变化.使用 m H ( N ) m_H(N) mH(N)替换M后,
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第7张图片](http://img.e-com-net.com/image/info8/b867f6b4c124401f9d5745f4b3d7d978.jpg)
已知增长函数 m H ( N ) m_H(N) mH(N)可以被一个N的多项式约束,除非假设空间为VC维无穷大 d V C ( H ) = ∞ d_{VC}(H) = \infty dVC(H)=∞.增长函数取对数后,呈对数级增长,然后被 1 N \frac1{N} N1减小,因此,如果训练样本N足够大,那么 E o u t E_{out} Eout会接近于 E i n E_{in} Ein.(证明了无穷大时,可学性的第一个问题).
只有当VC维趋于无穷大时,假设才会失效.对于任意有限的VC维来说,误差收敛到0的速度取决于VC维的大小,因为VC维是多项式的阶数.VC维越小,收敛到0的速度越快.
但是仅仅用 m H ( N ) m_H(N) mH(N)来代替泛化边界中M是不够的,还需要进一步调整.不过VC维在其中还扮演了非常重要的角色.可以将假设空间中假设分为两类:good models & bad models.'Good models’指VC维有限,且样本集N足够大的模型,这种模型可以保证 E o u t ≈ E i n E_{out} \approx E_{in} Eout≈Ein,样本集的表现可以泛化到样本集之外;'bad models’指VC维无穷大,对于bad models无论样本集N取多大,我们不能基于VC维对 E i n E_{in} Ein和 E o u t E_{out} Eout进行泛化比较.
可以将VC维看做模型的"有用参数量",模型参数越多,假设空间假设函数越多,这反应了增长函数 m H ( N ) m_H(N) mH(N)的大小.比如说 w 0 , w 1 , . . . , w d w_0,w_1,...,w_d w0,w1,...,wd的感知机模型,VC维是d+1.对于其他模型而言,有用参数可能不太明显.VC维能衡量有用参数或自由度,这些量可以保证模型数目的多样性.但多样性也不是越多越好,比如 m H ( N ) = 2 N m_H(N) = 2^N mH(N)=2N而且 d V C = ∞ d_{VC} = \infty dVC=∞的模型,这种情况下不能对模型进行泛化.
The VC Generalization Bound VC泛化边界
如果将增长函数growth function作为假设空间有效假设的一种度量量,那么使用 m H ( N ) m_H(N) mH(N)代替不等式中M后,可以得到:
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第8张图片](http://img.e-com-net.com/image/info8/487185c0b24b48dda81c11b86fa29c92.jpg)
但这个不等式证明并不是最终的形式.需要修改泛化边界才能成立.使用下面定理,可以到处正确的边界,叫做VC维泛化边界.对于任意二分类目标函数f,任意假设空间H,任意学习算法A,任意的输入概率分布P都成立:
定理:VC泛化边界 对于任意tolerance δ > 0 \delta > 0 δ>0,
E o u t ( g ) ≤ E i n ( g ) + 8 N l n 4 m H ( 2 N ) δ E_{out}(g) \leq E_{in}(g) + \sqrt{\frac8{N}ln\frac{4m_H(2N)}{\delta}} Eout(g)≤Ein(g)+N8lnδ4mH(2N)
成立的概率是 1 − δ 1-\delta 1−δ.
如果和上面的不等式进行比较,可以发现下面不等是的边界更大(move the bound in the weaker direction).只要VC维是有限的,误差就会收敛于0(尽管速度变慢),因为和 m H ( N ) m_H(N) mH(N)一样, m H ( 2 N ) m_H(2N) mH(2N)也是N的 d V C d_{VC} dVC阶多项式.这意味着如果有足够的数据,无限假设空间H中有限VC的每个假设函数的 E i n E_{in} Ein能很好的泛化到 E o u t E_{out} Eout上.其中的关键在于使用定义假设空间有效假设的有限增长函数来替代假设空间的真正数目,从而确定边界.
