
普通糗事百科爬虫(2019.5.24成功)
cd E:\FHLAZ\Python37\Anaconda3\scrapy_document\first
scrapy startproject first#新建一个爬虫项目
cd .\first\#进入这个爬虫项目
scrapy genspider -t basic qsbk qiushibaike.com#爬取名为qsbk域名为qiushibaike.com的爬虫文件
https://www.qiushibaike.com/
scrapy crawl qsbk --nolog#运行qsbk的文件
再pycharm里面,首先设置items,提取内容content 和链接link。通过scrapy.Field()创建。
然后pipeline,我们提取的是段子的内容,由于一页有多个段子,所有要有for循环。
然后是qsbk,很明显,我们用到了items的文件,所以我们与要导入items。from first.items import FirstItem。通过xpath提取所需要的内容response.xpath("//div[@class='recmd-tag']/text()").extract()。
再然后再pipelines里面加入for循环。
这个时候还没有加浏览器,不过可以爬取一下了,报错:

错误原因:user-agent问题。 没有合适的请求头,被直接ban掉。

items.py
import scrapy
class FirstItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
link=scrapy.Field()
qsbk.pu#没加浏览器
# -*- coding: utf-8 -*-
import scrapy
from first.items import FirstItem
from scrapy.http import Request
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
start_urls = ['http://qiushibaike.com/']
# def start_request(self):
# ua = {"Use-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
# yield Request('https://www.qiushibaike.com/',headers=ua)
def parse(self, response):
it=FirstItem()
it["content"] = response.xpath("//div[@class='recmd-content']/text()").extract()
it["link"] = response.xpath("//a[@class='recmd-content/@href']").extract()
yield it # 返回 不能用return return无法执行多次 生成和返回
qsbk.py#加了浏览器
# -*- coding: utf-8 -*-
import scrapy
from first.items import FirstItem
from scrapy.http import Request
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
'''
start_urls = ['http://qiushibaike.com/']
'''
def start_request(self):
ua = {"Use-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
yield Request('https://www.qiushibaike.com/',headers=ua)
def parse(self, response):
it=FirstItem()
it["content"] = response.xpath("//div[@class='recmd-content']/text()").extract()
it["link"] = response.xpath("//a[@class='recmd-content/@href']").extract()
yield it # 返回 不能用return return无法执行多次 生成和返回
pipelines.py
class FirstPipeline(object):
def process_item(self, item, spider):
for i in range(0,len(item["content"])):
print(item["content"][i])
print(item["link"][i])
return item
嗯,失败到让我放弃,这个糗事百科第一阶段的失败是还没有到pycharm里面的时候,我没有爬取成功,但最后成功了,现在是第二阶段的失败,普通的浏览器阶段。我在不断地调试,发现ua部分地代码没有成功运行。因为def start_request(self):写错了,应该是def start_requests(self):.少了一个s。接下来我再试试。
参考:
https://blog.csdn.net/mouday/article/details/80776030
又说是ua有问题。
我再试试。
台式机上没成功,我回来在笔记本上重新试了一次。
cd D:\FHLAZ\Python37\scrapy_document\fanhl
scrapy startproject first#新建一个爬虫项目
cd .\first\
scrapy genspider -t basic qsbk qiushibaike.com#爬取名为qsbk域名为qiushibaike.com的爬虫文件
scrapy crawl qsbk --nolog#运行qsbk的文件
代码:
items.py 这部分内容没有变
import scrapy
class FirstItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
link = scrapy.Field()
pipelines.py这部分内容也没有变
class FirstPipeline(object):
def process_item(self, item, spider):
for i in range(0, len(item["content"])):
print(item["content"][i])
print(item["link"][i])
return item
setting.py 修改了三个地方
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'first.pipelines.FirstPipeline': 300,
}
qsbk.py
# -*- coding: utf-8 -*-
import scrapy
from first.items import FirstItem
from scrapy.http import Request
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
'''
start_urls = ['http://qiushibaike.com/']
'''
def start_requests(self):
ua = {"Use-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
yield Request('http://qiushibaike.com/', headers=ua)
def parse(self, response):
it = FirstItem()
it["content"] = response.xpath('//a[@class="recmd-content"]/text()').extract()
it["link"] = response.xpath('//a[@class="recmd-content"]/@href').extract()
yield it # 返回 不能用return return无法执行多次 生成和返回
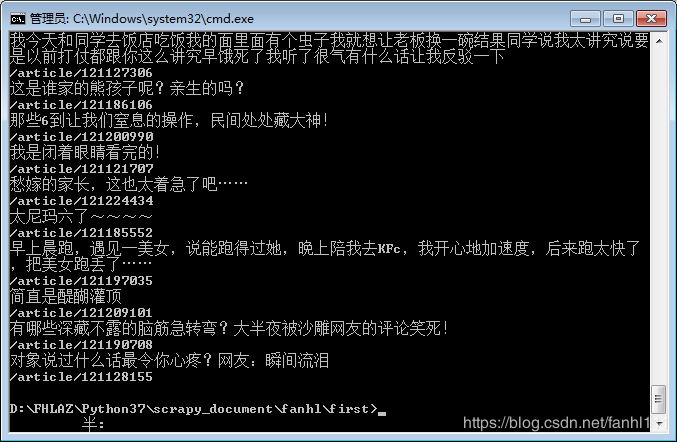
这次爬取了, 改了好几次xpath提取公式。也可能是在setting里面加了user-agent。
这个代码我主要是提取了首页的标题和链接,接下来改下代码提取糗事的搞笑文本和链接吧。
主要就是改了qsbk.py文件。
qsbk.py
# -*- coding: utf-8 -*-
import scrapy
from first.items import FirstItem
from scrapy.http import Request
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
'''
start_urls = ['http://qiushibaike.com/']
'''
def start_requests(self):
ua = {"Use-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
yield Request('https://www.qiushibaike.com/text/page/2/', headers=ua)
def parse(self, response):
it = FirstItem()
it["content"] = response.xpath('//div[@class="content"]/span/text()').extract()
it["link"] = response.xpath('//a[@class="contentHerf"]/@href').extract()
yield it # 返回 不能用return return无法执行多次 生成和返回

