搜索技术:Elasticsearch的安装步骤和使用
普通的数据库搜索的缺陷
类似:select * from 表名 where 字段名 like ‘%关键字%’
例如:select * from article where content like ’%here%’
结果: where here
1、因为没有通过高效的索引方式,所以查询的速度在大量数据的情况下是很慢。
2、搜索效果比较差,只能对用户输入的完整关键字首尾位进行模糊匹配。用户搜索的结果误多输入一个字符,可能就导致查询出的结果远离用户的预期。
1. 搜索技术
1.1 搜索引擎的种类
搜索引擎按照功能通常分为垂直搜索和综合搜索。
1、垂直搜索是指专门针对某一类信息进行搜索。例如:会搜网 主要做商务搜索的,并且提供商务信息。除此之外还有爱看图标网、职友集等。
2、综合搜索是指对众多信息进行综合性的搜索。例如:百度、谷歌、必应、搜狗、360搜索等。
1.2 倒排索引
倒排索引又叫反向索引(右下图)以字或词为文档中出现的位置情况。
它是搜索引擎的基础,如果没有它,就不会有搜索引擎

在实际的运用中,我们可以对数据库中原始的数据结构(左图),在业务空闲时事先根据左图内容,创建新的倒排索引结构的数据区域(右图)。
用户有查询需求时,先访问倒排索引数据区域(右图),得出文档id后,通过文档id即可快速,准确的通过左图找到具体的文档内容。
总结:什么是倒排索引?搜索引擎的原理?elasticsearch的原理?lucene的原理?
答:在存文档的时候,将数据进行分词,并记录每个分词下的文档编号,查找的通过分词找到对应的倒排列表的数据
实现了倒排索引的技术有哪些?
- lucene *
- solr
- elasticsearch
2.Elasticsearch介绍和安装
2.2.安装和配置
2.2.1 下载
下载地址:https://www.elastic.co/downloads/past-releases
![]()
2.2.2 安装
elasticsearch无需安装,解压即用。

es:浏览器访问:9200
代码访问:9300
2.3.运行
进入elasticsearch/bin目录,可以看到下面的执行文件:
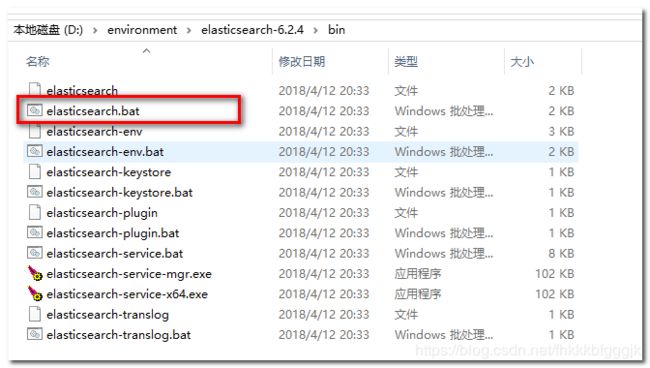
双击运行

可以看到绑定了两个端口:
- 9300:java程序访问的端口
- 9200:浏览器、postman访问接口
我们在浏览器中访问:http://127.0.0.1:9200

2.4.安装Head插件
2.4.1.什么是Head
ealsticsearch只是后端提供各种api,那么怎么直观的使用它呢?elasticsearch-head将是一款专门针对于elasticsearch的客户端工具,类似mysql的sqlyog或者navicat
elasticsearch-head配置包,下载地址:https://github.com/mobz/elasticsearch-head
2.4.2.安装
- es5以上版本安装head需要安装node和grunt
第一步:从地址:https://nodejs.org/en/download/ 下载相应系统的msi,双击安装。
第二步:安装完成用cmd进入安装目录执行 node -v可查看版本号
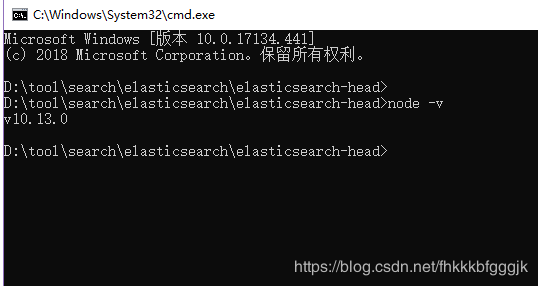
第三步:执行 npm install -g grunt-cli 安装grunt ,安装完成后执行grunt -version查看是否安装成功,会显示安装的版本号

