open-falcon部署
官方文档http://book.open-falcon.org/zh/intro/index.html
适合服务器有几万台以上,并有二次开发能力的大公司。
特点
- 强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
- 水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
- 高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
- 人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
- 高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟)
- 高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
- dashboard:多维度的数据展示,用户自定义Screen
- 高可用:整个系统无核心单点,易运维,易部署,可水平扩展
- 开发语言: 整个系统的后端,全部golang编写,portal和dashboard使用python编写。
部署实践
Open-Falon的部署情况,会随着机器量(监控对象)的增加而逐渐演进,描述如下,
-
初始阶段,机器量很小(<100量级)。几乎无高可用的考虑,所有子服务可以混合部署在1台服务器上。此时,1台中高配的服务器就能满足性能要求。
-
机器量增加,到500量级。graph可能是第一个扛不住的,拿出来单独部署;接着judge也扛不住了,拿出来单独部署;transfer居然扛不住了,拿出来吧。这是系统的三个大件,把它们拆出来后devops可以安心一段时间了。
-
机器数量再增加,到1K量级。graph、judge、transfer单实例扛不住了,于是开始考虑增加到2+个实例、并考虑混合部署。开始有明确的高可用要求?除了alarm,都能搞成2+个实例的高可用结构。再往后,机器继续不停的增加,性能问题频现。好吧,见招拆招,Open-Falcon支持水平扩展、表示毫无压力。
-
机器量达到了10K量级,这正是我们现在的情况。系统已经有3000+万个采集项。transfer部署了20个实例,graph部署了20个实例,judge扩到了60个实例(三大件混合部署在20台高配服务器上,judge单机多实例)。query有5个实例、平时很闲;hbs也有5个实例、很闲的样子;dashborad、portal、uic都有2个实例;alarm、sender、links仍然是bug般的单实例部署(这几个子服务部署在10左右台低配服务器上,资源消耗很小)。graph的db已经和portal、uic的db实例分开了,因为graph的索引已经达到了5000万量级、混用会危及到其他子系统。redis仍然是共享、单实例。这是我们的使用方式,有不合理的地方、正在持续改进。
-
机器上100K量级了。不好意思、木有经历过。目测graph索引、hbs将成为系统较为头疼的地方,Open-Falcon的系统运维可能需要1个劳动力来完成。
falcon资源消耗情况
混合部署可以提高资源使用率。这里先总结下Open-Falcon各子服务的资源消耗特点,
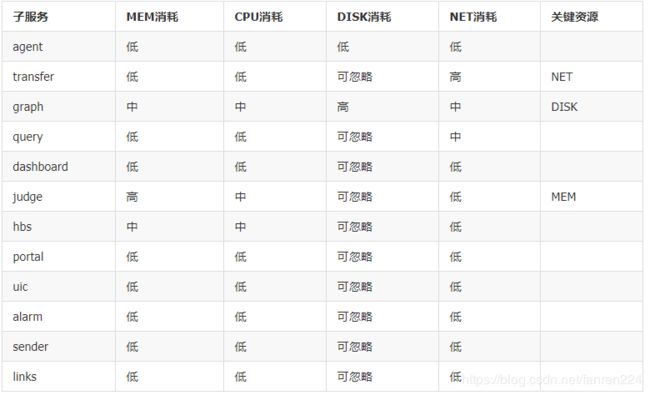
根据资源消耗特点、高可用要求等,可以尝试做一些混合部署。比如,
-
transfer&graph&judge是Open-Falcon的三大件,承受的压力最大、资源消耗最大、但彼此间又不冲突,可以考虑在高配服务器上混合部署这三个子服务
-
alarm&sender&links资源消耗较少、但稳定性要求高,可以选择低配稳定机型、单独部署
-
hbs资源消耗稳定、不易受外部影响,可以选择低配主机、单独部署
-
dashboard、portal、uic等是web应用,资源消耗都比较小、但易受用户行为影响,可以选择低配主机、混合部署、并留足余量
-
query受用户行为影响较大、资源消耗波动较大,建议选择低配主机、单独部署、留足余量
架构图
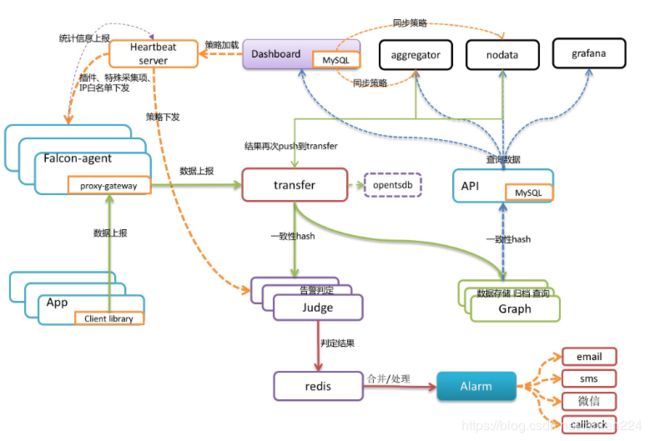
组件
-
agent:采集监控指标,每隔60秒push给Transfer。agent与Transfer建立了长连接,数据发送速度比较快,agent提供了一个http接口/v1/push用于接收用户手工push的一些数据,然后通过长连接迅速转发给Transfer。agent需要部署到所有要被监控的机器上,比如公司有10万台机器,那就要部署10万个agent。agent本身资源消耗很少,不用担心。
-
transfer:数据转发服务。它接收agent上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别push给graph&judge等组件。
-
graph:存储绘图数据的组件。graph组件 接收transfer组件推送上来的监控数据,同时处理api组件的查询请求、返回绘图数据。
-
api组件,提供统一的restAPI操作接口。比如:api组件接收查询请求,根据一致性哈希算法去相应的graph实例查询不同metric的数据,然后汇总拿到的数据,最后统一返回给用户。
-
dashboard
-
HBS(Heartbeat Server): 心跳服务器,所有agent都会连到HBS,每分钟发一次心跳请求。
-
Judge用于告警判断,agent将数据push给Transfer,Transfer不但会转发给Graph组件来绘图,还会转发给Judge用于判断是否触发告警。
-
alarm模块是处理报警event的,judge产生的报警event写入redis,alarm从redis读取处理,并进行不同渠道的发送。
-
task是监控系统一个必要的辅助模块。定时任务,实现了如下几个功能:
- index更新。包括图表索引的全量更新 和 垃圾索引清理。
- falcon服务组件的自身状态数据采集。定时任务了采集了transfer、graph、task这三个服务的内部状态数据。
- falcon自检控任务。
-
Gateway:如果您没有遇到机房分区问题,请直接忽略此组件。如果您已经遇到机房分区问题、并急需解决机房分区时监控数据回传的问题,请使用该组件。更多的资料在这里https://github.com/open-falcon/falcon-plus/blob/master/modules/gateway/README.md。
-
nodata: 用于检测监控数据的上报异常。nodata和实时报警judge模块协同工作,过程为: 配置了nodata的采集项超时未上报数据,nodata生成一条默认的模拟数据;用户配置相应的报警策略,收到mock数据就产生报警。采集项上报异常检测,作为judge模块的一个必要补充,能够使judge的实时报警功能更加可靠、完善。
-
Aggregator: 集群聚合模块。聚合某集群下的所有机器的某个指标的值,提供一种集群视角的监控体验。
-
Agent-updater:
每台机器都要部署falcon-agent,如果公司机器量比较少,用pssh、ansible、fabric之类的工具手工安装问题也不大。但是公司机器量多了之后,手工安装、升级、回滚falcon-agent将成为噩梦。
个人开发了agent-updater这个工具,用于管理falcon-agent,agent-updater也有一个agent:ops-updater,可以看做是一个超级agent,用于管理其他agent的agent,呵呵,ops-updater推荐在装机的时候一起安装上。ops-updater通常是不会升级的。具体参看:https://github.com/open-falcon/ops-updater
安装环境
- centos7.3
- redis
- mysql
- golang
- open-falcon-v0.2.1.tar.gz
-
服务端为前后端分离的架构,安装所有组件,安装在master1上
-
agent机器上只需要安装agent组件,安装slave1上
-
生产环境下后端可以拆分部署,dashboard可以用keepalived和haproxy做高可用和负载均衡
-
本文是单master实验环境,部署在一起了
服务端安装准备
初始化MySQL表结构,执行下面的脚本
#!/bin/bash
#author: hanli
set -u
set -x
set -e
set -o pipefail
cd /tmp/ && git clone https://github.com/open-falcon/falcon-plus.git
cd /tmp/falcon-plus/scripts/mysql/db_schema/
mysql -h 127.0.0.1 -u root -pHanli224! < 1_uic-db-schema.sql
mysql -h 127.0.0.1 -u root -pHanli224! < 2_portal-db-schema.sql
mysql -h 127.0.0.1 -u root -pHanli224! < 3_dashboard-db-schema.sql
mysql -h 127.0.0.1 -u root -pHanli224! < 4_graph-db-schema.sql
mysql -h 127.0.0.1 -u root -pHanli224! < 5_alarms-db-schema.sql
rm -rf /tmp/falcon-plus/
下载安装包
wget https://github.com/open-falcon/falcon-plus/releases/download/v0.2.1/open-falcon-v0.2.1.tar.gz -P /tmp/
服务端安装步骤
Open-Falcon,为前后端分离的架构,包含backend 和 frontend的dashboard两部分
先安装后端
1、创建工作目录
export FALCON_HOME=/home/work
export WORKSPACE=$FALCON_HOME/open-falcon
mkdir -p $WORKSPACE
2、解压二进制包
tar -xzvf open-falcon-v0.2.0.tar.gz -C $WORKSPACE
3、修改配置文件
cd $WORKSPACE
grep -Ilr 3306 ./ | xargs -n1 -- sed -i 's/root:/lqs:Hanli224!/g'
I:不匹配当前二进制文件
l:只匹配文件
r: 递归目录匹配
4、启动
./open-falcon start
# 检查所有模块的启动状况
./open-falcon check
# 更多用法
./open-falcon [start|stop|restart|check|monitor|reload] module
# 日志路径
$WorkDir/$moduleName/log/logs/xxx.log
安装前端dashboard
1、克隆前端组件代码
cd $WORKSPACE
git clone https://github.com/open-falcon/dashboard.git
2、安装依赖包
yum install -y python-virtualenv
yum install -y python-devel
yum install -y openldap-devel
yum install -y mysql-devel
yum groupinstall "Development tools"
cd $WORKSPACE/dashboard/
virtualenv ./env
