吴恩达说“将引领下一波机器学习技术”的迁移学习到底好在哪?
AI技术年度盛会即将开启!11月8-9日,来自Google、Amazon、微软、Facebook、LinkedIn、阿里巴巴、百度、腾讯、美团、京东、小米、字节跳动、滴滴、商汤、旷视、思必驰、第四范式、云知声等企业的技术大咖将带来工业界AI应用的最新思维。
如果你是某个AI技术领域的专业人才,或想寻求将AI技术整合至传统企业业务当中,点击填写「2018 AI开发者大会注册信息表」,我们将从中挑选出20名相关性最高的幸运读者,送出单场分论坛入场券。
此外,如果你想与所有参会大牛充分交流沟通,点击阅读原文购票,使用优惠码:AI2018-DBY 购买两日通票,立减999元;此外大会还推出了1024定制票,主会+分会自由组合,精彩随心。大会嘉宾阵容和议题,请查看文末海报
作者 | Cloudera Fast Forward Labs
译者 | Jianjun ZHANG
编辑 | Jane
出品 | AI科技大本营
【导读】两年前,吴恩达在 NIPS 2016 的 Tutorial 上曾说“在监督学习之后,迁移学习将引领下一波机器学习技术商业化浪潮。”现实中不断有新场景的出现,迁移学习可以帮助我们更好地处理遇到的新场景。迁移学习到底有哪些优点,能够成为现在机器学习算法的新焦点?本文将通过与深度学习进行对比,让大家在应用层面了解迁移学习的原理及其优势。
前言
深度学习在许多很难用其它方法解决的问题上取得了长足的进步。深度学习的成功归功于它与传统的机器学习的几个关键不同点,这使得它在处理非结构化数据的时候能够大放异彩。如今,深度学习模型可以玩游戏,检测癌症,与人类交谈,以及驾驶汽车。
但是,使深度学习强大的这几个不同点同时也使得其成本巨大。你可能听说过深度学习的成功需要庞大的数据量,昂贵的硬件设施,甚至更加昂贵的精英工程人才。现在,一些公司开始对那些可以减少成本的创新想法和技术特别兴奋。比如多任务学习(Multi-task learning),这是一种可以让机器学习模型一次性从多个任务中进行学习的方法。这种方法的其中一种好处就是,可以减少对训练数据量的需求。
在这篇文章中,我们将会介绍迁移学习(transfer learning),一种可以让知识从一个任务迁移到另一个任务中的机器学习方法。迁移学习不需要为你的问题重新开发一个完全定制的解决方案,而是允许你从相关问题中迁移知识,以帮助你更轻松地解决您的自定义问题。通过迁移知识,你可以利用用于获取这些知识所需的昂贵资源,包括训练数据,硬件设备,研究人员,而这些成本并不需要你来承担。下面让我们看看迁移学习何时以及是怎样起作用的。
深度学习与传统机器学习的不同点
迁移学习并不是一项新技术,它也不是专门为深度学习服务的,但是鉴于最近在深度学习方面取得的进展,它很令人兴奋。所以首先,我们需要阐明深度学习究竟和传统的机器学习在哪些方面有所不同。
▌深度学习进行底层抽象
机器学习是机器自动学习把预测值或者标签分配给数值型输入(即数据)的一种方式。这里的难点是,如何确切地确定这个函数,使得其对于给定输入可以生成输出。不对函数添加任何限制条件的话,其可能性(复杂性)是无穷无尽的。为了简化这个任务,根据我们正在解决的问题的类型,相关领域的专业知识,或者简单的试错方法,我们通常会在函数上强加某种类型的结构。一种结构定义了某一类型的机器学习模型。
理论上,有无限种可能的结构可供选择,但在实践中,大多数机器学习用例可以通过应用少数几种结构中的其中一种来解决:线性模型,树的组合分类器,和支持向量机是其中的核心。数据科学家的工作就是从这一小组可能的结构中选择正确的结构。这些模型作为黑盒对象,可以从许多成熟的机器学习库中获得,并且只需几行代码即可训练。举个例子,你可以用 Python 的 scikit-learn 库像以下这样训练一个随机森林模型:
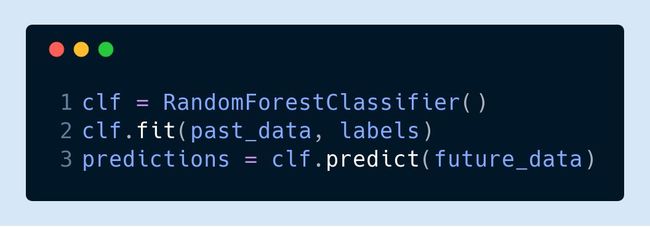
或者用 R 来训练一个线性回归模型:
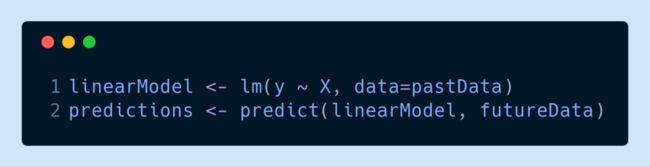
与此不同的是,深度学习在更加底层运行。深度学习不是从一小组的模型结构中进行选择,而是允许开发人员组成任意结构。构建块是一些模块或者层,可以将其想象成基本的基础数据转换。这意味着当我们应用深度学习时,我们需要打开黑盒子了解数据转换,而不是把它当做被算法固定的一堆参数。
这种做法使得我们可以构建更加强大的模型,但是同时它也给整个模型构建过程添加了一种全新的挑战。尽管深度学习社区已经发表了大量研究,到处都有实用的深度学习指南,或者一些经验之谈,如何有效地组合这些数据转换依然是一个很困难的过程。
下面我们考虑一个极其简单的卷积神经网络图像分类器,这里是用一个流行的深度学习库 PyTorch 来进行定义的。
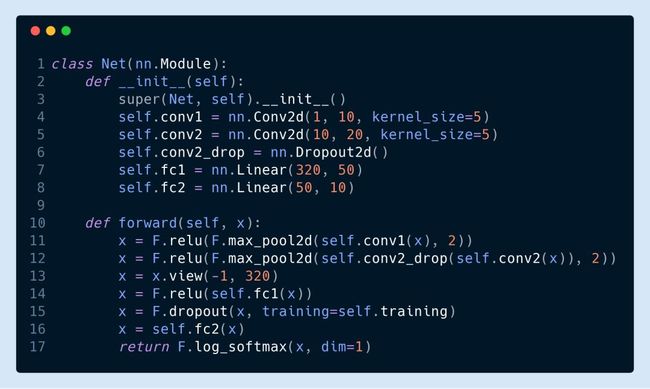
因为我们使用的是底层的构建块,我们可以轻松改变模型的某个单一部件(例如,将F.relu变为F.sigmoid)。这样做可以得到一个全新的模型架构,它可能会产生截然不同的结果,而且它的可能性,毫不夸张地说,是无止境的。
▌深度学习还没有被充分地理解
即使给定了一个固定的神经网络架构,训练它也是众所周知的极其困难。首先,深度学习的损失函数通常不是凸函数,这意味着训练并不一定产生最优的可能解。第二,深度学习现在还是非常新的技术,它的许多组成部分仍未被充分理解。举个例子,批标准化(Batch Normalization)最近备受关注,因为似乎将其包含在某些模型中是取得良好结果的关键,但是专家无法就其原因达成一致。研究人员 Ali Rahimi 最近在一场机器学习会议上甚至把深度学习与炼金术相提并论,引发了一场论战。
▌自动特征工程
深度学习的复杂性促进了一门叫表示学习(representation learning)的技术的发展,这也是为什么经常有人说神经网络做的是“自动特征工程”。简单来说就是,我们不是让人类来手动从数据集中提取有效特征,而是构建一个模型,让模型可以自己学习对于当前任务来说哪些是需要的和有用的特征。把特征工程的任务交给模型来处理非常有效,但是代价是模型需要庞大的数据量,也因此需要庞大的计算能力。
▌你可以做什么?
和其他机器学习方法相比,深度学习太过于复杂,看上去似乎无法将其整合到你的业务中。对于那些资源有限的组织机构来说,这种感觉更加强烈。
对于那些需要走在前沿的组织机构来说,可能的确需要聘请专家和购买专业的硬件设施。但是很多情况下这不是必需的。有方法可以让你不需要进行大量的投资就可以有效地应用深度学习技术。这里就是迁移学习可以大展拳脚的地方了。
迁移学习可以让知识从一个机器学习模型迁移到另一个模型上。这些模型可能是对模型结构进行了长年研究、用相当多数据集对模型进行训练、用数以年计的计算时间对模型进行优化而得到的结果。利用迁移学习,你不需要承担上面说的任何成本就能获得这项工作的大部分好处!
