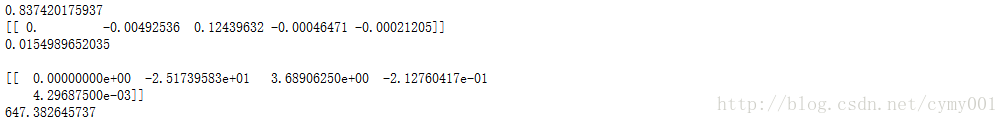模型泛化能力——过拟合与欠拟合,L1/L2正则化(复习16)
本文是个人学习笔记,内容主要是观察多项式曲线对数据的拟合/过拟合/欠拟合,及加正则化项对模型的不同修正作用。
拟合:机器学习模型在训练的过程中,通过更新参数,使模型不断契合可观测数据(训练集)的过程。
利用一次曲线回归拟合
X_train=[[6],[8],[10],[14],[18]]
y_train=[[7],[9],[13],[17.5],[18]]
from sklearn.linear_model import LinearRegression
regressor=LinearRegression() #默认配置初始化线性回归模型
regressor.fit(X_train,y_train) #根据训练集数据建模
import numpy as np
xx=np.linspace(0,26,100) #构建测试集
xx=xx.reshape(xx.shape[0],1)
yy=regressor.predict(xx)
%matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(X_train,y_train)
plt1,=plt.plot(xx,yy,label='Degree=1')
plt.axis([0,25,0,25])
plt.xlabel('independent variable')
plt.ylabel('dependent variable')
plt.legend(handles=[plt1])
plt.show()
print('The R-squared value of Linear Regressor performing on the training data is',
regressor.score(X_train,y_train))
利用二次曲线回归拟合
from sklearn.preprocessing import PolynomialFeatures
poly2=PolynomialFeatures(degree=2) #多项式特征产生器
X_train_poly2=poly2.fit_transform(X_train) #X_train_poly2即为由训练集构造出的二次多项式特征
regressor_poly2=LinearRegression()
regressor_poly2.fit(X_train_poly2,y_train) #建模生产的二次多项式回归模型
xx_poly2=poly2.transform(xx) #对测试集数据构造二次多项式特征
yy_poly2=regressor_poly2.predict(xx_poly2)
plt.scatter(X_train,y_train)
plt1,=plt.plot(xx,yy,label='Degree=1')
plt2,=plt.plot(xx,yy_poly2,label='Degree=2')
plt.axis([0,25,0,25])
plt.xlabel('independent variable')
plt.ylabel('dependent variable')
plt.legend(handles=[plt1,plt2])
plt.show()
print('The R-squared value of Polynomial Regressor(Degree=2) performing on the training data is',
regressor_poly2.score(X_train_poly2,y_train))
利用四次曲线回归拟合
from sklearn.preprocessing import PolynomialFeatures
poly4=PolynomialFeatures(degree=4) #多项式特征产生器
X_train_poly4=poly4.fit_transform(X_train) #X_train_poly4即为由训练集构造出的四次多项式特征
regressor_poly4=LinearRegression()
regressor_poly4.fit(X_train_poly4,y_train) #建模生产的四次多项式回归模型
xx_poly4=poly4.transform(xx) #对测试集数据构造四次多项式特征
yy_poly4=regressor_poly4.predict(xx_poly4)
plt.scatter(X_train,y_train)
plt1,=plt.plot(xx,yy,label='Degree=1')
plt2,=plt.plot(xx,yy_poly2,label='Degree=2')
plt4,=plt.plot(xx,yy_poly4,label='Degree=4')
plt.axis([0,25,0,25])
plt.xlabel('independent variable')
plt.ylabel('dependent variable')
plt.legend(handles=[plt1,plt2,plt4])
plt.show()
print('The R-squared value of Polynomial Regressor(Degree=4) performing on the training data is',
regressor_poly4.score(X_train_poly4,y_train))
评估以上三个模型在测试集上的性能表现
X_test=[[6],[8],[11],[16]]
y_test=[[8],[12],[15],[18]]
print('Linear regression:',regressor.score(X_test,y_test))
X_test_poly2=poly2.transform(X_test)
print('Polynomial 2 regression:',regressor_poly2.score(X_test_poly2,y_test))
X_test_poly4=poly4.transform(X_test)
print('Polynomial 4 regression:',regressor_poly4.score(X_test_poly4,y_test))
从上面的结果可见:
当模型复杂度较低(一次多项式)时,模型不仅没有对训练集上的数据有良好的拟合状态,而且在测试集上也表现平平,即欠拟合。
当模型复杂度很高(四次多项式)时,尽管模型几乎完全拟合了所有的训练数据,但模型本身变得波动频繁,几乎丧失了对未知数据的预测能力,即过拟合。
过拟合和欠拟合都是缺乏模型泛化能力的表现。
由于无法预测未知数据,所以建模时要充分利用训练数据,避免欠拟合;同时要追求更好的模型泛化能力,避免过拟合。这就要求在增加模型复杂度、提高在可观测数据上的表现性能的同时,又要兼顾模型的泛化能力,防止过拟合。为了平衡二者,通常采用L1/L2正则化方法。
所谓正则化方法,就是在优化的目标函数上加上模型参数的L1/L2范数:
L1正则化是让参数向量中的许多元素趋向于0,让有效特征变得稀疏,对应的L1正则化模型称为Lasso。
L2正则化是让参数向量中的大部分元素都变得很小,压制了参数之间的差异性,对应的L2正则化模型称为Ridge。
from sklearn.linear_model import Lasso
lasso_poly4=Lasso() #默认配置初始化Lasso
lasso_poly4.fit(X_train_poly4,y_train) #利用Lasso对四次多项式特征回归拟合
print(lasso_poly4.score(X_test_poly4,y_test)) #在测试集上进行评估
print(lasso_poly4.coef_) #输出Lasso模型的参数列表
print(' ')
print(regressor_poly4.score(X_test_poly4,y_test)) #对比看一下不加正则化项的四次多项式回归拟合
print(regressor_poly4.coef_)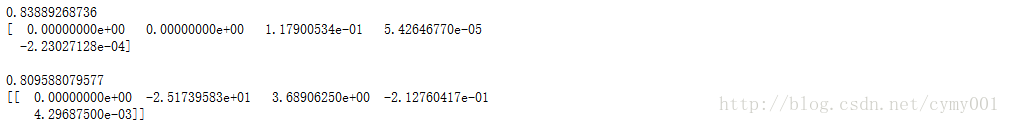
from sklearn.linear_model import Ridge
ridge_poly4=Ridge() #默认配置初始化Ridge
ridge_poly4.fit(X_train_poly4,y_train) #利用Ridge对四次多项式特征回归拟合
print(ridge_poly4.score(X_test_poly4,y_test)) #在测试集上进行评估
print(ridge_poly4.coef_) #输出Ridge模型的参数列表
print(np.sum(ridge_poly4.coef_**2))
print(' ')
print(regressor_poly4.coef_) #对比看一下不加正则化项的四次多项式回归拟合
print(np.sum(regressor_poly4.coef_**2))