./env/bin/pip install -r pip_requirements.txt -i https://pypi.douban.com/simple
3、修改dashboard配置文件rrd/config.py
# 修改以下行,改为自己的数据库
PORTAL_DB_USER = os.environ.get("PORTAL_DB_USER","root")
PORTAL_DB_PASS = os.environ.get("PORTAL_DB_PASS","Hanli224!")
ALARM_DB_USER = os.environ.get("ALARM_DB_USER","root")
ALARM_DB_PASS = os.environ.get("ALARM_DB_PASS","Hanli224!")
以开发者模式启动
./env/bin/python wsgi.py
4、在生产环境启动
bash control start
在浏览器上访问 http://192.168.255.131:8081 ,master1上安装服务端的时候,自动安装了agent,所以能管理自身,目前只有一台机器
客户端是否安装成功,访问 http://192.168.255.131:1988页面
停止dashboard运行
bash control stop
查看日志
bash control tail
dashbord用户管理
- dashbord没有默认创建任何账号包括管理账号,需要你通过页面进行注册账号。
- 想拥有管理全局的超级管理员账号,需要手动注册用户名为root的账号(第一个帐号名称为root的用户会被自动设置为超级管理员)。
- 超级管理员可以给普通用户分配权限管理。
- 小提示:注册账号能够被任何打开dashboard页面的人注册,所以当给相关的人注册完账号后,需要去关闭注册账号功能,修改api组件的配置文件cfg.json的signup项
生产环境可以安装两台服务端,组成高可用负载均衡
在这里插入代码片
安装agent
agent需要部署到所有要被监控的机器上,比如公司有10万台机器,那就要部署10万个agent。agent本身资源消耗很少,不用担心。
1、将agent目录复制到agent节点
scp -r /opt/work/open-falcon/agent slave1.hanli.com:/opt/falcon-agent/
2、修改/opt/falcon-agent/agent/config/cfg.json
{
"debug": true,
"hostname": "slave1.hanli.com",
"ip": "192.168.255.121",
"plugin": {
"enabled": false,
"dir": "./plugin",
"git": "https://github.com/open-falcon/plugin.git",
"logs": "./logs"
},
"heartbeat": {
"enabled": true,
"addr": "192.168.255.131:6030",
"interval": 60,
"timeout": 1000
},
"transfer": {
"enabled": true,
"addrs": [
"192.168.255.131:8433"
],
"interval": 60,
"timeout": 1000
},
"http": {
"enabled": true,
"listen": "192.168.255.121:1988",
"backdoor": false
},
"collector": {
"ifacePrefix": ["eth", "em", "ens"],
"mountPoint": ["/", "/data"]
},
"default_tags": {
},
"ignore": {
"cpu.busy": true,
"df.bytes.free": true,
"df.bytes.total": true,
"df.bytes.used": true,
"df.bytes.used.percent": true,
"df.inodes.total": true,
"df.inodes.free": true,
"df.inodes.used": true,
"df.inodes.used.percent": true,
"mem.memtotal": true,
"mem.memused": true,
"mem.memused.percent": true,
"mem.memfree": true,
"mem.swaptotal": true,
"mem.swapused": true,
"mem.swapfree": true
}
}
启动
/opt/falcon-agent/agent/bin/falcon-agent -c /opt/falcon-agent/agent/config/cfg.json
为了方便管理,使用systemd(agent和hbs,api,alarm这些的system文件基本上一样。只需要把agent换成hbs,api这些就行了)
[Unit]
Description=Falcon agent
After=network-online.target
[Service]
ExecStart=/opt/falcon-agent/agent/bin/falcon-agent -c /opt/falcon-agent/agent/config/cfg.json
LimitNPROC=1000
MemoryLimit=512M
StandardOutput=null
StandardError=null
Restart=always
RestartSec=20
[Install]
WantedBy=multi-user.target
访问http接口,检查agent是否启动,为啥是404不知道,但是出现404,而不是拒绝,就说明成功了
