开源 TiDB Operator 让 TiDB 成为真正的 Cloud-Native 数据库
TiDB Operator 是 TiDB 在 Kubernetes 平台上的自动化部署运维工具,借助 TiDB Operator,TiDB 可以无缝运行在公有云厂商提供的 Kubernetes 平台上,让 TiDB 成为真正的 Cloud-Native 数据库。
要了解 TiDB Operator,首先需要对 TiDB 和 Kubernetes 有一定了解,相信长期以来一直关注 TiDB 的同学可能对 TiDB 已经比较熟悉了。本文将首先简单介绍一下 TiDB 和 Kubernetes,聊一聊为什么我们要做 TiDB Operator,然后讲讲如何快速体验 TiDB Operator,以及如何参与到 TiDB Operator 项目中来成为 contributor。
TiDB 和 Kubernetes 简介
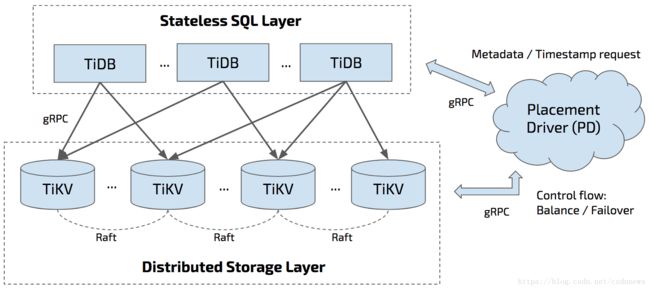
TiDB 作为一个开源的分布式数据库产品,具有多副本强一致性的同时能够根据业务需求非常方便的进行弹性伸缩,并且扩缩容期间对上层业务无感知。TiDB 包括三大核心组件:TiDB/TiKV/PD。
- TiDB Server:主要负责 SQL 的解析器和优化器,它相当于计算执行层,同时也负责客户端接入和交互。
- TiKV Server:是一套分布式的 Key-Value 存储引擎,它承担整个数据库的存储层,数据的水平扩展和多副本高可用特性都是在这一层实现。
- PD Server:相当于分布式数据库的大脑,一方面负责收集和维护数据在各个 TiKV 节点的分布情况,另一方面 PD 承担调度器的角色,根据数据分布状况以及各个存储节点的负载来采取合适的调度策略,维持整个系统的平衡与稳定。
上面的这三个组件,每个角色都是一个多节点组成的集群,所以最终 TiDB 的架构看起来是这样的。
Kubernetes 最早是作为一个纯粹的容器编排系统而诞生的,用户部署好 Kubernetes 集群之后,直接使用其内置的各种功能部署应用服务。
由于这个 PaaS 平台使用起来非常便利,吸引了很多用户,不同用户也提出了各种不同的需求。有些特性需求 Kubernetes 直接在其核心代码里面实现了,但是有些特性并不适合合并到主干分支。
为满足这类需求,Kubernetes 开放出一些 API 供用户自己扩展,实现自己的需求。当前 Kubernetes 内部的 API 变得越来越开放,使其更像是一个跑在云上的操作系统。用户可以把它当作一套云的 SDK 或 Framework 来使用,而且可以很方便地开发组件来扩展满足自己的业务需求。对有状态服务的支持就是一个很有代表性的例子。
为什么我们要做 TiDB Operator
第一,使用传统的自动化工具带来了很高的部署和运维成本。TiDB 的分层架构对于分布式系统是比较常见的,各个组件都可以根据业务需求独立水平伸缩,并且 TiKV 和 TiDB 都可以独立使用。比如,在 TiKV 之上可以构建兼容 Redis 协议的 KV 数据库,而 TiDB 也可以对接 LevelDB 这样的 KV 存储引擎。
但是,这种多组件的分布式系统增加了手工部署和运维的成本。一些传统的自动化部署和运维工具如 Puppet/Chef/SaltStack/Ansible,由于缺乏全局状态管理,不能及时对各种异常情况做自动故障转移,并且很难发挥分布式系统的弹性伸缩能力。其中有些还需要写大量的 DSL 甚至与 Shell 脚本一起混合使用,可移植性较差,维护成本比较高。
第二,在云时代,容器成为应用分发部署的基本单位,而谷歌基于内部使用数十年的容器编排系统 Borg 经验推出的开源容器编排系统 Kubernetes 成为当前容器编排技术事实上的标准。如今各大云厂商都开始提供托管的 Kubernetes 集群,部署在 Kubernetes 平台的应用可以不用绑定在特定云平台,轻松实现在各种云平台之间的迁移,其容器化打包和发布方式也解决了对操作系统环境的依赖。
Kubernetes 项目最早期只支持无状态服务 (Stateless Service) 的管理。无状态服务通过 ReplicationController 定义多个副本,由 Kubernetes 调度器来决定在不同节点上启动多个 Pod,实现负载均衡和故障转移。对于无状态服务,多个副本对应的 Pod 是等价的,所以在节点出现故障时,在新节点上启动一个 Pod 与失效的 Pod 是等价的,不会涉及状态迁移问题,因而管理非常简单。
但是对于有状态服务 (Stateful Service),由于需要将数据持久化到磁盘,使得不同 Pod 之间不能再认为成等价,也就不能再像无状态服务那样随意进行调度迁移。
Kubernetes v1.3 版本提出 PetSet 的概念,用来管理有状态服务并于 v1.5 将其更名为 StatefulSet。StatefulSet 明确定义一组 Pod 中每个的身份,启动和升级都按特定顺序来操作。另外使用持久化卷存储 (PersistentVolume) 来作为存储数据的载体,当节点失效 Pod 需要迁移时,对应的 PV 也会重新挂载,而 PV 的底层依托于分布式文件系统,所以 Pod 仍然能访问到之前的数据。同时 Pod 在发生迁移时,其网络身份例如 IP 地址是会发生变化的,很多分布式系统不能接受这种情况。所以 StatefulSet 在迁移 Pod 时可以通过绑定域名的方式来保证 Pod 在集群中网络身份不发生变化。