VC维泛化边界是机器学习理论中非常重要的一个数据结果.它证明了无限假设空间的可学性问题.
The data set D is the source of randomization in the original Hoeffding Inequality.
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第9张图片](http://img.e-com-net.com/image/info8/4b4ac764afbe4af0b43089cceca1ef1b.jpg)
Interpreting the Generalization Bound 泛化边界解释
上面不等式是一个通用结果,可以应用到所有的假设集,所有的学习算法,输入空间,概率分布以及二分类目标函数上.同时也可以扩展到其他类型的目标函数上.因为不等式结果的通用性,因此对于有的模型来说边界可能过于松loose,原因在于这个相同的边界要覆盖到多种类型模型上.
VC维可以用作一种评估模型泛化能力的一个指标,但是相对意义上的,并不具有绝对意义.在实际问题中会采用不同的边界.
Sample Complexity样本复杂度
样本复杂度是指模型达到一定的泛化能力时所需要的训练样本数目N.模型的泛化表现可以用两个参数衡量: ϵ \epsilon ϵ和 δ \delta δ.误差容忍度 ϵ \epsilon ϵ表示容忍的泛化误差量,置信度参数 δ \delta δ表示大于容忍泛化误差边界的概率.随着 ϵ \epsilon ϵ和 δ \delta δ变小,训练样本数N的变化速度表示了为达到一定泛化能力所需要的训练样本数.
对于给定的模型,可以用VC边界来建立样本复杂度.对于固定的 δ \delta δ,假定泛化误差边界最多是 ϵ \epsilon ϵ.从不等式中可以知道,泛化误差限制在 8 N l n 4 m H ( 2 N ) δ \sqrt{\frac8{N}ln\frac{4m_H(2N)}{\delta}} N8lnδ4mH(2N),为了确保不等式 8 N l n 4 m H ( 2 N ) δ ≤ ϵ \sqrt{\frac8{N}ln\frac{4m_H(2N)}{\delta}} \leq \epsilon N8lnδ4mH(2N)≤ϵ成立.为了保证泛化误差最大是 ϵ \epsilon ϵ,那么训练集样本大小N:
N ≥ 8 ϵ 2 l n 4 m H ( 2 N ) δ N \geq \frac8{\epsilon^2}ln\frac{4m_H(2N)}{\delta} N≥ϵ28lnδ4mH(2N)
但是这个样本复杂度N的边界不太明显,因为N出现在不等式的两端.如果用基于VC维的多项式代替 m H ( 2 N ) m_H(2N) mH(2N),可以得到:
N ≥ 8 ϵ 2 l n 4 ( ( 2 N ) d V C + 1 ) δ N \geq \frac8{\epsilon^2}ln\frac{4((2N)^{d_{VC}}+1)}{\delta} N≥ϵ28lnδ4((2N)dVC+1)
但这个不等式同样也是不确定的.我们可以用简单的迭代方法计算N的数值(对N初始化一个值,然后反复计算不等式,直到N收敛).
Penalty for Model Complexity 模型复杂度惩罚
样本复杂度是在泛化误差边界 ϵ \epsilon ϵ和置信度 δ \delta δ确定的情况下对训练样本N的一个估计.但是在大多数实际情况中,都是给定一个固定大小的训练样本集D,因此N大小是确定的.在这种情况下,对于给定N,模型在unseen data上表现如何是我们所关注的问题.
