Spring 学习笔记
Spring学习笔记
文章目录
- Spring学习笔记
- 1.0.概述
- 1.1使用Spring框架的好处
- 1.2特点
- 2.0体系结构
- 3.0创建Spring-java工程(eclipse)
- 4.0通过Spring创建对象的方式
- 5.0由Spring管理的对象的作用域与生命周期
- 6.0 Spring IoC
- 6.1. 通过SET方式注入属性的值
- 6.2. 通过构造方法注入属性的值
- 7.0. 注入集合类型的属性值
- 7.1. List
- 7.2. Set
- 7.3. 数组
- 7.4. Map
- 7.5. Properties
- 8. Spring表达式
- 9. 自动装配(autowire)
- ----------------------------
- 附1:List与Set
- 10. Spring注解
- 10.1. 通用注解
- 10.2. 关于作用域与生命周期的注解
- 10.3. 自动装配
- 2. Spring小结
- ------------------------------------------
- 附1:内存溢出/内存泄漏/Leak
1.0.概述
Spring框架是一个开源的JAV平台,它最初是由Rod Johnson编写,2003年6月在Apache 2.0 许可下发布。
1.1使用Spring框架的好处
- 方便解耦,简化开发
通过Spring提供的IoC容器,可以将对象之间的依赖关系交由Spring进行控制,避免硬编码所造成的过度程序耦合。
- AOP编程的支持
通过Spring提供的AOP功能,方便进行面向切面的编程,如性能监测、事务管理、日志记录等。
- 声明式事务的支持
- 方便集成各种优秀框架
1.2特点
- 控制反转 IOC(Inversion of Control)
所谓的控制反转,就是指将对象的创建,对象的存储(map),对象的管理(依赖查找,依赖注入)交给了spring容器。
- 依赖注入 DI (Dependency Injection)
Spring 最认同的技术是控制反转的依赖注入(DI)Dependency Injection模式。控制反转(IoC)Inversion of Control 是一个通用的概念,它可以用许多不同的方式去表达,依赖注入仅仅是控制反转的一个具体的例子。Spring框架通过DI实现了IoC,DI是实现手段,而IoC是实现的目标。
依赖注入,即组件之间的依赖关系由容器在应用系统运行期来决定,也就是由容器动态地将某种依赖关系的目标对象实例注入到应用系统中的各个关联的组件之中。简单来说,所谓的依赖注入其实就是,在创建对象的同时或之后,如何给对象的属性赋值。
- 面向方面的程序设计(AOP)
待完善
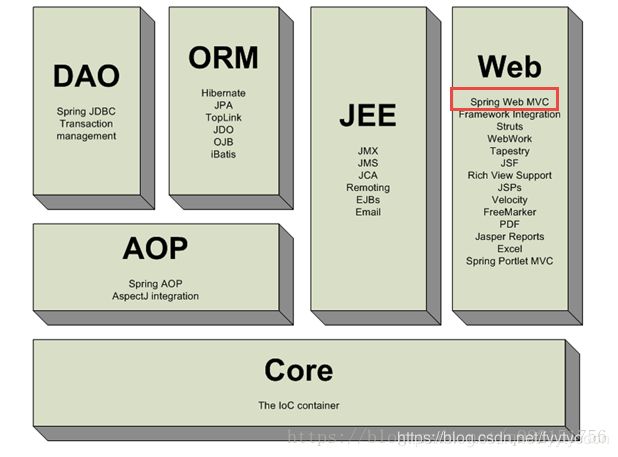
2.0体系结构
3.0创建Spring-java工程(eclipse)
创建Maven Project,创建时勾选Create a simple project,Group Id输入cn.fyy.spring,Artifact Id输入SPRING-01(本应该也是包名的一部分,但是,暂且作为项目名),Packaging选择war(也可以是jar,后续实际使用的其实都会是war)。
创建出来的项目默认没有web.xml文件,作为WEB项目来说是错误的,所以,需要先生成该文件。
然后,需要添加所以依赖的框架,在pom.xml中添加spring-webmvc的依赖(其实,目前只要使用spring-context依赖,而spring-webmvc中包含该依赖,后续学习SpringMVC框架时就必须使用spring-webmvc):
org.springframework
spring-webmvc
4.3.8.RELEASE
目前,对使用的Spring的要求是不低于4.2版本。
当项目创建完成后,将文件applicationContext.xml复制到项目中的src/main/resources中。
假设希望通过Spring创建java.util.Date类的对象,则应该在applicationContext.xml中添加配置:
接下来,可以通过单元测试查看配置效果,需要先添加单元测试的依赖:
public class TestCase {
@Test
public void getDate() {
// 1. 加载Spring配置文件,获得Spring容器
ClassPathXmlApplicationContext ac
= new ClassPathXmlApplicationContext(
"applicationContext.xml");
// 2. 从Spring容器中获取对象
Date date = (Date) ac.getBean("date");
// 3. 测试所获取的对象
System.out.println(date);
// 4. 关闭Spring容器,释放资源
ac.close();
}
}
4.0通过Spring创建对象的方式
(a) 类中存在无参数的构造方法(实用,掌握)
以java.util.Date类为例,当Spring创建对象时,会自动调用其无参数构造方法。
在Spring的配置文件中,配置方式为:
如果某个类中并不存在无参数的构造方法,则不可以通过这种方式进行配置。
(b) 类中存在静态工厂方法(不实用,了解)
如果某个类中存在某个static修饰的方法,且方法的返回值类型就是当前类的类型,例如java.util.Calendar类就是如此:
public abstract class Calendar {
public static Calendar getInstance() {
// ...
