爬虫用Cookie登录网页
最近在爬取豆瓣的数据时发现了一些问题。因为要做一个爬虫,爬取用户读过的书以及对书的评分。但是在进行网页的分析时却出现了点问题。
当浏览器打开用户读书记录的链接时是没有任何问题的,但是用requests库来进行网页爬取时却出现了问题。
以https://book.douban.com/people/…/collect这个链接为例,获取这个链接的html源码,一般都是这样写:
import requests
url = 'https://book.douban.com/people/.../collect'
r = requests.get(url)
print(r.text)运行结果却是:
<html>
<head><title>403 Forbiddentitle>head>
<body bgcolor="white">
<center><h1>403 Forbiddenh1>center>
<hr><center>nginxcenter>
body>
html>网页却能正常访问:
经过百度后发现,这是因为在爬取网页时没有传入Cookie,服务器不能识别用户身份,网页不能显示给没有用户身份的请求,所以网页源码被隐藏了。
因此,要在请求时加上Cookie,如何获取Cookie?
不能https://book.douban.com/people/…/collect这个链接中直接获取Cookie,因为这个链接在缺少Cookie的情况下根本不能正常访问。但是可以登录豆瓣官网来获取Cookie,登录豆瓣官网不需要Cookie。
import urllib.request
import http.cookiejar
/*设置文件来存储Cookie*/
filename = 'cookie.txt'
/*创建一个MozillaCookieJar()对象实例来保存Cookie*/
cookie = http.cookiejar.MozillaCookieJar(filename)
/*创建Cookie处理器*/
handler = urllib.request.HTTPCookieProcessor(cookie)
/*构建opener*/
opener = urllib.request.build_opener(handler)
response = opener.open("https://www.douban.com/")
cookie.save(ignore_discard=True, ignore_expires=True)打开cookie.txt文件会发现cookie已被保存。
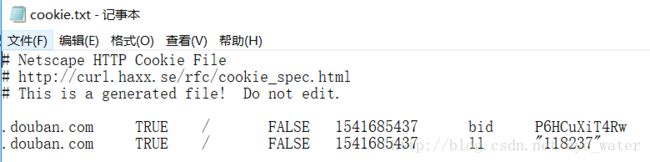
这样在访问用户读过的书的链接时,从文件中读取Cookie,在进行网页请求时加上Cookie就行了。
import requests
import http.cookiejar
cookie = http.cookiejar.MozillaCookieJar()
/*加载Cookie*/
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
url = 'https://book.douban.com/people/.../collect'
r = requests.get(url, cookies=cookie)
print(r.text)运行结果:
<html lang="zh-cmn-Hans" class=" book-new-nav">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>
读过的书(219)
title>
<script>!function(e){var o=function(o,n,t){var c,i,r=new Date;n=n||30,t=t||"/",r.setTime(r.getTime()+24*n*60*60*1e3),c="; expires="+r.toGMTString();for(i in o)e.cookie=i+"="+o[i]+c+"; path="+t},n=function(o){var n,t,c,i=o+"=",r=e.cookie.split(";");for(t=0,c=r.length;tif (n=r[t].replace(/^\s+|\s+$/g,""),0==n.indexOf(i))return n.substring(i.length,n.length).replace(/\"/g,"");return null},t=e.write,c={"douban.com":1,"douban.fm":1,"google.com":1,"google.cn":1,"googleapis.com":1,"gmaptiles.co.kr":1,"gstatic.com":1,"gstatic.cn":1,"google-analytics.com":1,"googleadservices.com":1},i=function(e,o){var n=new Image;n.οnlοad=function(){},n.src="https://www.douban.com/j/except_report?kind=ra022&reason="+encodeURIComponent(e)+"&environment="+encodeURIComponent(o)},r=function(o){try{t.call(e,o)}catch(e){t(o)}},a=/]+)/gi ,g=/http:\/\/(.+?)\.([^\/]+).+/i;e.writeln=e.write=function(e){var t,l=a.exec(e);return l&&(t=g.exec(l[1]))?c[t[2]]?void r(e):void("tqs"!==n("hj")&&(i(l[1],location.href),o({hj:"tqs"},1),setTimeout(function(){location.replace(location.href)},50))):void r(e)}}(document);
script>这样就成功地得到了html源码,就可以进行分析了。
参考文章:静觅 » Python爬虫入门六之Cookie的使用
PS:链接还是去豆瓣官网上找一个用户读过的书的链接吧。
如果感觉每次读取文件比较麻烦,还有另一种方式伪造Cookie!