深度学习之风格转换——Style Transfer
最近在学习CS20课程——一门讲述tensorflow应用的实践性课程,正好Assignment2讲到了Style Transfer这个东西,这里把我的理解总结一下(代码基于Tensorflow)。
代码:
chiphuyen/stanford-tensorflow-tutorials/assignments/02_style_transfer/
论文:Bringing Impressionism to Life with Neural Style Transfer in Come Swim https://arxiv.org/pdf/1701.04928v1.pdf
简介
这是一个使用两个图片(以A和B表示)作为输入(图A作为内容输入(content input),图B作为风格输入(style input)。最终的目的是得到一张具有图B的风格和图A的内容的图像。
- style picture

- content picture

what we got

用一个简单的方程可以表示为:style + content = picture of highly abstracted
步骤简述
- 使用一个训练好的CNN结构(一般来说做Image classification的就可以,比如VGG, GoogLeNet等等)
- 我们要有一个概念:CNN中低层特征图保留的内容比较多,而高层更多的是纹理,正是利用这一点,我们将组合内容信息和纹理信息并将两者相结合得到一个全新的图片。
对content和style分别定义损失函数,并将其组合起来作为整个结构的Loss function。
值得注意的是,我们输入时候使用的结构使用的是一样的结构(无论是style pic、content pic还是trianable input),为了避免重复的子计算图装配(To save us from having to assemble the same subgraph multiple times, we will use one variable for all three of them.),需要使用tf.variable_scope(‘input’)。
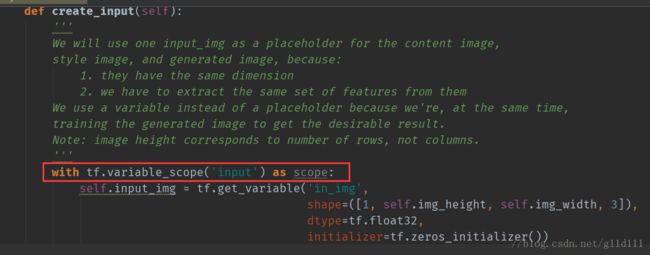
跟之前的CNN中通过反向传播调整网络结构参数如w和b不同的是,这里的目标是对一个输入的content pic加入白噪声后的图片进行不断调整,给其加入内容和纹理信息。
损失函数说明
其中α和β是权重,论文指出α/β=0.001或者0.0001,这个比例是根据内容和风格的比例来调整的,当你想要风格更浓烈,就提高α/β的值,反之则降低α/β。
1. content loss
content loss比较容易理解,论文里定义如下:
假设某一层 l l 得到的响应是
这里的 Fli,j F i , j l 是层 l l 生成图像的特征表示(content representation of the generated image), Pli,j P i , j l 是层 l l 内容图像的特征表示(content representation of the content image)。实际上就是关于 F F 和 P P 的均方误差。论文中建议使用的layer是conv4_2。
下面翻译自CS20 Assignment2 的note
然而在实践中发现,这个content loss收敛的很慢。所以这里可以将前面的系数1/2换成1/(4s)。s为 P P 的所有维度的乘积,比如 P P 为[5, 5, 3]。那么s = 5*5*3=75。
2. style loss
style loss有些复杂,在论文中,它有三步计算得来。首先让我们来看style loss的定义:
这里 Nl N l 是层 l l 的卷积核(filter)个数, Ml M l 为特征图的高和宽的乘积。这里, A A 是原图的Gram矩阵, G G 为生成图像的Gram矩阵。
Gram矩阵的计算方式是: Gli,j=∑kFli,k∗Flj,k G i , j l = ∑ k F i , k l ∗ F j , k l 。即为同一层 l l 各个不同的特征图的偏心协方差矩阵。在feature map中,每一个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字就代表一个特征的强度,而Gram计算的实际上是特征之间的相关性——“哪两个特征是同时出现的,哪两个是此消彼长”。
以层 l l 为例,当很多feature map的同一个位置上的数值越小,那么我们得到的Gram中此位置的值就越小;当很多feature map的同一个位置上的数值越大,那么我们得到的Gram中此位置的值就越大。
所以Gram矩阵这里的作用是:在能够在保证内容的情况下,进行风格的渲染
这里的 l l 表示了我们想要吸收进生成图像style的特征图,论文中建议取:

代码中对应的权值为:
![]()
试验
定义完毕之后,就回到最开始的Total loss:
这里再次强调,我们训练的参数不是VGG或者GoogLenet里面的 W W 和 b b ,而是输入的content pic + noise的内容(为其加上content和style信息)
content pic

style pic
- 加噪声的intial pic

- 使其变为

参考资料(Reference)
[1]Bringing Impressionism to Life with Neural Style Transfer in Come Swim
[2]Gram Matrices理解
[3]如何用简单易懂的例子解释格拉姆矩阵/Gram matrix?
[4]tensorflow学习笔记(七):TensorFLow实战之style_transfer(风格转换)