但是运行说范围有问题,我发现内容的个数比正常的多,因为文本里面有了
干扰了。
所以我改了一下输出文件pipelines.把链接和内容分开输出了。

成功!!!
这里再考虑一个问题吧,怎么才能把爬取的
去掉呢。然后content和link一起输出呢。之后再研究。先继续。
我回到台式机,替换了qsbk.py文件,发现可以运行 那之前就是qsbk.py文件出错了。
通用爬虫糗事百科自动爬虫实战(2019.5.25成功)
cd E:\FHLAZ\Python37\Anaconda3\scrapy_document\first
scrapy startproject qsuto#新建一个爬虫项目
cd .\qsuto\#进入这个爬虫项目
scrapy genspider -t crawl weisuen qiushibaike.com#爬取名为qsbk域名为qiushibaike.com的爬虫文件
https://www.qiushibaike.com/
scrapy crawl weisuen --nolog#运行qsbk的文件
weisuen.py
# -*- coding: utf-8 -*-
import scrapy
from qsuto.items import QsutoItem
from scrapy.http import Request
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class WeisuenSpider(CrawlSpider):
name = 'weisuen'
allowed_domains = ['qiushibaike.com']
'''
start_urls = ['http://qiushibaike.com/']
'''
def start_requests(self):
ua = {"Use-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
yield Request('https://www.qiushibaike.com/text/page/2/', headers=ua)
#LinkExtractor设置链接提取规则 allow=r'article/'或者 allow='article/'爬取链接里面有article
# follow链接是否跟进 True表示全网爬取 False表示不跟进,只爬取一次
rules = (
Rule(LinkExtractor(allow='article/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i=QsutoItem()
i["content"] = response.xpath('//div[@class="content"]/text()').extract()
i["link"] = response.xpath('//link[@rel="canonical"]/@href').extract()
print(i["content"])
print(i["link"])
print("")
return i # 返回 不能用return return无法执行多次 生成和返回
setting.py
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
items.py
import scrapy
class QsutoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
link = scrapy.Field()
运行成功了,但是我不是很能理解为啥要修改提取规则,好像是说LinkExtractor在首页提取了链接。callback回调函数采用了parse_item提取。这里说的是详情页,所以提取规则不一样了。基本就这样。

天善智能自动爬虫实战
1、天善智能课程自动爬虫实战(成功)
scrapy startproject ta
cd .\ta\
scrapy genspider -t basic lesson hellobi.com
https://edu.hellobi.com/course/
scrapy crawl lesson --nolog
先创建爬虫项目ta,在创建爬虫文件lesson, 然后设置items,要爬取的是标题title,学生数stu,链接link,lessons.py里面先实例化一个项目item,然后通过xpath设置爬取的标题 item[“title”],然后输出item[“title”],运行一下,很开心成功了。天山智能网址很友好。

#items.py
import scrapy
class TaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
stu = scrapy.Field()
#lessons.py
# -*- coding: utf-8 -*-
import scrapy
from ta.items import TaItem
class LessonSpider(scrapy.Spider):
name = 'lesson'
allowed_domains = ['hellobi.com']
start_urls = ['https://edu.hellobi.com/course/300']
def parse(self, response):
item=TaItem()
# item["title"]=response.xpath("/html/body/div[2]/ol/li[2]/text()").extract()
item["title"]=response.xpath("//ol[@class ='breadcrumb']/li[@class ='active']//text()").extract()
print(item["title"])
接下来我们试着发现天山智能网址里面1-300的网址都可以爬,我先声明一下我出现的错误吧,最开始我只能爬取一个,因为我的Request函数写成了小写,也就是说,导入和运行的Request首字母一定要大写。而且一定要导入。通过request对象来获取请求数据.
接下来要把爬取的数据存储下来,这个是在pipelines文件里面写,先在初始化文件__init__文件里面打开文件地址,记住要赋给句柄,不然不知道对谁操作,最后要记得定义close_spider函数吧文件关闭,在数据处理文件里面写存储文件。对了,setting文件里面的pipelines记得要打开。
最后也成功了
展示一下代码
#pipelines.py
class TaPipeline(object):
def __init__(self):
self.fh=open("E:/FHLAZ/Python37/Anaconda3/scrapy_document/first/第7次课/result/1.txt","a")#打开方式是追加a
def process_item(self, item, spider):
print(item["title"])
print(item["link"])
print(item["stu"])
print("——————")
self.fh.write(item["title"][0]+"\n"+item["link"][0]+"\n"+item["stu"][0]+"\n"+"——————"+"\n")
return item
def close_spider(self):
self.fh.close()
#lessons.py
# -*- coding: utf-8 -*-
import scrapy
from ta.items import TaItem
from scrapy.http import Request
class LessonSpider(scrapy.Spider):
name = 'lesson'
allowed_domains = ['hellobi.com']
start_urls = ['https://edu.hellobi.com/course/1']
def parse(self, response):
item=TaItem()
item["title"] = response.xpath("//ol[@class ='breadcrumb']/li[@class ='active']//text()").extract()
item["link"] =response.xpath("//ul[@class='nav nav-tabs']/li[@class='active']/a/@href").extract()
item["stu"] =response.xpath("//span [@class='course-view']/text()").extract()
#item["link"] = response.xpath("/html/body/div[2]/div[2]/div/div[1]/div/div/div[1]/ul/li[1]/a/@href").extract()
#item["stu"] = response.xpath("/html/body/div[2]/div[1]/div/div[2]/div/div[2]/span[2]").extract()
#item["title"]=response.xpath("/html/body/div[2]/ol/li[2]/text()").extract()
yield item
for i in range(2,101):
url="https://edu.hellobi.com/course/"+str(i)
yield Request(url,callback=self.parse)
#setting.py
ITEM_PIPELINES = {
'ta.pipelines.TaPipeline': 300,
}

2、自动模拟登陆爬虫实战(失败)
E:\FHLAZ\Python37\Anaconda3\scrapy_document\first\第7次课
scrapy startproject douban
cd .\douban\
scrapy genspider -t basic db douban.com
#https://www.douban.com/
scrapy crawl db --nolog
首先打开豆瓣的网址:https://www.douban.com/, 然后可以发现登陆的界面,这里需要抓包分析fiddler,我找到的真实登陆网址是这个:https://accounts.douban.com/passport/login,
然后再db文件里面写了初始url,然后写了ua,
这个网址主要是说有验证码的爬取过程,但是现在不是图片验证码,而是移动缺口的验证方式,暂时运行失败了,先说一下视频的理解吧,之后有时间找别的网站尝试.
后来老师答疑的时候,说了这种移动缺口的一般可以扫描二维码登陆,然后把cookie记录下来就行了。具体怎么操作还没有做,之后有时间可以试试。
验证码处理方式包括半自动处理、打码平台接口、图片识别

后续我在数据分析与数据挖掘实战视频——学习笔记之自动模拟登陆爬虫实战(微博爬虫和豆瓣爬虫,验证码和扫码登陆)中写了,因为太长了,我还需要继续更新研究。
3、当当商城爬虫实战(成功)
讲解当当商城爬虫实战,并且为大家讲解如何将爬到的内容写到数据库中。
爬取当当网的标题,链接,评论数是ok的。感觉和爬取天山智能差不多
cd ..\
scrapy startproject dangdang
cd .\dangdang\
scrapy genspider -t basic dd dangdang.com
http://www.dangdang.com/
scrapy crawl dd --nolog
dd.py
# -*- coding: utf-8 -*-
import scrapy
from dangdang.items import DangdangItem
from scrapy.http import Request
class DdSpider(scrapy.Spider):
name = 'dd'
allowed_domains = ['dangdang.com']
start_urls = ['http://category.dangdang.com/pg1-cp01.54.06.00.00.00.html']
def parse(self, response):
item=DangdangItem()
#item["title"]=response.xpath("//*[@id="p24003310"]/p[1]/a/@title").extract()
item["title"]=response.xpath("//p[@class='name']/a/@title").extract()
item["link"] = response.xpath("//p[@class='name']/a/@href").extract()
item["comment"] = response.xpath("//a[@class='search_comment_num']/text()").extract()
yield item
for i in range(2,3):
url="http://category.dangdang.com/pg"+str(i)+"-cp01.54.06.00.00.00.html"
yield Request(url,callback=self.parse)
items.py
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #标题
link = scrapy.Field() #商品链接
comment = scrapy.Field() #评论
setting.py
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}
pipelines.py
class DangdangPipeline(object):
def process_item(self, item, spider):
for i in range(0,len(item["title"])):
title=item["title"][i]
link=item["link"][i]
comment=item["comment"][i]
print(title)
print(link)
print(comment)
return item
存储数据库,这里先介绍一下
import pymysql
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="test")
sql="insert into stu(id,name,age) values('22','gk','333')"
conn.query(sql)#去执行sql操作
conn.close()
cd C:\Program Files\MySQL\MySQL Server 8.0\bin
#mysql -uroot -p
#show databases;
#use test;
#show tables;
# select * from stu;
host是本地地址,
user用户名,我的是root
passwd密码,我的是另外的,不确定自己的密码的时候可以尝试打开sql输入密码,
打开sql的方法有两种,
一种是找到mysql.exe,在mysql的安装路径下的bin目录里面,我的是C:\Program Files\MySQL\MySQL Server 8.0\bin,然后,输入mysql -uroot -p。也可以进入bin目录,按住shift键然后点击鼠标右键可以选择在该目录下打开命令窗口。

