TCP拥塞控制之理论基础
TCP的拥塞控制算法在不停的演进,这篇笔记按照演进顺序只介绍最基本的三个版本:Tahoe、Reno、New Reno。
1. Tahoe
这是TCP拥塞控制算法的第一个正式版本,其只有慢启动、拥塞避免、快速重传三个算法,没有快速恢复算法。对于慢启动和拥塞避免算法,大家耳熟能详,这里不再赘述,下面只说明快速重传算法和遇到拥塞后的具体表现。
这个版本中将两种情况视为发生了拥塞:
- 重传定时器超时;
- 连续收到三个重复ACK;
发生拥塞后:
- 如果是RTO超时,TCP反应最强烈,直接将ssthresh设置为当前cwnd的一半,cwnd减为1,然后执行慢启动算法;
- 如果是连续收到三个重复ACK,则执行快速重传算法;
1.1 快速重传
所谓的快速重传,是相对于RTO超时后的重传而言的,当连续收到三个重复ACK,判定为网络拥塞,而且重复ACK中确认的报文已经丢失,这时无需等到RTO超时,立即重传该报文。
重传了重复确认的报文后,Tahoe算法规定,按照和RTO超时后相同的办法调整ssthresh和cwnd,然后执行慢启动算法。
1.2 算法效果
考虑下Tahoe的性能,一旦丢包,立即进入慢启动,所以从执行效果来看,cwnd的震荡会很大,如下图所示(图片来源于这里):
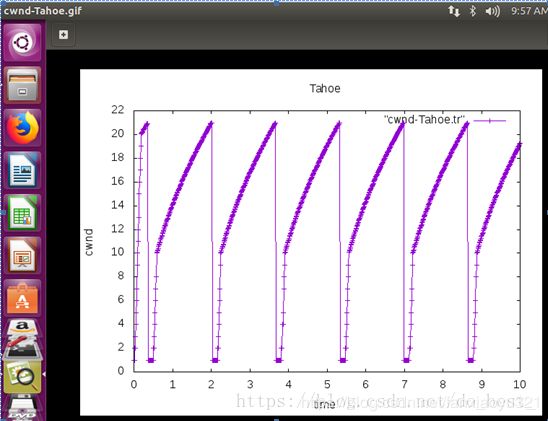
如上,Tahoe在收到三个重复ACK的时候反应也很强烈,直接将cwnd减为1,所以性能并不好。为了提高性能,RFC5681提出了Reno算法。
1.3 何为重复ACK
如何判定一个ACK是重复ACK,RFC 5681中有明确规定,必须满足如下四个条件:
- 发送方还有未被确认的数据;
- ACK报文没有携带数据;
- ACK报文没有携带SYN和FIN标记;
- ACK报文中的确认号等于SND.UNA;
- ACK报文中的窗口字段等于目前收到的广播窗口值,即这不是一个窗口更新报文。
这里的重复ACK报文确定规则适用于下面所有的算法。
2. Reno(RFC 5681)
Reno在Tahoe的基础上引入了快速恢复算法,需要注意的是,Tahoe的其它三个算法同样适用于Reno。
2.1 快速重传
如果连续收到三个重复ACK,同样不等RTO超时,立即重传数据。但是之后Reno不是设置ssthresh=cwnd/2,cwnd=1,然后进入慢启动,而是:
- ssthresh = cwnd / 2;
- cwnd = ssthresh + 3;
- 执行快速恢复算法。
对慢启动门限的调整,RFC 5681中介绍应该是min(FlightSize/2, 2*MSS),而不是cwnd/2,这里我们不用去深究背后的原因(这是算法设计人员应该关注的),只要理解慢启动门限也是减半的这一设计思想即可。
cwnd设置为调整后的慢启动门限加3,这是因为收到了3个重复的ACK,认为至少应该是已经有三个数据包离开了网络,所以+3并不会对网络造成更大的负担。
2.2 快速恢复
快速恢复算法是认为,收到3个Duplicated Acks说明网络也不那么糟糕,所以没有必要像RTO超时那么强烈,所以,快速恢复期间,算法如下:
- 如果再收到 duplicated Acks,那么cwnd = cwnd +1(基于包守恒原则);
- 如果收到了新的Ack,那么,cwnd = sshthresh ,然后退出快速恢复算法,执行拥塞避免的算法。
2.3 状态机
这篇博客有一个Reno的状态机,很好的说明了这个算法的过程,如下:

