CNN理论基础
参考:
http://x-algo.cn/index.php/2016/12/22/1318/
Inception v1
目标
人类的大脑可以看做是神经元的重复堆积,Inception网络存在的原因就是想找构造一种「基础神经元」结构。人类的神经元之间链接往往是稀疏链接,所以就是寻找「稀疏网络」的稠密表示,并希望这个稠密网络在效果上可以「接近」甚至「超越」稀疏链接的网络。
1x1卷积层
对特征降维,一方面可以解决计算瓶颈,同时限制网络的参数大小,可以将网络做的更「宽」和更「深」,效果也不差。
线性激活
整个GoogLeNet的卷积层和Inception单元内部,都是采用线性激活函数。
单元结构

整体结构
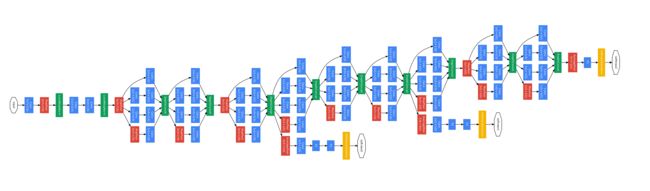
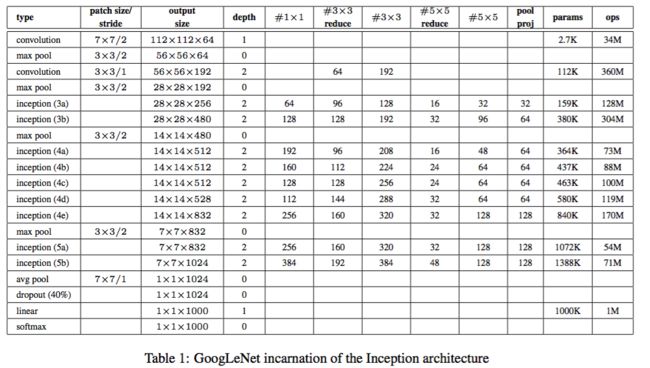
论文:Going deeper with convolutions
Batch Normalization
就是添加了一个归一化层。简称BN(Batch Normalization)。
在一个多层的神经网络中,如果前一层的参数发生了变化,就会导致前一层的输出「分布」发生改变,这种改变又会导致当前层的学习受到很大的影响,例如学习速度变慢、初始化参数对最终训练结果影响很大。所以,一种直观的想法就是在两层之间添加一层「归一化」层,从而消除这种分布的改变,提升训练的速度且不过渡依赖初始化参数。
这种分布变化的现象称为「Internal Covariate Shift」,早年是有解决方案「domain adaptation」。
梯度弥散(梯度消失)
如果激活函数式sigmoid函数,反向传播的之后只会在 |x||x| 较小的地方梯度值比较大,别的部分梯度很快接近为0,改变这种状况通常可以通过ReLU(Rectified Linear Units)激活函数/合理的初始化参数/合理的学习率来解决。导致反馈对权重的改变没作用了。
归一化之后,可以将非线性激活函数的效用得到提高,有效避免了数据集中落在一个取值区域。
白化(whitening)
http://ufldl.stanford.edu/wiki/index.php/Whitening
我们已经了解PCA降低数据维度。在一些算法中还需要一个与之相关的预处理步骤,这个预处理过程称为白化(一些文献中也叫sphering)。举例来说,假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的。白化的目的就是降低输入的冗余性;更正式的说,我们希望通过白化过程使得学习算法的输入具有如下性质:(i)特征之间相关性较低;(ii)所有特征具有相同的方差。