}
}
符合这种条件的类,可以配置为:
© 存在实例工厂方法(更不实用,了解)
在其他类中,存在某个工厂方法,可以创建指定的类的对象,例如:
public class Phone {
public Phone(String name) {
}
}
public class PhoneFactory {
public Phone newInstance() {
return new Phone("HuaWei");
}
}
当需要Spring创建Phone对象时,可以让Spring先创建PhoneFactory的对象(实例),然后调用该对象的newInstance()方法,即可获取Phone的对象,从而完成对象的创建过程。
具体配置为:
5.0由Spring管理的对象的作用域与生命周期
(a) 由Spring管理的对象的作用域
单例:单一实例,在某个时刻,可以获取到的同一个类的对象将有且仅有1个,如果反复获取,并不会得到多个实例。
单例是一种设计模式,其代码格式可以是:
public class King {
private static King king = new King();
private King() {
}
public static King getInstance() {
return king;
}
}
以上单例模式也称之为“饿汉式单例模式”,其工作特性为“程序运行初期就已经创建了该类的实例,随时获取实例时,都可以直接获取”,还有另外一种单例模式是“懒汉式单例模式”,其工作特性为“不到逼不得已不会创建类的对象”,其代码是:
public class King {
private static final Object LOCK = new Object();
private static King king;
private King() {
}
public static King getInstance() {
if (king == null) {
synchronized (LOCK) {
if (king == null) {
king = new King();
}
}
}
return king;
}
}
理论上来说,懒汉式的单例模式可能可以节省一部分性能消耗,例如整个系统运行了30分钟之后才获取对象的话,则前30分钟是不需要创建对象的!但是,这种优势只是理论上的优势,在实际应用时,2种单例模式的差异表现的并不明显!
通过以上单例模式的设计方式,可以发现单例的对象都是使用了static修饰的!所以,具有“唯一、常驻”的特性!
在Spring管理对象时,可以配置lazy-init属性,以配置是否为懒汉式的单例模式:
在Spring管理对象时,可以配置scope属性,以配置类的对象是否是单例的:
(b) 由Spring管理的对象的生命周期
生命周期描述了某个对象从创建到销毁的整个历程,在这个历程中,会被调用某些方法,这些方法就是生命周期方法,学习生命周期的意义在于了解这些方法的调用特征,例如何时调用、调用次数,以至于开发功能时,可以将正确的代码重写在正确的方法中!
以Servlet为例,其生命周期方法主要有init()、service()、destroy(),其中,init()和destroy()都是只执行1次的方法,而service()在每次接收到请求时都会被调用,且init()方法是创建对象之后就会执行的方法,destroy()是销毁对象的前一刻执行的方法,所以,如果有某个流对象需要初始化,初始化的代码写在destroy()方法中就是不合适的!反之,如果要销毁流对象,也不能把代码写在init()中!
由Spring管理的单例对象也并不是开发人员完全可控的,即不知道何时创建的,何时销毁的,所以,Spring提供了“允许自定义初始化方法和销毁方法”的做法,开发人员可以自行定义2个方法分别表示初始化方法和销毁方法:
public class User {
public User() {
super();
System.out.println("创建User对象……");
}
public void init() {
System.out.println("初始化方法被调用……");
}
public void destroy() {
System.out.println("销毁方法被调用……");
}
}
配置:
注意:生命周期方法的配置是建立在“单例”基础之上的,如果对象并不是单例的,讨论生命周期就没有意义了。
6.0 Spring IoC
IoC:Inversion of Control,即“控制反转”,在传统的开发模式中,创建对象和管理对象都是由开发人员自行编写代码来完成的,可以理解为“开发人员拥有控制权”,在使用了Spring之后,开发人员需要做的就只是完成相关配置即可,具体的创建过程和管理方式都是由Spring框架去实现的,可以理解为“把控制权交给了框架”,所以,称之为“控制反转”。
管理对象最重要的是“配置某个对象的属性”,假设User类中有public String name;属性,甚至希望获取User对象的同时,name属性已经是有值的了,Spring在处理属性值的时候,采取了DI(Dependency Injection,依赖注入)做法。
关于DI和IoC的关系:Spring框架通过DI实现了IoC,DI是实现手段,而IoC是实现的目标。
示例:
public class User {
public String name;
}
如果需要为name属性注入值,首先,需要为name属性添加SET方法:
public class User {
public String name;
public void setName(String name) {
this.name = name;
}
}
然后,在Spring的配置文件中添加配置:
其实,在配置name属性,取值应该是“需要注入值的属性对应的SET方法的方法名去除set字样并把首字母改为小写后得到的名称”,因为Spring在处理时,会将配置的值name的首字母改为大写,得到Name,然后在左侧拼接set,以得到setName这个名称,然后,尝试调用名为setName的方法!
由于Eclipse等开发工具生成SET方法的模式与Spring得到SET方法的模式是完全相同的,所以,可以粗略的理解为name属性值就是需要注入的属性名称!
6.1. 通过SET方式注入属性的值
假设存在:
public class UserDao {
public String driver; // com.mysql.jdbc.Driver
}
如果需要为driver注入值,首先需要为该属性添加SET方法(强烈建议使用开发工具生成SET方法,不要手动编写):
public void setDriver(String driver) {
this.driver = driver;
}
然后,在Spring的配置文件中,添加
另外,如果某个属性的值并不是基本值(在Spring中,把基本数据类型的值和字符串统一称为基本值),例如:
public class UserServlet {
public UserDao userDao;
}
以上属性的值应该是前序创建的UserDao类的对象,则,在配置时,可以通过ref属性引用那个id:
综合来看,无论属性的值是什么类型,只要是通过SET方式注入属性值,首先都必须为属性添加SET方法,然后在value属性直接编写对应的值,如果属性的值不是基本值,则使用ref属性引用另一个id(如果没有所说的另一个
6.2. 通过构造方法注入属性的值
假设存在:
public class AdminDao {
public String url;
public AdminDao(String url) {
super();
this.url = url;
}
}
在配置时:
7.0. 注入集合类型的属性值
7.1. List
假设存在:
// Frank, Andy, Lucy, Kate
public List names;
如果希望通过SET方式注入属性的值,需要先生成SET方法,然后,配置为:
Frank
Andy
Lucy
Kate
Spring框架在处理时,会使用ArrayList封装List类型的属性的值。
7.2. Set
假设存在:
// Beijing, Shanghai, Guangzhou, Shenzhen
public Set cities;
则配置为:
Beijing
Shanghai
Guangzhou
Shenzhen
Spring框架在处理时,会使用LinkedHashSet封装Set类型的属性的值。
7.3. 数组
假设存在:
// { 9, 5, 2, 7 }
public int[] numbers;
则配置为:
9
5
2
7
其实,在Spring框架中,注入List集合类型的值和数组类型的值时,使用List类型的,使用
7.4. Map
假设存在:
// username=root, password=1234, from=Hangzhou, age=26
public Map session;
则配置为:
7.5. Properties
在配置Properties类型的属性值时,其配置的节点结构是:
root
1234
另外,也可以准备专门的**.properties文件,例如在src/main/resources下创建db.properties**文件:
url=jdbc:mysql://localhost:3306/db_name?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
driver=com.mysql.jdbc.Driver
username=root
password=1234
然后,在Spring的配置文件中,使用
以上ref引用这个节点:
8. Spring表达式
Spring表达式是使用占位符的方式定义在Spring的配置文件中的,作用是用于获取其他
假设存在:
public class ValueBean {
// 值是SampleBean中的names中的第2个
public String name;
}
首先,需要确定注入值的方式,可以是通过SET方式注入,也可以通过构造方法注入,如果选择通过SET方式注入,需要先生成SET方法:
public void setName(String name) {
this.name = name;
}
然后,在Spring的配置文件中进行配置:
可以发现,Spring表达式的基本格式是使用#{}进行占位,其内部语法是:
#{bean的id.属性}
如果属性的类型是List集合、Set集合或者数组,则在属性右侧使用[]写出索引或者下标:
#{bean的id.属性[索引或者下标]}
如果属性的类型是Map集合或者Properties,可以使用的语法:
#{bean的id.属性.key}
#{bean的id.属性['key']}
9. 自动装配(autowire)
自动装配:不需要在Spring的配置文件中进行属性值的注入,只需要配置允许自动装配,Spring就会自动的完成属性值的注入。
假设存在StudentServlet依赖于StudentDao:
public class StudentServlet {
public StudentDao studentDao;
public void setStudentDao(StudentDao studentDao) {
this.studentDao = studentDao;
}
public void reg() {
System.out.println("StudentServlet.reg()");
studentDao.reg();
}
}
public class StudentDao {
public void reg() {
System.out.println("StudentDao.reg()");
}
}
就可以配置为:
以上配置中,autowire属性就是用于配置自动装配的。
当取值是byName时,表示“按照名称自动装配”,在这个过程中,Spring会先检测到在StudentServlet中有名为studentDao的属性,会根据该属性得到setStudentDao这个方法名称,然后,尝试找到与SET方法名称对应的bean的id,即查找某个id为studentDao的setStudentDao方法来完成自动装配,如果没有找到匹配的bean-id,则不会尝试自动装配。简单的来说,就是SET方法的名称需要与bean-id相对应,属性的名称可以和bean-id不对应。自动装配是一种“尝试性”的操作,能装就装,装不上也不会报错!
另外,还可以取值为byType,表示“按照类型自动装配”,在这个过程,Spring会检测StudentServlet中以set作为前缀的方法,并尝试调用这些方法,调用时,会在Spring容器中查找与参数类型相符合的bean,如果没有匹配的对象,则不自动装配,如果找到1个,则执行该方法,以完成自动装配,如果找到2个或者更多,则直接报错错误。
还有其它装配模式,一般不必了解。
在实际开发时,并不会使用这种方式来实现自动装配,因为这种做法存在的问题:属性是否被装配了,表现的不明显,如果不详细的阅读完整的源代码,根本无法确定类中的哪些属性被装配了值,而哪些属性没有被装配值!
目前,主要理解自动装配的思想,及byName和byType这2种装配模式的特性即可。
----------------------------
附1:List与Set
List中的元素是可以重复的,例如在同一个List中存储2个string-1,而Set中的元素是不可以重复的,例如在同一个Set中添加2个string-1,实际只会存储第1次添加的string-1,第2次添加的是相同的数据,则不会被存储下来!判断“元素是否相同”的标准是:调用equals()对比的结果是true,并且2个元素的hashCode()返回值相同。
List是序列的集合,典型的实现类有ArrayList和LinkedList,其中,ArrayList查询效率高,但是修改效率低,而LinkedList查询效率低,但是修改效率高。
Set是散列的集合,从实际表现来看,并不能说Set是无序的,例如TreeSet会把元素按照字典排序法进行排序,如果元素是自定义的数据类型,需要该类型实现Comparable接口,重写其中的int compareTo(T other)方法,实际上TreeSet会调用各元素的compareTo()方法实现排序,这个排序过程是运行时执行的,从数据存储的角度来看,数据在内存中依然是散列的,另外,还有LinkedHashSet是通过链表的形式将各个元素“链”起来的,所以,输出显示这种Set时,输出结果与添加元素的顺序是保持一致的!
所有Set都是只有key没有value的Map。
10. Spring注解
10.1. 通用注解
使用注解的方式来管理对象时,就不必在Spring的配置文件中使用
然后,为需要创建对象的类添加@Component注解即可:
@Component
public class UserDao {
}
也就是说,“组件扫描 + 注解”就可以实现Spring创建对象!
在配置组件扫描时,base-package表示“根包”,假设类都在cn.fyy.spring包中,可以直接配置为这个包,也可以配置为cn.fyy,甚至配置为cn都是可以的!一般不推荐使用过于简单的根包,例如实际使用的是cn.fyy.spring.dao、cn.fyy.spring.servlet等,可以把根包设置为cn.fyy.spring,却不建议设置为cn或者cn.fyy!