E o u t ( g ) ≤ E i n ( g ) + 8 N l n 4 m H ( 2 N ) δ E_{out}(g) \leq E_{in}(g) + \sqrt{\frac8{N}ln\frac{4m_H(2N)}{\delta}} Eout(g)≤Ein(g)+N8lnδ4mH(2N)
如果用基于VC维的多项式代替 m H ( 2 N ) m_H(2N) mH(2N),可以得到out-of-sample误差的另一种边界表示:
E o u t ( g ) ≤ E i n ( g ) + 8 N l n 4 ( ( 2 N ) d V C + 1 ) δ E_{out}(g) \leq E_{in}(g) + \sqrt{\frac8{N}ln\frac{4((2N)^{d_{VC}}+1)}{\delta}} Eout(g)≤Ein(g)+N8lnδ4((2N)dVC+1)
可以将 E o u t ( g ) E_{out}(g) Eout(g)的边界看做两部分,第一部分是 E i n ( g ) E_{in}(g) Ein(g),第二部分是随着假设空间H的VC维而变化的量 Ω ( N , H , δ ) \Omega(N,H,\delta) Ω(N,H,δ),所以:
E o u t ( g ) ≤ E i n ( g ) + Ω ( N , H , δ ) E_{out}(g) \leq E_{in}(g) + \Omega(N,H,\delta) Eout(g)≤Ein(g)+Ω(N,H,δ)
其中,
Ω ( N , H , δ ) = 8 N l n 4 m H ( 2 N ) δ ≤ 8 N l n 4 ( ( 2 N ) d V C + 1 ) δ \Omega(N,H,\delta) = \sqrt{\frac8{N}ln\frac{4m_H(2N)}{\delta}} \leq \sqrt{\frac8{N}ln\frac{4((2N)^{d_{VC}}+1)}{\delta}} Ω(N,H,δ)=N8lnδ4mH(2N)≤N8lnδ4((2N)dVC+1)
可以将 Ω ( N , H , δ ) \Omega(N,H,\delta) Ω(N,H,δ)看做是对模型复杂度的一种惩罚.当使用更加复杂的假设空间H时(VC维增加),右边不等式边界增加,因此样本外数据上的 E o u t ( g ) E_{out}(g) Eout(g)表现会恶化.如果用相同的训练样本去拟合一个相对简单模型时, E o u t ( g ) E_{out}(g) Eout(g)变现会更好(右边界变小).从模型复杂度惩罚的等式来看,如果用更高的置信度(更小的 δ \delta δ),那么模型会变差;如果用更多样本N,模型会变好.
如果用更复杂的假设空间H(更好的VC维),那么 Ω ( N , H , δ ) \Omega(N,H,\delta) Ω(N,H,δ)会变大,但用数据去拟合模型时,由于有更多的假设可以选择, E i n ( g ) E_{in}(g) Ein(g)会变小.因此存在一个权衡(tradeoff):更复杂的模型可以让样本集模型 E i n ( g ) E_{in}(g) Ein(g)表现变好,但是 Ω ( N , H , δ ) \Omega(N,H,\delta) Ω(N,H,δ)会增加(惩罚度变大,因此 E o u t ( g ) E_{out}(g) Eout(g)变差,泛化效果不好).最佳的模型是两个量的组合值( E o u t ( g ) E_{out}(g) Eout(g))能最小.
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第10张图片](http://img.e-com-net.com/image/info8/0370fac002d64a7c98f24e6e20cfa313.jpg)
The Test Set 测试集
泛化边界是基于 E i n E_{in} Ein的对 E o u t E_{out} Eout的一个宽泛估计.这个估计对于训练过程来说是一个指导,但如果目标是得到一个关于 E o u t E_{out} Eout的精准预测,这个边界作用不大.
一种可选方法是使用test set测试集对 E o u t E_{out} Eout进行估计,测试集中的数据并不应用在训练过程中.最终的假设函数g是在测试集上进行评估,评估结果作为 E o u t E_{out} Eout的一个估计.
把测试集上的测试结果称作 E t e s t E_{test} Etest.当我们用 E t e s t E_{test} Etest作为 E o u t E_{out} Eout的一个估计时,事实上假定 E t e s t E_{test} Etest泛化效果很好,接近于 E o u t E_{out} Eout.但是, E t e s t E_{test} Etest和 E i n E_{in} Ein类似只是一个对样本结果估计.我们如何确保 E t e s t E_{test} Etest泛化效果如何呢?
