MobileNet v1 和 v2 记录
最近在搞检测的cpu部署,对inference阶段的响应时间有较高的要求,所以就对mobilenet的学习记录一下。
一、MobileNet v1:
先上一个结构:
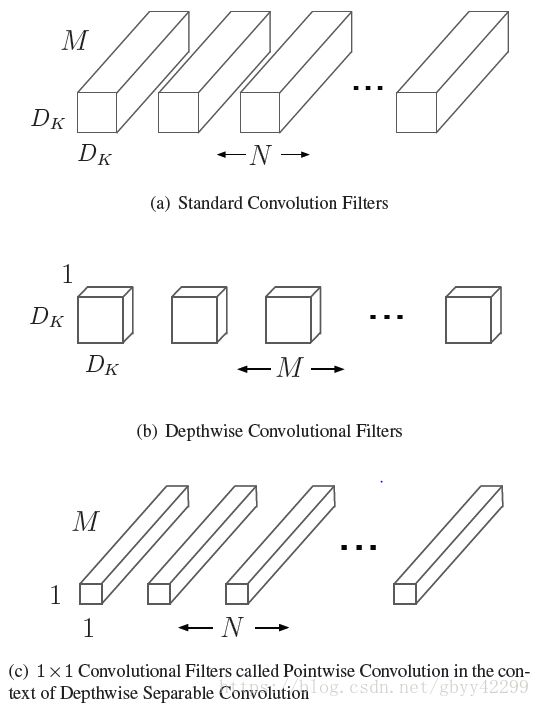
图a就是我们知道的标准意义的卷积,这个卷积可以等价于Depthwise和1x1的卷积的结合。那么为什么可以这样呢?我们先给出答案:
depthwise conv只对输入通道进行卷积,没有对其进行组合来产生新的特征。因此下一层利用另外的层利用1x1卷积来对深度卷积的输出计算一个线性组合从而产生新的特征。
depthwise卷积:逐一通道处理的的二维卷积。这个概念可能比较难以理解,下面我详细的说一下什么是depthwise,各位看官也可以看看caffe实现的depthwise卷积。假设原来是3*3的卷积,那么depthwise separable convolution就是先用M个3*3卷积核一对一卷积输入的M个feature map,不求和,生成M个结果;然后用N个1*1的卷积核正常卷积前面生成的M个结果,求和,最后生成N个结果。见下图:

注意 : 这里卷积用 M 个,即与输入feature map通道数相同 ,而不是输出通道数 N 。
Mobilenet的结构定义如下:

深度卷积对每个通道使用一种卷积核,可以写成:Gk,l,m=∑i,jKi,j,m⋅Fk+i−1,l+j−1,mGk,l,m=∑i,jKi,j,m⋅Fk+i−1,l+j−1,m,其中K^K^是深度卷积核的尺寸DK∗DK∗MDK∗DK∗M,K^K^中第m个卷积核应用于F中的第m个通道来产生第m个通道的卷积输出特征图G^G^。
深度卷积的计算量为:DK∗DK∗M∗DF∗DFDK∗DK∗M∗DF∗DF。
![]()
这里基本就是v1里面比较重要的内容了,但是呢在很多情况下mobilenet的参数仍然过多,需要减少,所以作者引入了宽度乘法器和分辨率乘法器的概念,即:核心层的深度可分离卷积加上宽度乘法器α以及分辨率乘法器ρ来表达计算量:

二、MobileNet v2:
我们熟悉了v1的结构后来看v2,首先Mobilenet v2和v1的区别和其自身的创新如下:


1. Inverted residuals,通常的residuals block是先经过一个1*1的Conv layer,把feature map的通道数“压”下来,再经过3*3 Conv layer,最后经过一个1*1 的Conv layer,将feature map 通道数再“扩张”回去。即先“压缩”,最后“扩张”回去。 
而 inverted residuals就是 先“扩张”,最后“压缩”。为什么这么做呢?请往下看。
在上图中,我们可以看到:
a、ResNet是:压缩”→“卷积提特征”→“扩张”,MobileNetV2则是Inverted residuals,即:“扩张”→“卷积提特征”→ “压缩”:经过1x1的卷积可以扩大通道数,提升其抽取特征的能力。
b、最后不采用Relu,而使用Linear代替:
Relu对于负的输入,输出全为零;而本来特征就已经被“压缩”,再经过Relu的话,又要“损失”一部分特征,因此这里不采用Relu。
总结:在通道数较少的层后,应该用线性激活代替ReLU。MobileNet V2的Linear bottleneck Inverted residual block中,降维后的1X1卷积层后接的是一个线性激活,其他情况用的是ReLU。
2.Linear bottlenecks,为了避免Relu对特征的破坏,在residual block的Eltwise sum之前的那个 1*1 Conv 不再采用Relu。
下图即为Inverted residuals的bottleneck,一个bottleneck由如下三个部分构成:

下图即为mobilenet v2的网络结构图:

其中:t表示“扩张”倍数,c表示输出通道数,n表示重复次数,s表示步长stride。
先说两点有误之处吧:
1. 第五行,也就是第7~10个bottleneck,stride=2,分辨率应该从28降低到14;如果不是分辨率出错,那就应该是stride=1;
2. 文中提到共计采用19个bottleneck,但是这里只有17个。
引用:https://zhuanlan.zhihu.com/p/33169767
https://zhuanlan.zhihu.com/p/39386719
https://blog.csdn.net/u011995719/article/details/79135818