第四步:进入elasticsearch-head文件夹,执行npm install命令

第五步:运行head插件,下面命令二选一
- 命令一:npm run start
- 命令二:grunt server
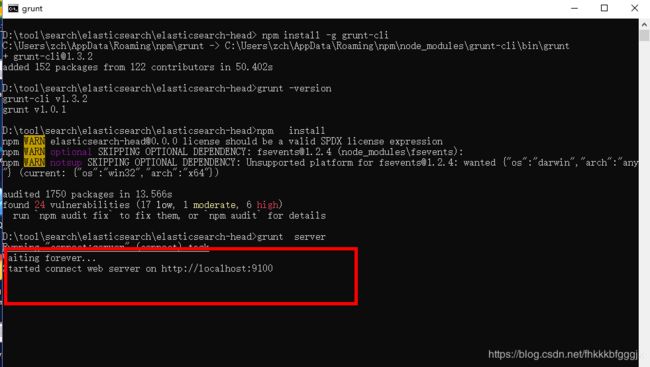
第六步:

2.4.3.配置运行
第一步:进入es安装目录下的config目录,修改elasticsearch.yml文件.在文件的末尾加入以下代码
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
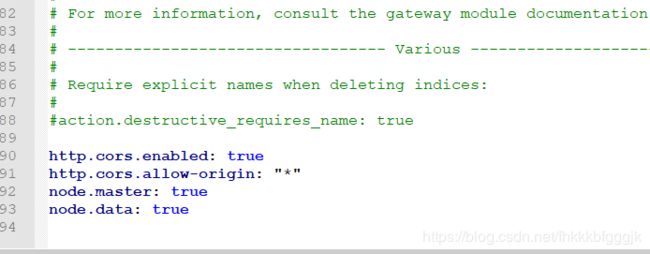
然后去掉network.host: 192.168.0.1的注释并改为network.host: 0.0.0.0,去掉cluster.name;node.name;http.port的注释(也就是去掉#)

第二步:双击elasticsearch.bat重启es
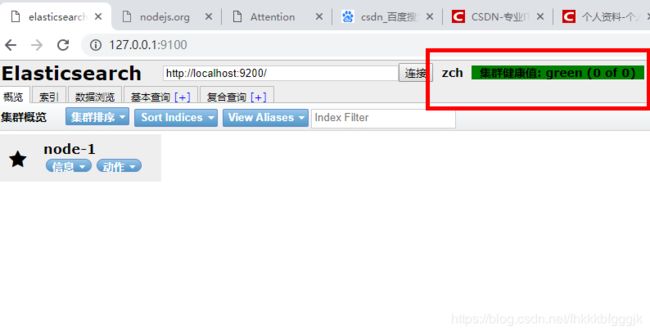
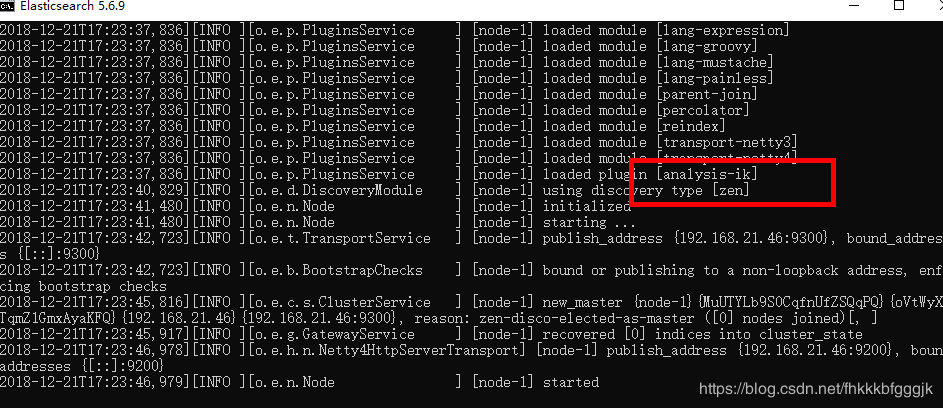
2.5.安装ik分词器
ElasticSearch 默认采用分词器, 单个字分词 ,效果很差
搜索【IK Analyzer 3.0】
http://www.oschina.net/news/2660


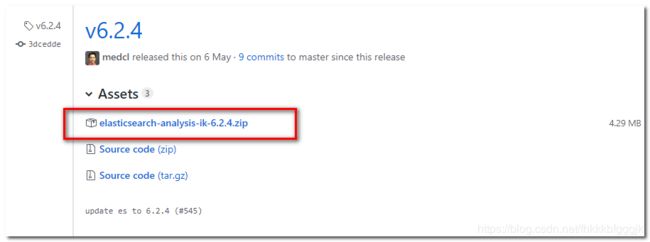
Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为Elasticsearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致,最新版本:6.2.4
2.5.1.下载
源码下载地址:https://github.com/medcl/elasticsearch-analysis-ik/tree/6.2.x
jar包下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
每个es版本对应的ik分词器jar包下载位置:https://github.com/medcl/elasticsearch-analysis-ik/releases
使用ik分词器的时候,一定要下载对应es版本的jar包
2.5.2.安装
无需安装,解压即可使用
我们将其改名为ik,并复制到elasticsearch的解压目录,如下图所示
然后重启elasticsearch:

2.5.3.扩展词和停用词
扩展词和停用词文件:


###2.5.4 测试