关于使用的注解,可以是:
-
@Component:通用注解 -
@Controller:添加在控制器之前的注解 -
@Service:添加在业务类之前的注解 -
@Repository:添加在处理持久层的类之前的注解
在配置Spring创建和管理对象时,在类之前添加以上4个注解中的任意1个即可,以上4个注解的作用相同,使用方式相同,语义不同。
在使用以上注解后,由Spring创建的对象的bean-id默认就是类名首字母改为小写的名称,例如UserDao类的默认bean-id就是userDao,如果需要自定义bean-id,可以对注解进行配置,例如:
@Component("dao")
public class UserDao {
}
10.2. 关于作用域与生命周期的注解
使用@Scope注解可以配置某类的对象是否是单例的,可以在该注解中配置属性为singleton或prototype,当配置为@Scope("prototype")时表示非单例的,如果希望是单例,则不需要配置该注解,默认就是单例的。
在单例的前提下,默认是饿汉式的单例,如果希望是懒汉式的单例模式,可以在类之前添加@Lazy注解,在该注解中还可以配置true或false,例如@Lazy(false),但是,没有必要这样配置,如果希望是饿汉式的,根本就不需要添加该注解,如果希望是懒汉式的,只需要配置@Lazy即可,而不需要写成@Lazy(true)。
在被Spring管理的类中,可以自定义方法,作为初始化方法和销毁时调用的方法,需要添加@PostConstruct和@PreDestroy注解,例如:
@Component
public class UserDao {
public UserDao() {
System.out.println("创建UserDao的对象!");
}
@PostConstruct
public void init() {
System.out.println("UserDao.init()");
}
@PreDestroy
public void destroy() {
System.out.println("UserDao.destroy()");
}
}
以上2个注解是javax包中的注解,使用时,需要为项目添加Tomcat运行环境,以使用Java EE相关的jar包,才可以识别以上2个注解!
10.3. 自动装配
假设存在:
@Repositor
public class UserDao {
public void reg() {
System.out.println("UserDao.reg()");
}
}
如果存在UserServlet需要依赖于以上UserDao,则在UserServlet中的属性之前添加@Autowired注解即可,例如:
@Controller
public class UserServlet {
@Autowired
public UserDao userDao;
public void reg() {
System.out.println("UserServlet.reg()");
userDao.reg();
}
}
当然,以上2个类都必须是被Spring所管理的,即:都在组件扫描的包下,且都添加了@Component或等同功能的注解。
通过注解实现自动装配时,并不需要属性有SET方法!Spring框架就是将值直接赋值过去的!
使用@Resource注解也可以实现自动装配,它是Java EE中的注解,它的装配模式是:优先byName实现装配,如果装配失败,会尝试byType实现装配,且,如果byType装配,要求匹配类型的对象必须有且仅有1个,无论是0个还是超过1个,都会报告错误!
使用@Resource时还可以配置需要注入的bean的id,例如:
@Resource(name="ud1")
使用@Autowired时,会优先byType,如果找到1个匹配类型的对象,则直接装配,如果没有匹配类型的对象,则直接报告错误,如果找到多个匹配类型的对象,则会尝试byName,如果byName装配失败,则报告错误!
2. Spring小结
-
Spring的作用是创建和管理对象,使用Spring可以实现解耦;
-
掌握
id和class属性的配置; -
了解
scope、lazy-init、init-method、destroy-method属性的配置; -
了解
factory-bean和factory-method属性的配置; -
掌握通过SET方式注入属性的值,掌握
value和ref属性的选取原则; -
了解通过构造方法注入属性的值;
-
了解注入各种集合类型的属性的值;
-
掌握通过Spring读取**.properties**文件的方式;
-
掌握通过Spring表达式读取其它bean中的属性;
-
理解自动装配的
byName和byType的特性; -
掌握
@Component、@Controller、@Service、@Repository这4个注解的使用; -
掌握组件扫描的配置方式;
-
了解
@Scope、@Lazy、@PostConstruct、@PreDestroy注解的使用; -
掌握
@Autowired或@Resource的使用,理解它们的装配方式。
------------------------------------------
附1:内存溢出/内存泄漏/Leak
内存溢出并不是“使用的内存超出了限制”,如果是使用的内存超出了限制,会直接出现OutOfMemoryError。
内存溢出通常是因为程序意外崩溃,而某些资源并没有被释放!例如:尝试读取硬盘上的某个文件,假设使用了FileInputStream fis变量,在读取过程中,出现了IOException导致程序崩溃,则fis变量就不再可用,变量对应的流对象可能还处于与硬盘上的文件是连接的状态,所以就会出现“作为程序员来说,已经无法控制这个对象了,但是,由于对象仍然处于连接状态,JVM中的垃圾回收机制并不会把它当做垃圾进行回收”,这样的数据如果越来越多,就会无谓的浪费更多的内存,导致可用内存越来越少,最终,继续积累的话,就会导致“溢出”。
所以,少量的内存溢出其实是没有明显的危害的!但是,仍然应该尽可能的处理掉所有可能存在的内存溢出问题!最简单的解决方案就是“随时用完随时关闭”。