2D 的例子
下面我们先用前文的2D例子描述白化的主要思想,然后分别介绍如何将白化与平滑和PCA相结合。
如何消除输入特征之间的相关性? 在前文计算 ![]() 时实际上已经消除了输入特征
时实际上已经消除了输入特征![]() 之间的相关性。得到的新特征
之间的相关性。得到的新特征 ![]() 的分布如下图所示:
的分布如下图所示:
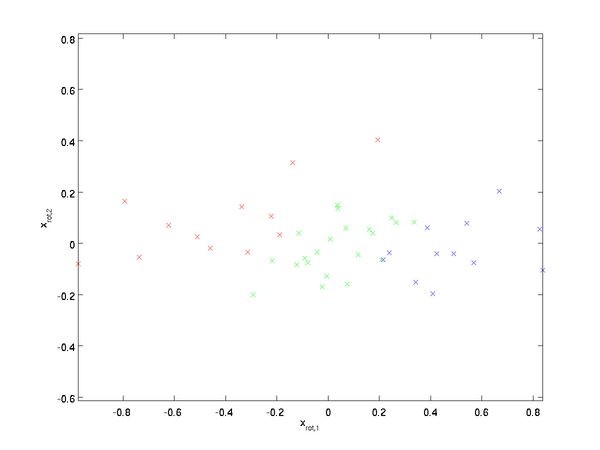
这个数据的协方差矩阵如下:
(注: 严格地讲, 这部分许多关于“协方差”的陈述仅当数据均值为0时成立。下文的论述都隐式地假定这一条件成立。不过即使数据均值不为0,下文的说法仍然成立,所以你无需担心这个。)
![]() 协方差矩阵对角元素的值为
协方差矩阵对角元素的值为 ![]() 和
和 ![]() 绝非偶然。并且非对角元素值为0; 因此,
绝非偶然。并且非对角元素值为0; 因此, ![]() 和
和 ![]() 是不相关的, 满足我们对白化结果的第一个要求 (特征间相关性降低)。
是不相关的, 满足我们对白化结果的第一个要求 (特征间相关性降低)。
为了使每个输入特征具有单位方差,我们可以直接使用 ![]() 作为缩放因子来缩放每个特征
作为缩放因子来缩放每个特征 ![]() 。具体地,我们定义白化后的数据
。具体地,我们定义白化后的数据 ![]() 如下:
如下:
绘制出 ![]() ,我们得到:
,我们得到:
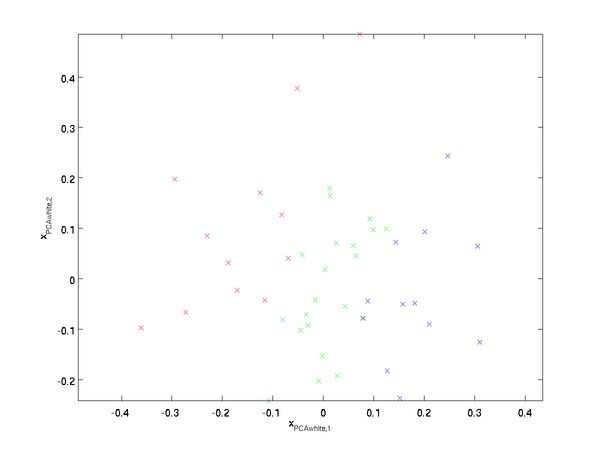
这些数据现在的协方差矩阵为单位矩阵 ![]() 。我们说,
。我们说,![]() 是数据经过PCA白化后的版本:
是数据经过PCA白化后的版本: ![]() 中不同的特征之间不相关并且具有单位方差。
中不同的特征之间不相关并且具有单位方差。
白化与降维相结合。 如果你想要得到经过白化后的数据,并且比初始输入维数更低,可以仅保留 ![]() 中前
中前 ![]() 个成分。当我们把PCA白化和正则化结合起来时(在稍后讨论),
个成分。当我们把PCA白化和正则化结合起来时(在稍后讨论),![]() 中最后的少量成分将总是接近于0,因而舍弃这些成分不会带来很大的问题。
中最后的少量成分将总是接近于0,因而舍弃这些成分不会带来很大的问题。
归一化变换
变换的想法很简单,就是减去均值除以方差,但是对于sigmoid这样的激活函数,会导致变换后的样本落在线性区域,这样就导致非线性激活函数的作用就没有体现出来,所以又引入了「逆变换」通过下面公式:
