DIN论文官方实现解析
最近在看DIN的论文,顺便把论文中给的示例代码链接运行了一遍,这里做一个总结。
1. 基础数据
论文中用的是Amazon Product Data数据,包含两个文件:reviews_Electronics_5.json, meta_Electronics.json.
文件格式链接中有说明,其中reviews主要是用户买了相关商品产生的上下文信息,包括商品id, 时间,评论等。meta文件是关于商品本身的信息,包括商品id, 名称,类别,买了还买等信息。
2. 数据变换
utils/1_convert_pd.py
该程序
(1)将reviews_Electronics_5.json转换成dataframe,列分别为reviewID ,asin, reviewerName等,
(2)将meta_Electronics.json转成dataframe,并且只保留在reviewes文件中出现过的商品,去重。
(3)转换完的文件保存成pkl格式。
utils/2_remap_id.py
该程序
(1)将reviews_df只保留reviewerID, asin, unixReviewTime三列;
(2)将meta_df保留asin, categories列,并且类别列只保留三级类目;(至此,用到的数据只设计5列,(reviewerID, asin, unixReviewTime),(asin, categories));
(3)用asin,categories,reviewerID分别生产三个map(asin_map, cate_map, revi_map),key为对应的原始信息,value为按key排序后的index(从0开始顺序排序),然后将原数据的对应列原始数据转换成key对应的index;各个map的示意图如下:

(4)将meta_df按asin对应的index进行排序,如图:

(5)将reiviews_df中的asin转换成asin_map中asin对应的value值,并且按照reviewerID和时间排序。如图:
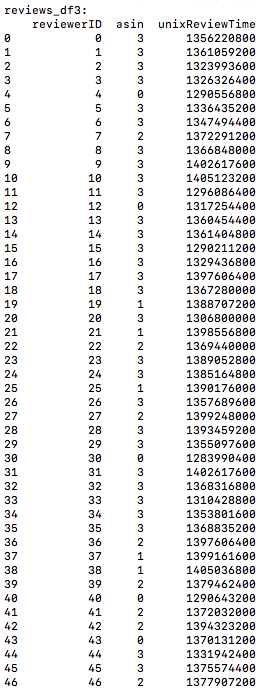
(6)生成cate_list, 就是把meta_df的'categories'列取出来。
![]()
3. 生成训练集和测试集
din/build_dataset.py
(1)将reviews_df按reviewerID进行聚合
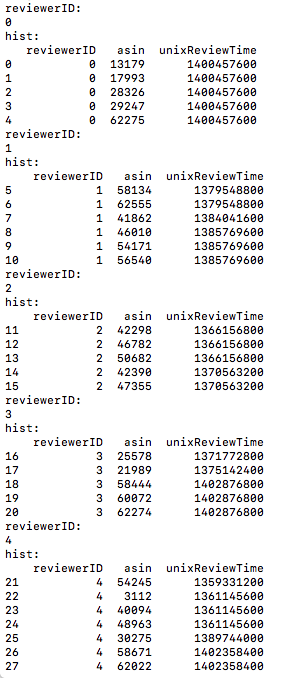
(2)将hist的asin列作为每个reviewerID(也就是用户)的正样本列表(pos_list),注意这里的asin存的已经不是原始的item_id了,而是通过asin_map转换过来的index。负样本列表(neg_list)为在item_count范围内产生不在pos_list中的随机数列表。
(3)接下来比较重要,得到pos_list后就开始构造训练集和测试集了。
训练集的构造方法:
如上图,例如对于reviewerID=0的用户,他的pos_list为[13179, 17993, 28326, 29247, 62275], 生成的训练集格式为(reviewerID, hist, pos_item, 1), (reviewerID, hist, neg_item, 0),这里需要注意hist并不包含pos_item, hist只包含在pos_item之前点击过的item,因为DIN采用类似attention的机制,只有历史的行为的attention才对后续的有影响,所以hist只包含pos_item之前点击的item才有意义。例如,对于reviewerID=0的用户,构造的训练集为:
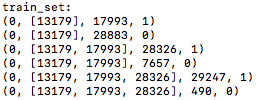
对于每个pos_list和neg_list的最后一个item,用做生成测试集,测试集的格式为(reviewerID, hist, (pos_item, neg_item))
![]()