[root@slave1] ~$ curl 192.168.255.121:1988
404 page not found
测试agent 的 /v1/push接口
我们设计初衷是不希望用户直接连到Transfer发送数据,而是通过agent的/v1/push接口转发,接口使用范例:
[root@slave1] /opt/falcon-agent/agent$ ts=`date +%s`; curl -X POST -d "[{\"metric\": \"metric.demo\", \"endpoint\": \"qd-open-falcon-judge02.hd\", \"timestamp\": $ts,\"step\": 60,\"value\": 9,\"counterType\": \"GAUGE\",\"tags\": \"project=falcon,module=judge\"}]" http://192.168.255.121:1988/v1/push
success
检查是否安装成功
[root@master1] /opt/work/open-falcon$ agent/bin/falcon-agent --check
ss -tln ... ok
ps aux ... ok
kernel ... ok
cpustat ... ok
memory ... ok
ss -s ... ok
netstat ... ok
du -bs ... ok
df.bytes ... ok
net.if ... ok
loadavg ... ok
disk.io ... ok
钉钉通知方式
git clone https://github.com/sdvdxl/falcon-message.git
cd falcon-message/
修改告警模板:
告警等级: P2
告警类型: problem
告警指标: all(#3) mem.memused.percent 81.08559>=80
主机: sh-test-master1
告警时间: 2019-7-15 14:17:00
告警说明: 内存使用率超过80%,已持续3分钟
falcon-message的systemd文件(与dashboard的systemd文件一样)
[Unit]
Description=send dingding and weixin alarm message for falcon
After=network-online.target
[Service]
Type=forking
WorkingDirectory=/root/go/src/github.com/sdvdxl/falcon-message
ExecStart=/usr/bin/bash control start
KillMode=process
Restart=on-failure
RestartSec=1min
[Install]
WantedBy=multi-user.target
监控mysql
适用于mysql5.7.3以上
1、开启mysql的binlog功能
在[mysqld]下面添加如下两行
[mysqld]
log-bin=/var/lib/mysql/mysql-bin
server-id=1
参考:https://rayfuxk.iteye.com/blog/2340054
重启后生效。
2、
go get -u github.com/open-falcon/mymon
报错,提示未定义Version,Compile,Branch,
GitDirty
vi main.go 注释掉相关代码,如下
func main() {
// parse config file
var confFile string
flag.StringVar(&confFile, "c", "myMon.cfg", "myMon configure file")
// version := flag.Bool("v", false, "show version")
flag.Parse()
// if *version {
// fmt.Println(fmt.Sprintf("%10s: %s", "Version", Version))
// fmt.Println(fmt.Sprintf("%10s: %s", "Compile", Compile))
// fmt.Println(fmt.Sprintf("%10s: %s", "Branch", Branch))
// fmt.Println(fmt.Sprintf("%10s: %d", "GitDirty", GitDirty))
// os.Exit(0)
// }
conf, err := common.NewConfig(confFile)
if err != nil {
fmt.Printf("NewConfig Error: %s\n", err.Error())
return
再次执行go get -u github.com/open-falcon/mymon
成功后
cd $GOPATH/src/github.com/open-falcon/mymon
make
3、日志文件需要自己创建
open-falcon接入grafana
https://github.com/open-falcon/grafana-openfalcon-datasource
告警等级的问题
电话短信接入
ldap接入
常见问题
1、手动删除了数据库中 endpoint表、endpoint_counter中的一些记录后,相同的指标不会再次插入到MySQL中了。
可以手工运行一次 graph 的索引刷新命令,即针对每个graph实例执行:
curl -s http://127.0.0.1:6071/index/updateAll (这里假定graph模块http监听端口为6071)。