yk=γkx^k+βkyk=γkx^k+βk
基本的BN算法框架就得到了

全局期望和方差
学习的过程中可以通过batch的方式,最终使用的时候明显是不合理的,所以需要将batch中的期望和方差换为「全局」的。
在实际的使用中,最终如何得到全局的均值和方差呢? darknet中的实现方式是在训练的过程中,每一次都记录下来最终的期望和方差,用均值为例具体计算公式为:
mean(final)=mean(t)∗0.1+mean(final)∗0.9mean(final)=mean(t)∗0.1+mean(final)∗0.9
作用的位置
如下公式:
z=g(BN(Wu+b))z=g(BN(Wu+b))
所以位置是在卷积之后,激活函数之前;在卷积网络中,实际可能并不是和上面公式一模一样,可能是:
z=g(BN(Wu)+b)z=g(BN(Wu)+b)
b在里面还是外面,对结果的影响不大;scale和shift的操作目的是可以「无损」原来的分布,其实在实际中,shift操作可以省略,因为本身卷积就自带了一个bias。
另外darknet中,均值和方差的个数为卷积核的个数。
正则化
使用BN层可以有效的防止过拟合,因为每一条样本不再是相互「独立」的了(BN参数是在batch的粒度统计的),所以可以提高模型的泛化能力,减少过拟合层,例如dropout。
论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception v2
GoogLeNet设计的初衷之一就是速度要快,如果只是单纯的堆积网络虽然可以提高准群率,但是会导致效率有明显的下降,所以如何在不增加过多的计算量的同时提高网络的表达能力成为一个问题,v2的解决方案就是修改Inception内部计算逻辑,提出了比较特殊的「卷积」计算结构。
Factorizing Convolutions
Factorizing Convolutions(后面称为「卷积分解」)是一种降维方式,通过减少计算量实现,同样参数情况下加深网络。作用位置是Inception内部。
卷积分解在前几层的效果不是很好,一般在中间层,并且大小在12到20之间。


中间层分类器
在v1中的结构,除了最终输出分类结果之外,层中间的地方还有两个地方输出了分类结果,反向传播的时候这两个地方也会进行传播,这个设计的目的就是为了很好的防止梯度消失,加快收敛。有趣的是,v3中发现这个结构对学习效果意义不大,只是有很微弱的提升。所以这个结构的存在的意义就变得比较模糊,论文中猜测是起到「正则化」的作用。
