Spark集群中Mapper端、Reducer端内存调优
第23章Spark集群中Mapper端、Reducer端内存调优
本章主要讲解如下内容:
l Spark集群中Mapper端内存调优最佳实践;
l Spark集群中Reducer端内存调优最佳实践。
22
23
23.1 Mapper端内存调优
本节讲解Spark集群中Mapper端内存使用详解以及性能调优最佳实践。
23.1.1 Spark集群中Mapper端内存使用详解
Spark集群Shuffle分为2部分:Mapper端和Reducer端。本节讲解Spark集群中Mapper端内存使用。Spark集群中的Shuffle是非常重要的,Shuffle的特殊在于我们依赖于所有的数据,RDD的依赖是后面的RDD依赖前面的RDD,当发生Shuffle RDD的时候,Reducer端的RDD的每一个Partition依赖于父RDD的所有的Partition,不是固定依赖于某一个RDD的数据,或者某几个Partition的数据,它的依赖是不确定的,因此是依赖于所有的数据。假如有1百万个Partition,我们不会知道依赖于其中的50万个Partition,还是其中的1个Partition,这个时候我们从所有Partition的角度来考虑,这个时候就产生了Shuffle网络通信。
Spark集群中Mapper端内存性能调优示意图如图 23- 1所示:
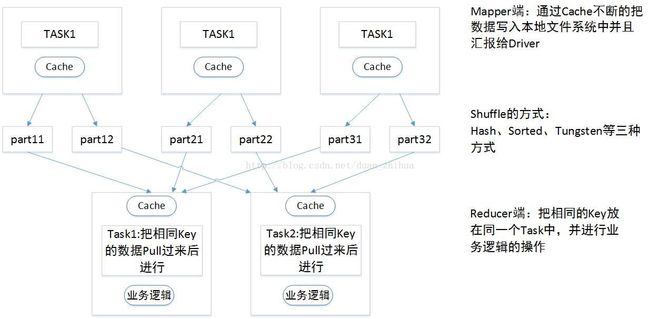
图 23- 1Spark集群中Mapper端内存性能调优示意图
假设Mapper端有3个Task:Task1、Task2、Task3,Reducer端有2个Task:Task1、Task2,数据传输到Reducer端的时候首先进行Mapper端的处理,Mapper端处理很简单,
Mapper端有一个Cache缓存,Mapper端会产生文件,这里将文件分成2部分,分别为:part11、part12;part21、part22;part31、part32;Shuffle可以是Hash、Sorted、Tungten的三种方式(其中Hash方式在Spark 2.2.0中已不使用)。数据从Mapper Cache缓存写入文件中。Mapper端有一个缓存,根据Redcuer端的需要,对数据分成不同的部分,part11、part12可能在一个文件中,也可能在2个文件中。然后在Reducer端抓到属于自己的数据进行reduce操作,把相同Key的数据Pull过来以后进行reduce操作,Reducer端操作的时候也有一个缓存区,是定义业务逻辑运行的地方。
Mapper端:通过Cache不断的把数据写入到文件系统中并汇报给Driver,Driver需知道把数据写在什么地方。
Reducer端:把相同的Key放在同一个Task中,并进行业务逻辑的操作。Reducer端抓数据的时候也有一个小的缓存区。
现在针对Shuffle Mapper端的过程,Shuffle Mapper端怎么进行性能调优?性能调优点在什么地方?Mapper端内存性能调优点在于Cache:假设Mapper端的数据非常非常大,假设有1百万个Key,Mapper端的Cache大小是16K,如果是16K,1百万个Key进行操作,假设每个Task的数据是16G,这个时候除以16K,将是一个非常恐怖的数字,恐怖的地方在于要进行若干次的磁盘读写。
至于Reducer端的调优:Reducer端将数据抓过来,如果缓存空间不够,将把数据Spill到磁盘上。Reducer端也有一个Cache缓存,在Reducer端进行Cache的调优。(具体在23.2 章节Spark集群中Reducer端内存调优最佳实践进行讲解。)
23.1.2 Spark集群中Mapper端内存性能调优最佳实践
在Spark集群中Mapper端内存性能调优示意图 23- 1所示的流程中:我们怎么知道Mapper端要不要调优?什么时候进行Mapper端调优?
