KDD 2019放榜!录取率仅14%,强调可重现性

【导读】KDD 2019录取结果终于放榜了,今年Research和ADS两个 track共评审论文1900篇,其中Research track的录取率只有14%。今年也是KDD第一次采用双盲评审政策,并强调提交论文可重现内容。因此,论文质量特别值得期待。
KDD 2019录取论文终于放榜了!你的论文“中奖”了吗?
ACM SIGKDD(国际数据挖掘与知识发现大会,简称 KDD)是世界数据挖掘领域的最高级别的学术会议,由 ACM 的数据挖掘及知识发现专委会(SIGKDD)主办,被中国计算机协会推荐为 A 类会议。
自 1995 年以来,KDD 已经连续举办了二十余届大会,今年是第25届。今年的 KDD 大会将于 2019 年 8 月 4 日 ~8 日在美国阿拉斯加州安克雷奇市举行。
原定于4 月 28 日 (UTC-11),也就是北京时间 4 月 29 日晚上 7 点发出的录取结果通知,延迟了大半天之后终于陆续放榜。新智元也在twitter、朋友圈等看到论文作者们晒出录取结果。


录取率仅14%,强调论文结果可重现
作为数据挖掘领域最顶级的学术会议,KDD 大会以论文接收严格闻名,每年的接收率不超过 20%,因此颇受行业关注。今年也是KDD大会采用双盲评审的第一年。
与往年一样,KDD大会分为 Research 和 Applied Data Science 两个 track。
据了解,今年KDD Research track 共评审了约 1200 篇投稿,其中约 110 篇被接收为 oral 论文,60 篇被接收为 poster 论文,接收率约 14%。
ADS track收到大约 700 篇论文,其中大约 45 篇被接收为 oral 论文,约 100 篇被接收为 poster 论文,接收率约 20.7%。
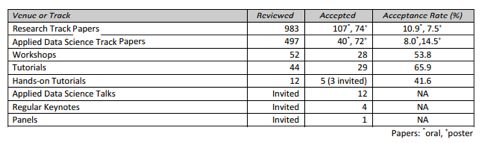
相比之下,2018年KDD大会共评审了 1440 篇论文,其中,Research Track 评审了 983 篇论文,接收 181 篇,接收率为 18.4%;Applied Data Science Track 评审了 497 篇论文,接收 112 篇,接收率为 22.5%。
下表总结了 KDD 2018 的论文接收数量和接受率。
KDD 大会涉及的议题大多跨学科且应用广泛,预计将会吸引来自统计、机器学习、数据库、万维网、生物信息学、多媒体、自然语言处理、人机交互、社会网络计算、高性能计算以及大数据挖掘等众多领域的专家和学者。

KDD官网的投稿要求
值得关注的是,今年KDD投稿通知中将“可重现性”作为重点,鼓励作者们在论文中公开研究代码和数据,汇报他们的方法在公开数据集上的实验结果,并尽可能完整描述论文中使用的算法和资源,以保证可重现性。
为了鼓励呈现结果的可重现性,KDD 2019 规定只有在文章最后额外提交两页附录体现“可重现性”内容(包括实验方法、经验评估和结果)的论文,才有资格参评“最佳论文”奖项。
在等待今年最佳论文出炉之前,让我们先回顾一下去年KDD Research Track的两篇最佳论文。
KDD 2018 Research Track 最佳论文回顾
Research Track 最佳论文

Adversarial attacks on classification models for Graphs
对图分类模型的对抗性攻击
论文地址:https://arxiv.org/abs/1805.07984
作者:Daniel Zügner (Technical University of Munich); Amir Akbarnejad (Technical University of Munich); Stephan Günnemann (Technical University of Munich)
摘要:图深度学习模型在节点分类任务中取得了很好的性能。尽管图深度学习模型越来越多,但目前还没有研究探索它们对对抗性攻击的鲁棒性。然而,在可能使用它们的领域中,例如网络,对抗是很常见的。
图深度学习模型是否很容易被愚弄呢?在这项工作中,我们介绍了第一个针对属性图( attributed graphs)的对抗性攻击的研究,特别关注利用图卷积思想的模型。除了测试时的攻击外,我们还研究了更具有挑战性的中毒/诱发攻击,这些攻击集中在机器学习模型的训练阶段。我们针对节点的特征和图结构生成对抗性扰动,从而获取实例之间的依赖关系。此外,我们通过保留重要的数据特征来确保这些扰动不会被察觉。
为了解决底层离散域问题,我们提出一种利用增量计算的有效算法 Nettack。我们的实验研究表明,即使只进行少量的扰动,节点分类的准确率也会显著下降。更重要的是,我们的攻击是可迁移的:学习的攻击可以推广到其他最先进的节点分类模型和无监督方法,即使只给出很少的关于图的知识,也同样能成功。
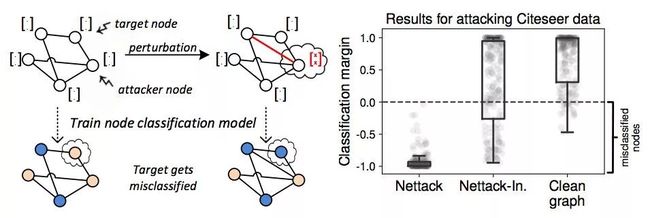
图:对图结构和节点特征的小小扰动导致目标的分类错误。
Research Track 最佳学生论文

XiaoIce Band: A Melody and Arrangement Generation Framework for Pop Music
小冰乐队:流行音乐的旋律与编曲框架
论文地址:http://www.kdd.org/kdd2018/accepted-papers/view/xiaoice-banda-melody-and-arrangement-generation-framework-for-pop-music
作者:Hongyuan Zhu (USTC); Qi Liu (USTC); Nicholas Jing Yuan (Microsoft); Chuan Qin (USTC); Jiawei Li (Soochow University); Kun Zhang (USTC); Guang Zhou (Microsoft); Furu Wei (Microsoft); Yuanchun Xu (Microsoft); Enhong Chen (USTC)
摘要:随着音乐创作知识的发展和近年来需求的增加,越来越多的公司和研究机构开始研究音乐的自动生成。但以往的模型在应用于歌曲生成时存在局限性,这既需要旋律,又需要编曲。此外,许多与歌曲质量有关的关键因素没有得到很好的解决,例如和弦进行和节奏模式。特别是。如何确保多音轨音乐的和谐,这仍然是一个有待探索的问题。
为此,我们对流行音乐的自动生成进行了重点研究,其中,我们考虑了旋律生成的和弦和节奏的影响,以及音乐编排的和声。我们提出了一种端到端的旋律和编曲生成框架,称为“小冰乐队”(XiaoIce Band),该框架产生了由几种乐器演奏的几个伴奏曲目组成的旋律音轨。
具体来说,我们设计了一种基于和弦的节奏和旋律交叉生成模型(CRMCG),以生成带有和弦进行的旋律。然后,我们提出一种基于多任务学习的多乐器协同编曲模型( Multi-Instrument Co-Arrangement Model ,MICA)。最后,我们在一个真实数据集上进行了广泛的实验,结果证明了XiaoIce Band的有效性。
欢迎关注磐创博客资源汇总站:http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:http://pytorch.panchuang.net/