减少网格大小
池化层是一种很好的方式,但是可能会限制representation能力,所以论文中通过堆叠1x1卷积和修改步长实现节约计算成本。作用位置是两个堆叠的Inception之间,两种方式如下图:

接下来就是v2的具体的结构了:
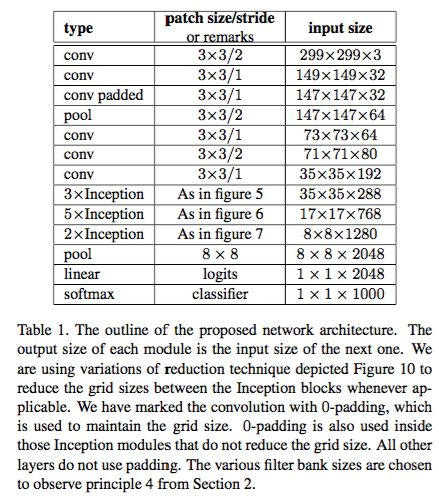
和v1相比,层数变为42层,计算量只增加了 2.5倍。
Label Smoothing
大白话就是对已有的label以一定的概率添加了一个常数项,防止过拟合。具体公式为:
q′(k|x)=(1−ξ)σk,y+ξKq′(k|x)=(1−ξ)σk,y+ξK
Inception v3
将v2各种技能综合到一起,就得到了v3,下图中最后一行就是v3,需要注意的是,其中技能是累加的。
效果和结构
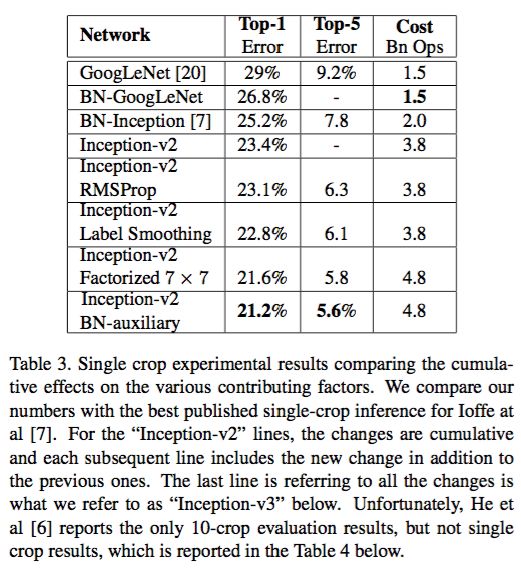
上图中几个名词具体解释一下,RMSProp是一种优化算法,Label Smoothing是对标注做了平滑防止过拟合,Factorized节约计算,BN-auxiliary是给中间层的输出添加归一化。
v2和v3的论文:Rethinking the Inception Architecture for Computer Vision
Inception v4
首先需要了解一下深度残差网络(戳我)
v4论文打出来之后比较厚,吓了我一跳,翻开之后发现满纸都是图。介绍了三个网络结构,分别是Inception-v4、Inception-ResNet-v1和Inception-ResNet-v2。下面贴出来两个结构。
Inception-v4内部结构图

图片来源这里,点击我查看大图戳我。
Inception-ResNet-v2内部结构
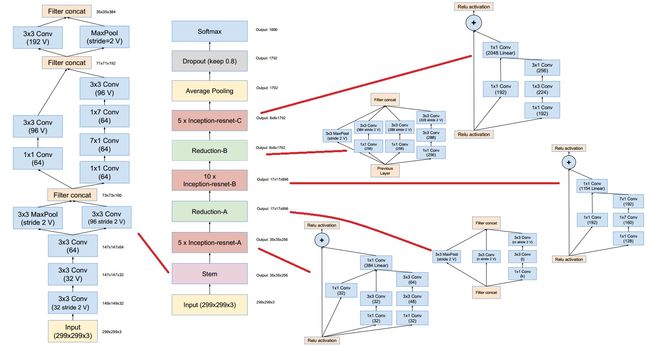
图片来源这里,查看大图请戳我。
缩放残差
残差网络过深的时候会出现不稳定的现象,原始残差网络论文中提出一种处理方式是,将网络的训练分为两个阶段,第一个阶段用先用比较低的学习率进行,这样可以缓解不稳定的问题。
本文中提出来了一种更加方便并且不影响准确率的方式,就是对残差打折,具体就是乘以一个打折系数。具体作用位置为:
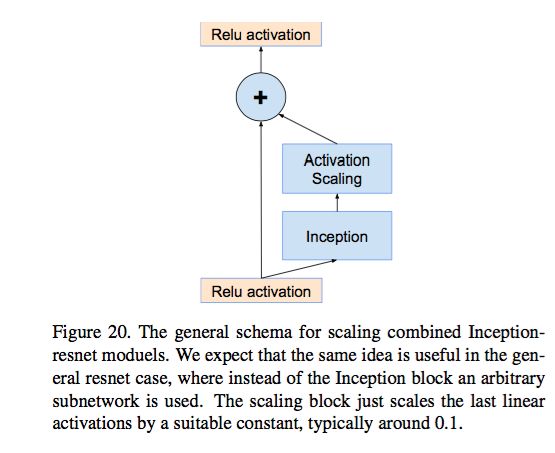
实验结果
结果当然是要比原始的残差网络要好

原始论文:
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning