cs231 循环神经网络RNN (计算图)
cs231 循环神经网络RNN (计算图)
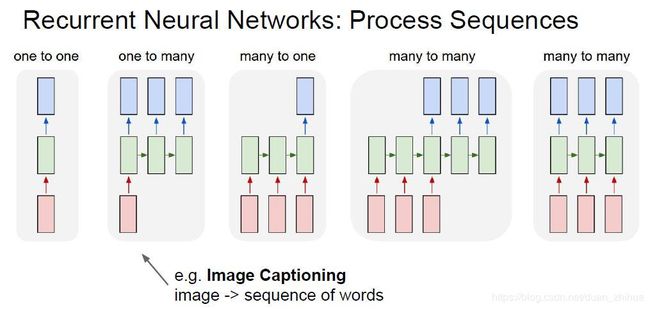
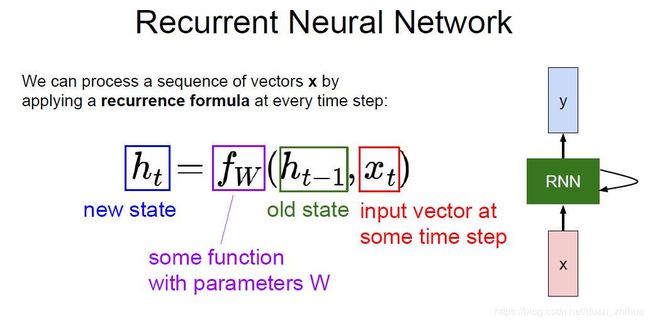


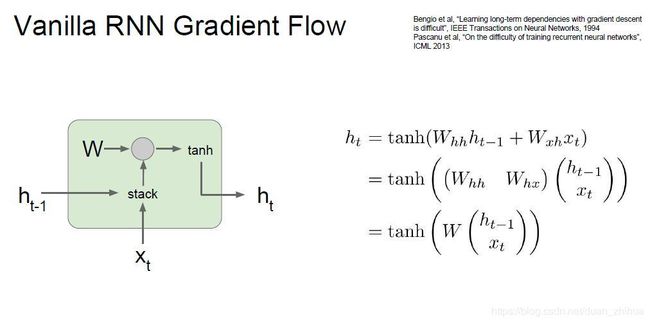

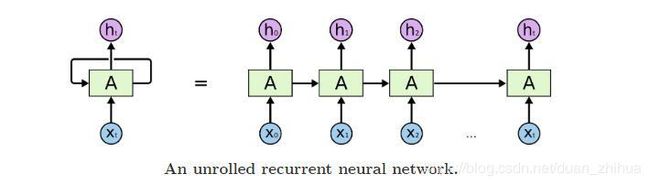
from __future__ import print_function, division
from builtins import range
import numpy as np
"""
This file defines layer types that are commonly used for recurrent neural
networks.
"""
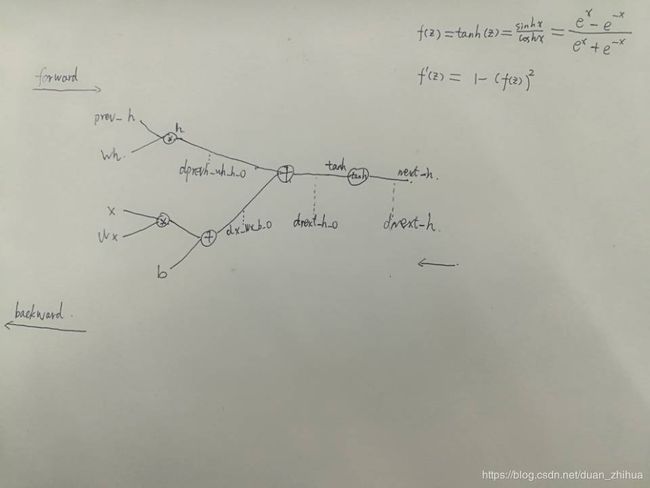
def rnn_step_forward(x, prev_h, Wx, Wh, b):
"""
Run the forward pass for a single timestep of a vanilla RNN that uses a tanh
activation function.