但是由于有状态服务的特殊性,当节点出现异常时,出于数据安全性考虑,Kubernetes 并不会像无状态服务那样自动做故障转移。尽管网络存储能挂载到不同的节点上供其上的 Pod 使用,但是如果出现节点故障时,简单粗暴地将网络 PV 挂载到其它节点上是比较危险的。
Kubernetes 判断节点故障是基于部署在每个节点上的 Kubelet 服务是否能正常上报节点状态,Kubelet 能否正常工作与用户应用并没有必然联系,在一些特殊情况下,Kubelet 服务进程可能无法正常启动,但是节点上的业务容器还在运行,将 PV 再挂载到其它节点可能会出现双写问题。
为了在 Kubernetes 上部署和管理 TiDB 这种有状态的服务,我们需要扩展 StatefulSet 的功能。TiDB Operator 正是基于 Kubernetes 内置的 StatefulSet 开发的 TiDB 集群管理和运维工具。
Kubernetes 直到 v1.7 才试验性引入本地 PV,在这之前只有网络 PV,TiKV 自身在存储数据时就是多副本的,网络 PV 的多副本会增加数据冗余,降低 TiDB 的性能。在这之前我们基于 Kubernetes 内置的 hostPath volume 实现了本地 PV 满足 TiKV 对磁盘 IO 的要求。官方本地 PV 方案直到最近的 Kubernetes v1.10 才相对稳定地支持调度功能,满足用户对本地 PV 的需求。为了降低用户的使用和管理成本并且拥抱 Kubernetes 开源社区,我们又重新基于官方的本地 PV 方案实现了对数据的管理。
TiDB Operator 原理解析
Operator 本质上是 Kubernetes 的控制器 (Controller),其核心思想是用户给定一个 Spec 描述文件,Controller 根据 Spec 的变化,在 Kubernetes 集群中创建对应资源,并且不断调整资源使其状态满足用户预期的 Spec。
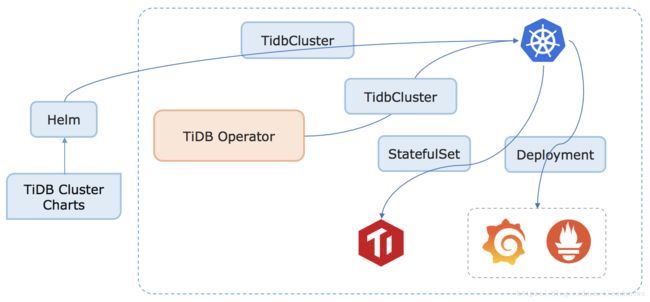
上图是 TiDB Operator 工作流程原理图,其中 TidbCluster 是通过 CRD (Custom Resource Definition) 扩展的内置资源类型:
- 用户通过 Helm 往 Kubernetes API Server 创建或更新 TidbCluster 对象;
- TiDB Operator 通过 watch API Server 中的 TidbCluster 对象创建更新或删除,维护 PD/TiKV/TiDB StatefulSet, Service 和 Deployment 对象更新;
- Kubernetes 根据 StatefulSet, Service 和 Deployment 对象创建更新或删除对应的容器和服务。
在第 2 步中,TiDB Operator 在更新 StatefulSet 等对象时会参考 PD API 给出的集群状态来做出 TiDB 集群的运维处理。通过 TiDB Operator 和 Kubernetes 的动态调度处理,创建出符合用户预期的 TiDB 集群。
快速体验 TiDB Operator
TiDB Operator 需要运行在 Kubernetes v1.10 及以上版本。TiDB Operator 和 TiDB 集群的部署和管理是通过 Kubernetes 平台上的包管理工具 Helm 实现的。运行 TiDB Operator 前请确保 Helm 已经正确安装在 Kubernetes 集群里。
如果没有 Kubernetes 集群,可以通过 TiDB Operator 提供的脚本快速在本地启动一个多节点的 Kubernetes 集群:
git clone https://github.com/pingcap/tidb-operator
cd tidb-operator
NUM_NODES=3 # the default node numble is 2
KUBE_REPO_PREFIX=uhub.ucloud.cn/pingcap manifests/local-dind/dind-cluster-v1.10.sh up等 Kubernetes 集群准备好,就可以通过 Helm 和 Kubectl 安装部署 TiDB Operator 和 TiDB 集群了。
1.安装 TiDB Operator
kubectl apply -f manifests/crd.yaml
helm install charts/tidb-operator --name=tidb-operator --namespace=tidb-admin2.部署 TiDB 集群
helm install charts/tidb-cluster --name=demo-tidb --namespace=tidb --set clusterName=demo集群默认使用 local-storage 作为 PD 和 TiKV 的数据存储,如果想使用其它持久化存储,需要修改 charts/tidb-cluster/values.yaml 里面的 storageClassName
参与 TiDB Operator
TiDB Operator 让 TiDB 成为真正意义上的 Cloud-Native 数据库,开源只是一个起点,需要 TiDB 社区和 Kubernetes 社区的共同参与。
大家在使用过程发现 bug 或缺失什么功能,都可以直接在 GitHub 上面提 issue 或 PR,一起参与讨论。要想成为 contributor 具体可以参考文档。