这个要看Log和Web UI上面的信息来判断是否需要调整参数。Log上肯定可以看到信息;从Web UI的角度讲,可以看不同的Stage分布在什么地方,读写数据的量等等内容。
Spark集群中Mapper端内存性能问题:Mapper端的Cache:如果说Cache设置的大小不恰当,可能产生极大量磁盘的访问操作,因为要频繁的往本地磁盘写数据;
针对Spark集群中Mapper端内存性能问题:Mapper端的性能调优参数spark.shuffle.file.buffer,默认大小是32K,我们要根据数量和并发量来适当调整该参数,尽量减少过于频繁的磁盘访问操作,开始是32K,后面可以调整成为64K,128K等等,需观察性能效果;
23.2 Spark集群中Reducer端内存调优最佳实践
本节讲解Spark集群中Reducer端内存使用详解以及性能调优最佳实践。
23.2.1 Spark集群中Reducer端内存使用详解
Spark集群Shuffle分为2部分:Mapper端和Reducer端。本节讲解Spark集群中Reducer端内存使用。在进行Shuffle的时候,Mapper端有一些文件按照某种规则给Reducer端,在整个Shuffle的过程中,Mapper端有很多任务,Reducer端也有很多任务,Shuffle有很多不同的类型,不同的类型的核心区别在于Mapper端的数据怎么交给Reducer端的数据。
Spark集群中Reducer端内存性能调优示意图如图 23- 2所示:
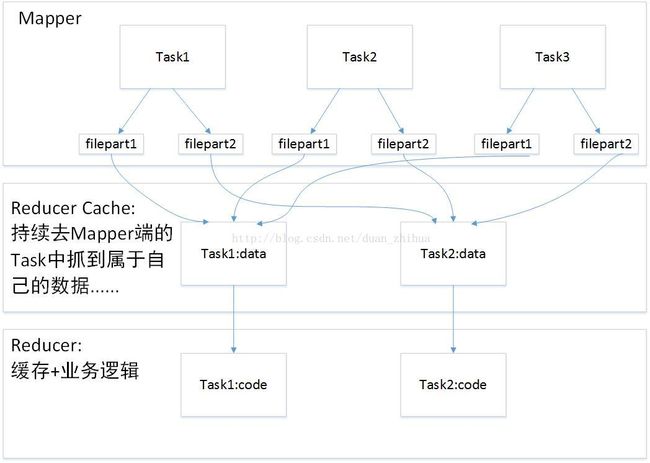
图 23- 2Spark集群中Reducer端内存性能调优示意图
假设在Mapper端有3个Task:Task1、Task2、Task3;在Reducer端有2个任务:Task1、Task2。
从Reducer端的角度考虑,每个Task生成几个部分的文件,因为在Shuffle的时候,有不同的Shuffle策略:Hash的方式,排序的方式等等。
在Mapper端和Reducer端中间我们加一个Cache缓存,Reducer端的Task有2个,所以文件会有2个小部分的文件。filepart1、filepart2。这里不是指第一个文件,第二个文件,而是文件的第一部分,第二部分。Mapper端Task的数据有2部分,是因为Reducer端有2个并行的Task,不同的Shuffle策略会说明怎么分这2部分。
Cache缓存层分别从不同Task的filepart1、filepart2抓到属于自己的数据,把属于自己的数据拿到Cache缓存层。然后把Cache中的数据抓到Reducer端,在Redcuer端里面对RDD进行一系列业务逻辑的处理。
梳理一下整个流程:
整个Spark的作业每个Job分成Mapper端、Reducer端,由于是链式表达式,可能很多Mapper端、Reducer端是天生的,其实可以看一个很长的链条,但我们这里只要看一个Mapper、Reducer。Mapper端产生数据会分成若干个部分,分成几部分是由Reducer端的并行度决定的,这里分成filepart1,filepart2,也可能是在一个文件中,例如排序的方式就在一个文件或者是Hash的方式,采用了文件压缩。Reducer端去获取具体数据的时候,Reducer端的前端有一个缓存层Cache,持续从Mapper端的Task输出中不断的去抓到属于自己的数据,Reducer端通过transformation对业务逻辑代码对抓到的数据进行处理。
这个是整个过程,大家思考一下,Spark集群中Reducer端在哪些环节可能出问题?