sql基础操作
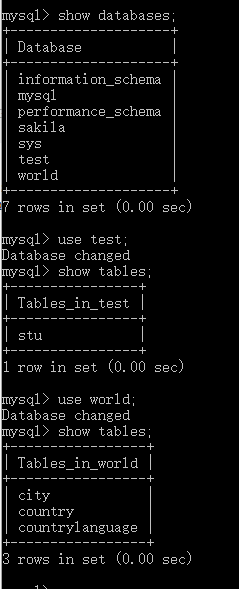
输入show databases;(注意末尾有分号)可以查看当前MySQL中的数据库列表,输入use test;可以进入test数据库(前提是要有此数据库),输入show tables可以查看test数据库中的所有表,输入quit可以退出MySQL的操作管理界面。
查看主机ip地址是打开cmd,输入ipconfig,回车(这里没有用到这些地址)
host后面的主机地址是“127.0.0.1”,没太搞懂,先默认使用这个。
之后老师使用了phpstudy,安装链接如下:
http://www.php.cn/php-weizijiaocheng-362379.html
http://phpstudy.php.cn/jishu-php-2956.html
先不安装 看看能不能成功。
错误:明明运行成功,却没有在数据库里面发现存入的数据
解决方法:conn.commit()
安装下phpstudy,但是不加这一行代码数据库里面还是没有内容。先继续。
当当网存入SQL
create database dd;
use dd
create table books(title char(100) primary key,link char(100) unique,comment int(20));
create table books(title char(100) primary key,link char(100) unique,comment varchar(20));
select * from books;
select count(*) from books;
去爬网页:
cd E:\FHLAZ\Python37\Anaconda3\scrapy_document\first\第7次课\dangdang
scrapy crawl dd --nolog
中间创建表除了问题,这是中间用到的SQL代码
drop table books
create table hooks(title char(100) primary key,link char(100) unique,coment int(20));
alter table hooks rename to books;
alter table books change coment comment varchar(20);
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class DangdangPipeline(object):
def process_item(self, item, spider):
conn = pymysql.connect(host="127.0.0.1", user="root", passwd="root", db="dd")
for i in range(0,len(item["title"])):
title=item["title"][i]
link=item["link"][i]
comment=item["comment"][i]
sql="insert into books(title,link,comment) values('"+title+"','"+link+"','"+comment+"')"
print(title)
print(link)
print(comment)
conn.query(sql)
conn.commit()
conn.close()
return item
第一次爬取成功了 不知道为啥 第二次没成功 我再试试 后来发现是我吧数据的类型设置为int了 但是实际上是varchar(20)
2019.5.29更新,因为后续数据分析与数据挖掘视频里面需要数据,所以我想重新爬取一下数据,加上price这个属性,也可以忽略这一部分。
cd C:\Program Files\MySQL\MySQL Server 8.0\bin
mysql -uroot -p
show databases;
use dd;
create table books2 (title char(100) primary key,link char(100) unique,price char(20),comment char(20));
drop table books2 ;
create table books2 (title char(200) primary key,link char(100) unique,price char(20),comment char(20));
cd E:\FHLAZ\Python37\Anaconda3\scrapy_document\first\第7次课\dangdang
scrapy crawl dd--nolog
select * from books2 ;
select count(*) from books2 ;
![]()
原因:
字段的长度不够存放数据
解决方案:
就是更改mysql中name 字段的max_length 的长度

初步处理了一下。现在这个数据我们就可以后面用了。
代码也放到这里
dd.py
# -*- coding: utf-8 -*-
import scrapy
from dangdang.items import DangdangItem
from scrapy.http import Request
class DdSpider(scrapy.Spider):
name = 'dd'
allowed_domains = ['dangdang.com']
start_urls = ['http://category.dangdang.com/pg1-cp01.54.06.00.00.00.html']
def parse(self, response):
item=DangdangItem()
#item["title"]=response.xpath("//*[@id="p24003310"]/p[1]/a/@title").extract()
item["title"]=response.xpath("//p[@class='name']/a/@title").extract()
item["link"] = response.xpath("//p[@class='name']/a/@href").extract()
item["price"] = response.xpath("//span[@class='search_now_price']/text()").extract()
item["comment"] = response.xpath("//a[@class='search_comment_num']/text()").extract()
yield item
for i in range(2,100):
url="http://category.dangdang.com/pg"+str(i)+"-cp01.54.06.00.00.00.html"
yield Request(url,callback=self.parse)
items.py
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #标题
link = scrapy.Field() #商品链接
price = scrapy.Field() #商品价格
comment = scrapy.Field() #评论
pipelines.py
import pymysql
class DangdangPipeline(object):
def process_item(self, item, spider):
conn = pymysql.connect(host="127.0.0.1", user="root", passwd="自己的密码", db="dd")
#print(len(item["title"]))
#print(len(item["link"]))
#print(len(item["price"]))
#print(len(item["comment"]))
for i in range(0,len(item["title"])):
title=item["title"][i]
link=item["link"][i]
price = item["price"][i]
comment=item["comment"][i]
print(title)
print(link)
print(price)
print(comment)
sql = "insert into books2(title,link,price,comment) values('"+title+"','"+link+"','"+price+"','"+comment+"')"
conn.query(sql)
conn.commit()
conn.close()
return item