E t e s t E_{test} Etest泛化效果相关的假设的有效数目是1.因为考虑到测试集,只存在一个假设,就是训练过程中产生的最终假设函数g.选择的测试集不同并不影响最终的假设函数,但如果选择不同的训练集,最终的假设函数会跟着改变.同时Hoeffding不等式可以应用在 E t e s t E_{test} Etest的一个假设上,产生的边界比VC维边界更加紧密.测试集越大, E t e s t E_{test} Etest对 E o u t E_{out} Eout的估计越准确.
使用测试集有一定的代价.测试集并不影响学习过程的输出,学习过程仅和训练集相关.测试集告诉我们学习过程产生的模型表现如何.因此,如果我们将一部分数据分成测试集,那么用于训练的数据就会减少.因为训练数据是用来在假设空间中选择一个假设,因此训练数据对于选择最终的假设函数至关重要.There is a tradeoff to setting aside test examples.训练集和测试集如何划分,比例如何需要仔细权衡.
在一些文献中, E t e s t E_{test} Etest看做是 E o u t E_{out} Eout的同义词.
Other Target Types 其他目标类型
尽管VC维分析是基于二分类目标函数的,但是也可以扩展到实值函数或其他类型函数上.介绍一种新的方法偏差-方差分析.
为了符合实值函数,需要调整 E i n E_{in} Ein和 E o u t E_{out} Eout的定义.在实值函数中,需要测量h(x)和f(x)之间的距离,而不是判断两个值是否相等.
最常用的误差测量方法是平方误差 e ( h ( x ) , f ( x ) ) = ( h ( x ) − f ( x ) ) 2 e(h(x),f(x)) = (h(x)-f(x))^2 e(h(x),f(x))=(h(x)−f(x))2.可以定义样本内和样本外的误差.样本外误差是基于整个输入空间X的,
E o u t ( h ) = E [ ( h ( x ) − f ( x ) ) 2 ] E_{out}(h) = E[( h(x)-f(x))^2] Eout(h)=E[(h(x)−f(x))2]
样本内误差是基于整个训练集误差量的平均值:
E i n ( h ) = 1 N ∑ n = 1 N ( h ( x n ) − f ( x n ) ) 2 E_in(h)=\frac1{N} \sum_{n=1}^N(h(x_n) -f(x_n))^2 Ein(h)=N1∑n=1N(h(xn)−f(xn))2
使用样本误差均值去评估误差的期望值.
Approximation-Generalization tradeoff
VC维分析需要选择在训练数据上接近目标函数f和在unseen data上泛化良好这两个变现之间取得平衡的假设.当在假设空间H中选择假设函数时,需要在两个矛盾的目标之间进行权衡:在假设空间中选择可以接近f的假设,同时保证训练数据上学的模型能泛化到整个输入空间上.VC维泛化边界就是一种两者之间权衡方法.如果H太过于简单,选择的假设可能不能接近f,样本内误差很大;如果H太过于复杂,泛化效果变差,因为模型复杂度太大.存在另外一种方法:近似泛化tradeoff.这种方法适合平方误差测量,而不是VC分析中使用的二分误差.这种方法提供了一个新的角度:VC维分析中使用 E i n E_{in} Ein加上惩罚项 Ω \Omega Ω来对 E o u t E_{out} Eout进行近似;这里将 E o u t E_{out} Eout分成两部分误差项.