什么是迁移学习
大多数机器学习任务始于零知识,意思是它的结构和模型的参数是从随机猜测开始的。当我们说模型是从头开始学习的时候,意思也是如此。
随机猜测开始训练的一个猫检测模型。通过它见过的许多不同的猫,该模型从中整合出相同的模式,逐渐学习到猫是什么。
在这种情况下,该模型学习到的所有内容都来自于你展示给它的数据。但是,这是解决问题的唯一方法吗?在某些情况下,看上去的确如此。
猫检测模型在不相关的应用中,例如欺诈检测,很有可能没有什么用处。它只知道如何应付猫的图片,而不是信用卡交易。
但是在某些情况下,我们似乎可以在不同任务之间共享信息。
猫检测模型在相关任务中作用很大,例如猫的脸部定位。该检测器已经知道怎么检测猫胡子,鼻子,以及眼睛,所有这些对于定位猫的脸部都很有用处。
这就是迁移学习的本质:采用一种模型,学习如何很好地完成某项任务,将其部分或者所有知识迁移到一个相关的任务。
想想我们自己的学习经验,就会发现这其实很有道理:我们经常迁移以往习得的技能,这样可以更快地学习新的技能。举个例子,学过投掷棒球的人不需要重新学习抛东西的机制就能很好地学习到怎么扔一个足球。这些任务本质上是相通的,能够处理其中一件任务的话自然而然可以把学习到的能力迁移到另一项任务。
在机器学习领域,可能过去 5 年最好的例子就是计算机视觉领域。现在几乎没人会从头开始训练一个图像模型。相反,我们会从一个预训练好的模型开始,这个模型已经知道怎么区分一些简单的对象,例如猫,狗,还有雨伞。学习区分图像的模型首先学习如何检测一些通用图像特征,例如边缘,形状,文本,以及脸部。预训练模型具有以上这些的基本技能(还有更加具体的技能,例如区分狗和猫的能力)。
此时,预训练的分类模型可以通过添加层或者在一个新的数据集上重新训练,来继承那些花费巨大而获得的基本技能,然后将其延伸到新的任务。这就是迁移学习。
这种方法的好处很明显。
▌迁移学习训练数据量需求量更小
当你在一个与猫相关的新任务中重复使用你最喜爱的猫检测模型时,你的模型已经拥有了“一百万只猫的智慧”,这意味着你不需要再使用那么多的猫图片来训练新任务了。减少训练数据量可以让你在只有很少数据,或者要获得更多数据的成本过高或者不可能获得更多数据的情况下也能训练,同时可以让你在比较廉价的硬件设施上更快地训练模型。
▌迁移学习训练模型泛化能力更强
迁移学习可以改进模型的泛化能力,或者说增强其在非训练数据上分类良好的能力。这是因为在训练预训练模型时,是有目的性地让模型可以学习到对相关任务都很有用的通用特征。当模型迁移到一个新任务时,它将很难过拟合新的训练数据,因为它将仅从一个很一般的知识库中继续学习而已。构建一个泛化能力强的模型是机器学习中最难以及最重要的部分之一。
▌迁移学习训练过程更加鲁棒
从一个预训练的模型开始,也可以避免训练一个带有数百万参数的复杂模型,这个过程非常令人沮丧,非常不稳定,而且令人困惑。迁移学习可以将可训练参数的数量减少多达 100%,使得训练更稳定,而且更容易调试。
▌迁移学习降低深度学习的入门门槛
最后,迁移学习降低深度学习的门槛,因为你不需要成为专家就能获得专家级的结果。举例来说,流行的图像分类模型 Resnet-50,这个特定的结构是怎么选择的呢?这是许多深度学习专家的多年研究和实验的结果。这个复杂的结构中包含有 2500 万个权重,如果没有对这个模型中各个部件的深入了解,从头优化这些权重可以说是几乎不可能的任务。幸运的是,有了迁移学习,你可以重用这个复杂的结构,以及这些优化过的权重,因此显著降低了深度学习的入门门槛。
多任务学习又是什么?
迁移学习是用于训练机器学习模型的知识共享技术的其中一种,已被证明是非常有效的。目前,知识共享技术中最有趣的两种就是迁移学习和多任务学习。在迁移学习中,模型首先在单个任务中进行训练,然后可以用于相关任务的起始点。在学习相关任务时,原始的被迁移模型会学习如何专门处理新的任务,而不需要担心会不会影响其在原来任务上的效果。而在多任务学习中,单个模型一次性学习处理多个任务,对模型的性能评估则取决于它学习之后能够多好地完成这些任务。后续我们也会分析讨论更过有关多任务学习的好处以及其何时能起作用。
结论
迁移学习是一项知识共享技术,其可以减少构建深度学习模型时对训练数据量,计算能力,以及工程人才的依赖。由于深度学习可以提供与传统机器学习相比的显著改进,迁移学习成为一项必不可少的工具。
想知道更多机器学习、深度学习、强化学习、迁移学习这些算法是如何在具体应用和业务中发挥作用的,我们会在 2018 AI开发者大会上进行更多分享。感兴趣的同学们一定要关注我们哦!
2018 AI开发者大会
2018 AI开发者大会是一场由中美人工智能技术高手联袂打造的AI技术与产业的年度盛会!是一场以技术落地为导向的干货会议!大会设置了10场技术专题论坛,力邀15+硅谷实力讲师团和80+AI领军企业技术核心人物,多位一线经验大咖带你将AI从云端落地。
大会日程以及嘉宾议题请查看下方海报(点击查看大图)