The input data has dimension D, the hidden state has dimension H, and we use
a minibatch size of N.
Inputs:
- x: Input data for this timestep, of shape (N, D).
- prev_h: Hidden state from previous timestep, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,)
Returns a tuple of:
- next_h: Next hidden state, of shape (N, H)
- cache: Tuple of values needed for the backward pass.
"""
next_h, cache = None, None
##############################################################################
# TODO: Implement a single forward step for the vanilla RNN. Store the next #
# hidden state and any values you need for the backward pass in the next_h #
# and cache variables respectively. #
##############################################################################
#pass
#x:(N, D);prev_h:(N, H);Wx: (D, H) Wh:(H, H) b:(H,)
h=np.dot(prev_h,Wh) # (N,H) (H,H)--->(N,H)
out =np.dot(x,Wx) + b # (N,D) (D,H) -->(N,H)
next_h = out + h #(N,H)
next_h=np.tanh(next_h)#(N,H)
cache = (x, prev_h, Wx, Wh, next_h)
##############################################################################
# END OF YOUR CODE #
##############################################################################
return next_h, cache
def rnn_step_backward(dnext_h, cache):
"""
Backward pass for a single timestep of a vanilla RNN.
Inputs:
- dnext_h: Gradient of loss with respect to next hidden state, of shape (N, H)
- cache: Cache object from the forward pass
Returns a tuple of:
- dx: Gradients of input data, of shape (N, D)
- dprev_h: Gradients of previous hidden state, of shape (N, H)
- dWx: Gradients of input-to-hidden weights, of shape (D, H)
- dWh: Gradients of hidden-to-hidden weights, of shape (H, H)
- db: Gradients of bias vector, of shape (H,)
"""
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
##############################################################################
# TODO: Implement the backward pass for a single step of a vanilla RNN. #
# #
# HINT: For the tanh function, you can compute the local derivative in terms #
# of the output value from tanh. #
##############################################################################
#pass
#dnext_h: (N, H)
#dx:(N, D);dprev_h:(N, H);dWx: (D, H) dWh:(H, H) db:(H,)
#f(z) = tanh(z) 求导:f(z)' = 1 − (f(z))^2
x, prev_h, Wx, Wh, next_h =cache
dnext_h_o = dnext_h * (1-next_h**2) #(N, H)
dprevh_Wh_h_o = dnext_h_o #(N, H)
dx_Wx_b_o =dnext_h_o #(N, H)
db = np.sum(dx_Wx_b_o,axis=0) #(N, H)--->(H,)
dx = np.dot(dx_Wx_b_o , Wx.T) #(N, H) (D, H).T--->(N,D)
dWx = np.dot(x.T,dx_Wx_b_o ) # (N, D).T (N, H) ---- (D, H)
#dprev_h = np.dot( dprevh_Wh_h_o ,Wh) # (N, H) (H, H) ---> (N, H) 误差为1
dprev_h = np.dot( dprevh_Wh_h_o ,Wh.T) # (N, H) (H, H) ---> (N, H)
#dWh = np.dot( dprevh_Wh_h_o.T , prev_h) #(N, H).T (N, H) -->(H, H) 误差为1
dWh = np.dot( prev_h.T , dprevh_Wh_h_o) #(N, H).T (N, H) -->(H, H)
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dprev_h, dWx, dWh, db
def rnn_forward(x, h0, Wx, Wh, b):
"""
Run a vanilla RNN forward on an entire sequence of data. We assume an input
sequence composed of T vectors, each of dimension D. The RNN uses a hidden
size of H, and we work over a minibatch containing N sequences. After running
the RNN forward, we return the hidden states for all timesteps.
Inputs:
- x: Input data for the entire timeseries, of shape (N, T, D).