Bias and Variance偏差和方差
样本外误差偏差-方差分解是基于平方误差测量方法的.Out-of-sample误差:
E o u t ( g ( D ) ) = E x [ ( g ( D ) ( x ) − f ( x ) ) 2 ] E_{out}(g^{(D)}) = E_x[ (g^{(D)}(x) - f(x))^2] Eout(g(D))=Ex[(g(D)(x)−f(x))2]
其中, E x E_{x} Ex表示关于x的期望值.在最终假设g上添加显性的对数据集D的依赖关系.上面等式中样本外误差的计算依赖于从选择数据集D中训练出来的最终假设g,也就是说是依赖于选择的训练数据集的.我们可以在所有可能的训练集上求期望值,移除对选择的特定数据集D的依赖,从而独立于数据集:
E D [ E o u t ( g D ) ] = E D [ E x [ ( g ( D ) ( x ) − f ( x ) ) 2 ] ] = E x [ E D [ ( g ( D ) ( x ) − f ( x ) ) 2 ] ] = E x [ E D [ g ( D ) ( x ) 2 ] − 2 E D [ g ( D ) ( x ) ] f ( x ) + f ( x ) 2 ] E_D[ E_{out}(g^D)] = E_D[ E_x[(g^{(D)}(x) - f(x))^2]] \\=E_x[ E_D[(g^{(D)}(x) - f(x))^2]] \\=E_x[ E_D[ g^{(D)(x)^2}] -2 E_D[ g^{(D)(x)}]f(x) + f(x)^2] ED[Eout(gD)]=ED[Ex[(g(D)(x)−f(x))2]]=Ex[ED[(g(D)(x)−f(x))2]]=Ex[ED[g(D)(x)2]−2ED[g(D)(x)]f(x)+f(x)2]
其中, E D [ g ( D ) ( x ) ] E_D[ g^{(D)}(x)] ED[g(D)(x)]是一个平均函数,也可以表示为 g ^ ( x ) \hat{g}(x) g^(x).可以理解为生成若干个数据集 D 1 , D 2 , . . . , D K D_1,D_2,...,D_K D1,D2,...,DK然后在每个数据集上进行训练学习,生成最终的假设 g 1 , g 2 , . . . , g K g_1,g_2,...,g_K g1,g2,...,gK.而任意数据x在最终的平均假设上的结果为 g ^ ( x ) ≈ 1 K ∑ k = 1 K g k ( x ) \hat{g}(x) \approx \frac1{K} \sum_{k=1}^K g_k(x) g^(x)≈K1∑k=1Kgk(x).本质上,可以将g(x)看做是一个随机变量,在随机数据集上的随机产生的; g ^ ( x ) \hat{g}(x) g^(x)是特定值x在随机变量上的期望值, g ^ \hat{g} g^是一个函数,取平均值.同时函数 g ^ \hat{g} g^有一点违反常识: g ^ \hat{g} g^不在假设空间中,但是在假设空间中函数的平均值.
可以使用 g ^ \hat{g} g^对out-of-sample误差进行改写:
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第11张图片](http://img.e-com-net.com/image/info8/8de4da6f2c8b4f25b4adedbfd41224e2.jpg)
其中, g ^ ( x ) \hat{g}(x) g^(x)是对于D来说是一个常量; ( g ^ ( x ) − f ( x ) ) 2 (\hat{g}(x)-f(x))^2 (g^(x)−f(x))2测量从数据集D中学到的平均函数与目标函数f之间的差距,可以把这个量称为bias偏差:
b i a s ( x ) = ( g ^ ( x ) − f ( x ) ) 2 bias(x)=(\hat{g}(x)-f(x))^2 bias(x)=(g^(x)−f(x))2
表示学习模型偏离目标函数的距离(偏差).因为 g ^ ( x ) \hat{g}(x) g^(x)是从不限数目多个数据集中学习的,因此它在估计目标函数时仅仅受限于模型自身. E D [ ( g ( D ) ( x ) − g ^ ( x ) ) 2 ] E_D[ (g^{(D)}(x) - \hat{g}(x))^2] ED[(g(D)(x)−g^(x))2]是随机变量 g ( D ) ( x ) g^{(D)}(x) g(D)(x)的方差:
v a r ( x ) = E D [ ( g ( D ) ( x ) − g ^ ( x ) ) 2 ] var(x) = E_D[ (g^{(D)}(x) - \hat{g}(x))^2] var(x)=ED[(g(D)(x)−g^(x))2]
评估依赖于数据集的最终假设的变化情况(方差).最后,out-of-sample误差的偏差-方差分解为:
E D [ E o u t ( g ( D ) ) ] = E x [ b i a s ( x ) + v a r ( x ) ] = b i a s + v a r E_D[ E_{out}(g^{(D)})] = E_x[ bias(x) + var(x)] \\=bias + var ED[Eout(g(D))]=Ex[bias(x)+var(x)]=bias+var
因为, b i a s = E x [ b i a s ( x ) ] , v a r = E x [ v a r ( x ) ] bias = E_x[ bias(x)], var=E_x[ var(x)] bias=Ex[bias(x)],var=Ex[var(x)]. 这里的推导都基于数据是无噪音的假设.如果是带噪音的数据,在最终的偏差-方差分解中需要加上噪音项.