第一个是Reducer端的缓存层:我们在Mapper端不断的输出数据,数据可能很多,也可能很少,因为根据不同的作业以及作业不同的阶段;Reducer端要运行Task,是否要等到Mapper端将所有的数据都写到磁盘中之后,Reducer端才向Mapper端去抓数据?不是的!这里是一边Shuffle一边处理,在进行Shuffle的过程中,抓数据中间有一个缓冲层,就像从磁盘中读取一个文件也会有一个缓存层,所以我们不是等Mapper端把所有的数据都放到filepart1,filepart2才处理,而是数据存入一点,就读取一点。我们把不同类型的数据聚合放到缓存中,然后Reducer端的Task的代码进行业务处理。
一边读取数据一遍处理,那Reducer端最多能拉取多少数据?由谁来决定?这个由缓存层决定的!在Reducer端的代码部分,代码是基于缓冲层处理数据的。缓存层的大小一般有多大?96M、48M、24M?这里缓存层的大小是指每个Task的缓存层的大小。96M、48M.....或者更大?24M...或者更小?这里每个Task有48M的缓存。
第二个是Reducer端的堆大小:我们从Mapper端抓取的数据先放到缓冲层,然后才用我们的Task执行我们抓到的数据,那Reducer端执行级别默认情况下的Task堆的大小是多少?默认情况下堆大小为20%的空间,可以进行调整。
如果Reducer端的缓存层的数据特别大,会不会有问题?一般情况下,Mapper端的数据不是特别多,可能达不到48M,或者是配置的96M,每次计算的时候发现是5M或者10M,一般情况下不会出问题。但如果Mapper端的数据特别特别大,Reducer端抓数据到自己的缓存层的时候,每一次我们的缓存层都填满,例如48M, 这个时候再加上Reducer端Task运行的时候分配的对象的这些代码,就有可能导致大量的对象创建,大量的对象创建的结果是OOM,Reducer端就发生了OOM。
在企业生产环境几乎一定会遇到这个问题,读者思考一下怎么办?可能有人提出增加executor、增加内存,但在实际生产环境中,资源被严格限制,所以先从我们知识技能的层面,在不改变资源的情况下,考虑我们如何去处理。这个时候比较简单的方式就是将Reducer端的Cache层减少。例如原先缓存层是48M发生了OOM,将参数调整成24M就行了。这是最简单最直接的解决方案。先让程序跑起来,然后才让程序跑的更快。这个想法跟平时单机版本的想法完全一样,如果单机版本发现OOM,是调大缓存大小还是调小缓存大小?确实要调小缓存大小。例如:单机版本中分配一个很大的数组集,就会造成oom,那把数组改小就可以了。
23.2.2 Spark集群中Reducer端内存性能调优最佳实践
Spark集群中Reducer端内存性能调优最佳实践:
问题1:Reducer端的业务逻辑(Business Logic)运行的空间,如果说空间分配
不够,业务逻辑运行的时候被迫把数据Spill到磁盘上面,一方面造成了业务逻辑处理的时候需要读写磁盘,另外一方面也会造成不安全(数据读写故障)
针对问题1调优:Reducer端的性能调优参数spark.shuffle.memoryFraction默认大小是0.2,Reducer端的业务逻辑运行占用Executor的内存大小的20%,一个额外的说明是很多公司的Executor中线程的并行度在5个左右,调整的时候可以从0.2调到0.3、0.4等。调整的越大,Spill到磁盘的次数就越少,次数越少那从磁盘中读取文件的时候数量也会越小。
问题2:发生Reducer端的OOM,Reduce端如果出现OOM,一般由于内存中数据太多,无法容纳活跃的对象。
针对问题2调优:调小Reducer端的缓存层。因为分配的内存有限,如果占用了太多的缓存,将导致太多的对象数据的产生,这个时候会出现OOM,将缓存层减少,OOM的症状就极有可能消失。这个事情也有代价:缓存层变小了,那向Mapper层拉取数据的次数变多了,Shuffle的次数变得更多了,也就是性能降低。那是让程序性能降低跑起来,还是根本跑不起来?这个肯定是让程序先跑起来,然后慢慢再调,如增加executor,分配更多的内存。如果内存充足,可以调大缓存。
如果发生Reducer端的OOM,可以减少每个Reduce Task的缓存的大小,例如从默认的48M降低到24M,这样让程序可以从OOM崩溃的状态到可以运行的状态。
一个额外的调优技巧:如果内存足够大,可以增加缓存的大小,例如从48M提升到96M,这样可以减少网络传输的次数从而提高性能。
配置参数是spark.reducer.maxSizeInFlight。
问题3:shuffle file not found的问题:Shuffle file not found找不到,原因有可能是GC,无论是Minor GC还是final GC,只要有GC,就有可能在map端GC的时候我们无法把数据抓过来。
针对问题3调优:一般情况下当Executor进行GC的时候,所有的线程都停止工作,当然包括进行数据传输的Netty中的线程也会停止工作,所以就暂时无法获取数据。
当Reducer端根据Driver端提供的信息到Mapper中指定的位置去获取属于自己的数据的时候,首先会去定位数据所在的文件,而此时可能发生shufle file not found的错误。这个错误的出现一般是由于Mapper端正在进行GC,然后我们去请求数据的时候没有响应,spark.shuffle.io.maxRetries=3 spark.shuffle.io.retryWait =5s 默认情况下15s中还没有拉到属于自己的数据就会出现shufflefile not found的错误。
解决办法是调大上述参数:
spark.shuffle.io.maxRetries =30
spark.shuffle.io.retryWait =30s