Centos下部署Hadoop2.6.5
Centos下部署Hadoop2.6.5
一、Hadoop简介
说到Hadoop,就必须先说说大数据,我们知道,大数据包括了以Hadoop和Spark为代表的基础大数据框架,其中又包括了实时数据处理、离线数据处理、数据分析、数据挖掘、机器算法、进行预测分析等技术。

那么Hadoop简单的说就是开源的大数据框架和分布式计算的解决方案(HDFS和MapReduce)
hdfs:
1.数据块:以块为存储单元(屏蔽了文件的概念,抽象),便于备份。
2.NameNode:管理文件系统的命名空间,存放数据元数据。
3.DataNode: 存储并检索数据块,向NameNode更新存储块列表。
优点:
1.适合大文件存储,支持TB、PB级的数据存储
2.可以构建在廉价的机器上,并有一定的容错和恢复机制
3.支持流式数据访问,一次写入,多次读取
缺点:
1.不适合大量小文件存储
2.不适合并发写入,不支持文件随机修改
3.不支持随机读取等低延时的访问方式
在说MapReduce之前,先说说YARN
YARN
YARN是Hadoop2.x之后版本的资源管理器,负责资源的管理和调度,所有的MapReduce程序都需要通过YARN来进行调度。
ResourceManager
- 分配和调度任务
- 启动并监控ApplicationManager
- 监控NodeManager
ApplicationManager
- 为MR类型的程序申请资源,并分配个内部任务
- 负责数据的切分
- 监控任务的执行和容错
NodeManager
- 管理单个节点的资源
- 处理 来自ResourceManager和ApplicationManager和命令
MapReduce 编程模型
输入一个大文件,通过split之后,将其分为多个分片,每个文件分片由单独的机器去处理,这就是Map方法;将各个机器计算的结果进行汇总并得到的最终的结果,这就是Reduce方法。
二、搭建Hadoop集群
1.环境
- 系统:Centos6.5
- 软件版本:Hadoop-2.6.5
集群架构:
master(NameNode):192.168.239.138
slave1(DataNode):192.168.239.139
slave2(DataNode):192.168.239.140ssh:主节点免密连接从节点
- jdk:java-1.8.0
2.Hadoop安装
建立hadoop用户:
groupadd hadoop
useradd -g hadoop hadoop
passwd hadoop
安装jdk:
yum install -y java-1.8*
java -version
编辑/etc/profile,将JAVA_HOME加入环境变量,不然后面启动hadoop会报错
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
保存后退出
source /etc/profile
下载和安装:
去Hadoop官网下载Hadoop-2.6.5,并解压到/usr/local:
tar xvf hadoop-2.6.5.tar.gz -C /usr/local/
修改目录的所有者和所属组:
chown -R hadoop.hadoop hadoop-2.6.5/
ln -s hadoop-2.6.5/ hadoop
接下来将hadoop目录下的bin加入到环境变量中:
export PATH=/usr/local/hadoop/bin:$PATH
source /etc/profile
测试hadoop 命令:
hadoop version

到这说明安装成功
3.Hadoop配置
配置文件的目录:
我们看到这里有很多文件,我们需要进行配置的文件有6个:
1.配置core-site.xml
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://192.168.239.138:9000value>
<final>truefinal>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/tmpvalue>
property>
<property>
<name>ds.default.namename>
<value>hdfs://192.168.239.138:54310value>
<final>truefinal>
property>
configuration>
2.配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/dfs/namevalue>
<final>truefinal>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/dfs/datavalue>
<final>truefinal>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
configuration>
3.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>192.168.239.138:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>192.168.239.138:19888value>
property>
configuration>
4.配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>192.168.239.138value>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>192.168.239.138:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>192.168.239.138:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>192.168.239.138:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>192.168.239.138:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>192.168.239.138:8088value>
property>
configuration>
5.配置masters和slaves
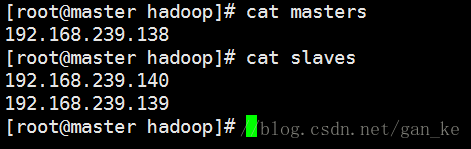
到这里,我们一台节点的配置已经完成,同样的操作配置其他两台节点,这里就省略过程,同时也省略配置ssh免密互连(还不会的同学请查阅相关文档)。
启动Hadoop
在master切换hadoop用户,并进行NameNode初始化:
hadoop namenode -format
之后启动集群:
/usr/local/hadoop/sbin/start-all.sh
发现有报错:
Error: JAVA_HOME is not set and could not be found.
之前明明将JAVA_HOME加入到环境变量了,为了确认,还 echo $JAVA_HOME,没有问题,之后又重启机器,还是报相同的错误,后来查阅相关资料才发现,修改配置文件hadoop-env.sh:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
将默认值修改为JAVA_HOME的绝对路径即可。
然后启动
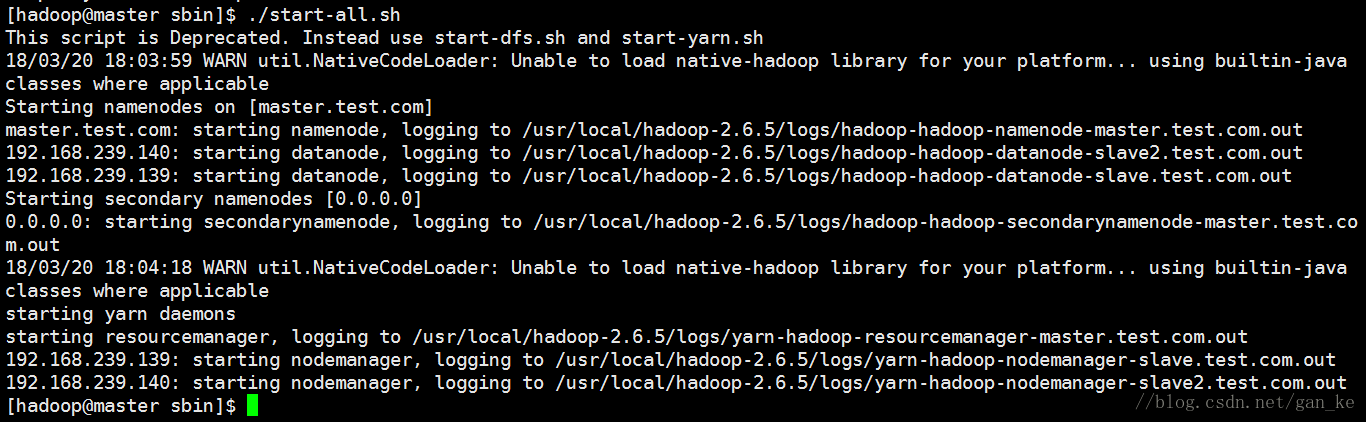
我们发现图片中有一个警告,加载不了本地库,我们可以直接在/usr/local/hadoop-2.6.5/etc/hadoop 修改log4j.properties:
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
然后重启即可。
验证:
master:输入jps

slave:输入jps

到这里,hadoop集群的搭建和配置就完成了,具体的使用和技巧后续会持续更新。