2.4 算法效果
下面这张图可以很好的展示Reno算法的效果(图片来源于这里):

如果仔细思考一下上面的这个算法,就会发现这个算法也有问题,那就是——它依赖于3个重复的Acks。注意,3个重复的Acks并不代表只丢了一个数据包,很有可能是丢了好多包。但这个算法只会重传一个,而剩下的那些包只能等到RTO超时或者再次连续收到三个重复ACK,于是,进入了恶梦模式——每次超时或者三个重复ACK发生,窗口就减半一次,多个循环下来会超成TCP的传输速度呈级数下降。
为了应对这种同时丢多个包的情形,有两个改进方向:一是基于SACK改进算法;二是New Reno;前者需要TCP协议支持,并且做较大的代码调整,而后者只需要改变发送方的快速恢复算法即可。
3. New Reno(RFC 6582)
下面内容来自于这篇博客,其对New Reno的解释非常到位。
NewReno TCP在Reno TCP的基础上对快速恢复算法进行修改,只有一个数据包丢失的情况下,其机制和Reno是一样的;当同时有多个包丢失时就显示出了它的优势。
Reno快速恢复算法中发送方收到一个新的ACK就退出快速恢复状态,New Reno算法中只有当所有报文都被应答后才退出快速恢复状态。
New Reno充分利用了ACK报文提供的信息,使发送端可以把一次拥塞丢失多个报文的情形与多次拥塞的情形区分开来,进而在每一次拥塞发生后拥塞窗口仅减半一次,从而提高了TCP的顽健性和吞吐量。
3.1 部分应答(PACK)与恢复应答(RACK)
记发送端恢复阶段过程中接收到的ACK报文(非冗余ACK)为ACKx,记在进入快速恢复阶段时发送端已发出的序列号(SN)最大的报文是PKTy,如果ACKx不是PKTy的应答报文,则称报文ACKx为部分应答(Partial ACK,简称PACK);若ACKx恰好是PKTy的应答报文则称报文ACKx为恢复应答(Recovery ACK,简称RACK)。
举例来理解:如果4、5、6号包丢了,现在只重传4,只收到了4的ACK,后面的5、6没有确认,这就是部分应答Partial ACK。如果收到了6的ACK,则是恢复应答Recovery ACK。
发送端接收到RACK表明:经过重传,发送端发送的所有报文都已经被接收端正确接收,网络已经从拥塞中恢复。
3.2 快速恢复
New Reno规定发送端在收到第一个Partial ACK时,并不会立即结束Fast-recovery,而会持续地重发Partial ACK之后的数据包,直到将所有遗失的数据包被确认后才结束Fast-recovery。收到一个Partial ACK时,重传定时器就复位。这使得发送端在网络有大量数据包遗失时不需等待RTO超时就能更正此错误,这可以避免进入慢启动过程,减少大量数据包遗失对传输效果造成的影响。
New Reno算法下面,大约每一个RTT时间可重传一个丢失的数据包,如果一个发送窗口有M个数据包丢失,New Reno的快速恢复阶段将持续M个RTT。
New Reno规定的具体的快速恢复算法步骤如下:
- 进入恢复阶段后,发送端重传丢失的报文,设置慢启动阈值(ssthresh)和拥塞窗口大小(cwnd)。ssthresh = cwnd/2,cwnd = ssthresh + 3MSS;
- 每收到一个重复ACK,cwnd = cwnd + MSS;
- 当收到PACK(部分应答)时,重传PACK所确认报文的下一个报文,如果拥塞窗口允许,继续发送新的数据包;
- 当收到RACK(确认应答)时,说明发生拥塞时的所有未确认数据包都已经成功被接收,拥塞结束。设置cwnd=ssthresh并退出快速恢复过程,进入拥塞避免过程。
Reno和New Reno的快速恢复过程对比如下图所示:

快速恢复是基于数据包守恒的原则,即同一时刻能在网络中传输的数据包是恒定的,只有当旧数据包离开网络后,才能发送新数据包进入网络。一个重复ACK不仅意味着有一个包丢失了,还表示有发送的数据包离开了网络,已经在接收区的缓冲区中,不再占用网络资源,于是将拥塞窗口加一个数据包大小。