- h0: Initial hidden state, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,)
Returns a tuple of:
- h: Hidden states for the entire timeseries, of shape (N, T, H).
- cache: Values needed in the backward pass
"""
h, cache = None, None
##############################################################################
# TODO: Implement forward pass for a vanilla RNN running on a sequence of #
# input data. You should use the rnn_step_forward function that you defined #
# above. You can use a for loop to help compute the forward pass. #
##############################################################################
#pass
N, T, D =x.shape
hidden = h0
hiddens=[]
for i in range(T):
input = x[:,i,:] # (N,i,D)----> (N,D)
hidden, cache = rnn_step_forward(input, hidden, Wx, Wh, b)
#hidden :(N,H)
hiddens.append(hidden)
h = np.stack(hiddens,axis=1) # (N,T,H)
cache =(x, h0, Wh, Wx, b, h)
##############################################################################
# END OF YOUR CODE #
##############################################################################
return h, cache
def rnn_backward(dh, cache):
"""
Compute the backward pass for a vanilla RNN over an entire sequence of data.
Inputs:
- dh: Upstream gradients of all hidden states, of shape (N, T, H).
NOTE: 'dh' contains the upstream gradients produced by the
individual loss functions at each timestep, *not* the gradients
being passed between timesteps (which you'll have to compute yourself
by calling rnn_step_backward in a loop).
Returns a tuple of:
- dx: Gradient of inputs, of shape (N, T, D)
- dh0: Gradient of initial hidden state, of shape (N, H)
- dWx: Gradient of input-to-hidden weights, of shape (D, H)
- dWh: Gradient of hidden-to-hidden weights, of shape (H, H)
- db: Gradient of biases, of shape (H,)
"""
dx, dh0, dWx, dWh, db = None, None, None, None, None
##############################################################################
# TODO: Implement the backward pass for a vanilla RNN running an entire #
# sequence of data. You should use the rnn_step_backward function that you #
# defined above. You can use a for loop to help compute the backward pass. #
##############################################################################
#h: (N,T,H)
x, h0, Wh, Wx, b, h = cache
_, T, _ = dh.shape
dx = np.zeros_like(x)
dWx = np.zeros_like(Wx)
dWh = np.zeros_like(Wh)
db = np.zeros_like(b)
dprev_h = 0
for i in range(T):
t = T - 1 - i
xt = x[:, t, :] #(N, T, D)--->(N,D)
dht = dh[:, t, :]#(N, T, H)--->(N,H)
if t > 0:
prev_h = h[:, t-1, :] # # (N,T,H) --->(N,H)
else:
prev_h = h0 #(N, H)
next_h = h[:, t, :]
#dht:从某一时刻的 loss 传递到该时刻隐状态的梯度值
#dprev_h:从后一时刻隐状态传递到该时刻隐状态的梯度值
dx[:, t, :], dprev_h, dwx, dwh, db_ = rnn_step_backward(dht + dprev_h, (xt, prev_h, Wx, Wh, next_h))
dWx += dwx
dWh += dwh
db += db_
dh0 = dprev_h
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dh0, dWx, dWh, db
《Circle of Life》
Nants ingonyama bagithi Baba
Sithi uhm ingonyama
Nants ingonyama bagithi baba
Sithi uhhmm ingonyama
Ingonyama
Siyo Nqoba
Ingonyama
Ingonyama nengw' enamabala
from the say we arrive on the planet
and blinking,step into the sun
there's more to see than can ever be seen
more to do than can ever be done
there's far too much to take in here
more to find than can ever be found
but the sun rolling high
through the sapphire sky
keeps great and small on the endless round
it's the circle of life
and it moves us all
through despair and hope
through faith and love
till we find our place
on the path unwinding
in the circle
the circle of life
it's the circle of life
and it moves us all
through despair and hope
through faith and love
till we find our place
on the path unwinding
in the circle
the circle of life