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第12张图片](http://img.e-com-net.com/image/info8/1e87fd48d1264262a69bb73d0fb53630.jpg)
可以将方差看做学习模型的不稳定性(也就是方差的意义).
在偏差方差分析中学习算法有很大的影响(在VC维分析中却无关紧要).
- VC维分析只基于假设空间H,独立于学习算法A;在偏差-方差分析中,学习算法A和假设空间H同样重要.相同的假设空间,不同的学习算法会产生不同的 g ( D ) g^{(D)} g(D).
- 尽管偏差-方差分析是基于平方误差测量方法的,但是学习算法并不一定是基于最小化平方误差.可以使用任何基于D的标准产生最终假设 g ( D ) g^{(D)} g(D).但一旦产生 g ( D ) g^{(D)} g(D)之后,必须基于平方误差计算偏差和方差.
不幸的是,实际情况下偏差和方差并不能计算出来,因为它们是依赖于目标函数和输入概率分布,而这两项都是未知的.但是偏差-方差分析在开发模型时是一种非常重要的概念性工具.当考虑偏差和方差时,需要考虑两个目标:在不显著增加偏差的基础上尝试降低方差;在不显著增加方差的基础上尝试降低偏差.
The Learning Curve学习曲线
学习曲线概括了当训练集样本数N变化时,样本内误差和样本外误差的变化情况.在大小为N的数据集D上学习之后,可以得到依赖于D的样本误差和样本外误差.就像之前在偏差-方差中介绍的一样,对大小为N的所有可能数据集D求期望之后, E D [ E i n [ g ( D ) ] ] E_D[ E_{in}[ g^{(D)}]] ED[Ein[g(D)]]和 E D [ E o u t [ g ( D ) ] ] E_D[ E_{out}[ g^{(D)}]] ED[Eout[g(D)]]是关于N的函数.比如一个简单模型和复杂模型的学习曲线如下:
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第13张图片](http://img.e-com-net.com/image/info8/705161c965c54b8380de51ce711c7364.jpg)
可以看出,对于简单模型来说,收敛速度更快,但是最终表现比复杂模型要差.对于两个模型来说,样本外误差都随着N的增大而减小;样本内误差随着N增加而增大. 用VC维分析和偏差-方差分析,结果如何呢?
![[Learning-from-data]无限假设空间的可学性以及模型泛化_第14张图片](http://img.e-com-net.com/image/info8/77ffe09d933d43d59163502130254239.jpg)
在VC维分析中, E o u t E_{out} Eout是 E i n E_{in} Ein和泛化边界模型复杂度惩罚 Ω \Omega Ω之和.在偏差-方差分析中, E o u t E_{out} Eout被分解为偏差和方差之和.
随着样本点增多,泛化误差和方差都减小.学习曲线可表明了关于 E i n E_{in} Ein的一个重要特性.随着N的增加,为了逼近f, E i n E_{in} Ein接近于学习模型的最小误差.当N很小时, E i n E_{in} Ein与"应该的最小误差"很远,主要是因为对小数据来说,学习难度更小.