Hadoop大数据框架研究(1)——基础环境准备
近期对hadoop生态的大数据框架进行了实际的部署测试,并结合ArcGIS平台的矢量大数据分析产品进行空间数据挖掘分析。本系列博客将进行详细的梳理、归纳和总结,以便相互交流学习。
测试环境及软件版本:
操作系统(虚拟机环境):CentOS-7-x86_64-DVD-1511
JDK:jdk-8u151-linux-x64.tar.gz
Hadoop:hadoop-2.7.5.tar.gz
Spark:spark-2.2.1-bin-hadoop2.7.tgz
Zookeeper:zookeeper-3.4.10.tar.gz
Hive:apache-hive-2.3.2-bin.tar.gz
MySQL:MySQL Community Server 5.7.21
ArcGIS:ArcGIS_Enterprise_Linux_1051_156418
A.机器名配置
1.[root@node1 /]# vim /etc/hostname
2.[root@node1 /]# vim /etc/hosts
修改各个节点的机器名及hosts
B.添加用户
1.[root@node1 /]# groupadd hadoop
2.[root@node1 /]# useradd -g hadoop -m hadoop
3.[root@node1 /]# passwd arcgis
4.[root@node1 /]# groupadd arcgis
5.[root@node1 /]# useradd -g arcgis -m arcgis
6.[root@node1 /]# passwd arcgis
添加相应的hadoop用户组和用户并设置密码(所有大数据相关组件都使用hadoop账号配置和使用)
添加相应的arcgis用户组和用户并设置密码(所有ArcGIS相关组件都使用arcgis账号配置、安装和使用)
C.网络环境配置
1.root用户进入到网络配置文件目录network-scripts
[root@node1bin]# cd /etc/sysconfig/network-scripts/
[root@node1 network-scripts]# vim ifcfg-eno16777736
TYPE=EthernetBOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
NAME=eno16777736
UUID=594c51e9-4c90-4620-bf3b-a10244a21149
DEVICE=eno16777736
ONBOOT=yes
IPADDR=192.168.10.100
DNS1=192.168.10.2
GATEWAY=192.168.10.2
PREFIX=24
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
3.重启网络服务
[root@node1 network-scripts]# systemctl restart network.service
4.查看ip配置
[root@node1 network-scripts]# ifconfig
D.防火墙设置
省心配置,关闭防火墙
[root@node1 /]# systemctl stop firewalld.service
[root@node1 /]#systemctl disable firewalld.service
E.JDK配置
1.查看已有jdk,CentOS7操作系统自带OpenJDK
[root@node1 /]# java -version

2.查询已安装的相关包
[root@node1 /]# rpm -qa|grep java
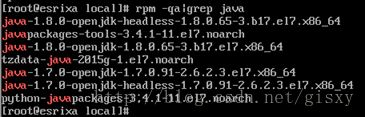
3.依次删除对应的包
[root@node1 /]# rpm -e –nodeps java-1.7.0-openjdk-headless
[root@node1 /]# rpm -e –nodeps java-1.7.0-openjdk
[root@node1 /]# rpm -e –nodeps java-1.8.0-openjdk-headless
[root@node1 /]# rpm -e –nodeps java-1.8.0-openjdk
4.下载对应版本JDK并在指定目录解压
Oracle的官网:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
[root@node1 /]# tar -zxvf jdk-8u151-linux-x64.tar.gz
5.编辑环境变量
[root@node1 /]# vim /etc/profile
增加下列几行内容
JAVA_HOME=/usr/local/jdk1.8.0_151
JRE_HOME=/usr/local/jdk1.8.0_151/jre
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
6.使环境变量生效并验证
[root@node1 /]# source /etc/profile
[root@node1 /]# java -version
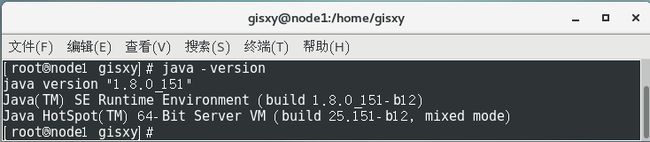
F.Linux的ssh免密码登陆配置
1.修改机器名和网络配置,确保相互之间可以访问。本测试环境使用五个虚拟机:
192.168.10.100——node1.gisxy.com
192.168.10.101——node2.gisxy.com
192.168.10.102——node3.gisxy.com
192.168.10.103——node4.gisxy.com
192.168.10.104——node5.gisxy.com
2.修改ssh config配置
root用户下 编辑sshd_config,开启ssh证书登录。
[root@node1 gisxy]# vim /etc/ssh/sshd_config
去掉配置[#RSAAuthentication yes,#PubkeyAuthenticationyes]前面的注释“#"号。其中AuthorizedKeysFile ——.ssh/authorized_keys,说明密钥信息存储在.ssh目录下的authorized_keys文件中。
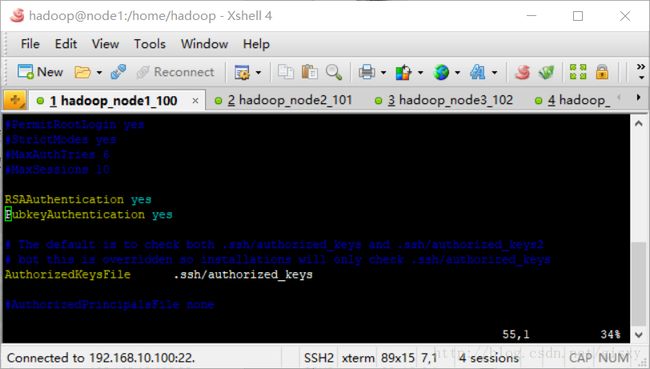
3.创建各个机器的ssh证书文件
使用hadoop用户登陆各个节点机器,创建/home/hadoop/.ssh目录。
[hadoop@node1 hadoop]# mkdir .ssh
并在.ssh目录下执行命令“ssh-keygen -t rsa",回车到底。在.ssh目录下可以看到文件——私钥id_rsa和公钥id_rsa.pub
[hadoop@node1 .ssh]# ssh-keygen -t rsa
5.合并id_rsa.pub信息,追加到authorized_key文件中
将node1的公钥写到node2的.ssh/authorized_key文件中
[hadoop@node1 .ssh]# ssh-copy-id -i id_rsa.pub [email protected]
在node2上生成密钥并追加到authorized_key
[hadoop@node2 .ssh]# ssh-keygen -t rsa
[hadoop@node2 .ssh]# cat id_rsa.pub >> authorized_keys
此时,node2上的authorized_keys文件包含node1和node2的密钥信息,以此类推,将authorized_keys文件传递到node3、node4、node5,并将各自的密钥信息追加到authoriz_keys,最后将node5的authorized_keys文件传递到其他各个节点,这样各个节点之间就可以实现免密登陆。
6.传递authorized_key文件到各个节点
使用hadoop用户,在.ssh目录下,将合并后的authorized_keys文件传递到各个节点。
[hadoop@node5 .ssh]$ scp authorized_keys had[email protected]:/home/hadoop/.ssh/
[hadoop@node5 .ssh]$ scp authorized_keys had[email protected]:/home/hadoop/.ssh/
[hadoop@node5 .ssh]$ scp authorized_keys had[email protected]:/home/hadoop/.ssh/
[hadoop@node5 .ssh]$ scp authorized_keys had[email protected]:/home/hadoop/.ssh/
测试登录(第一次需要输入密码)
在node1节点,使用hadoop用户登录后,输入ssh node2.gisxy.com等节点可以方便使用。
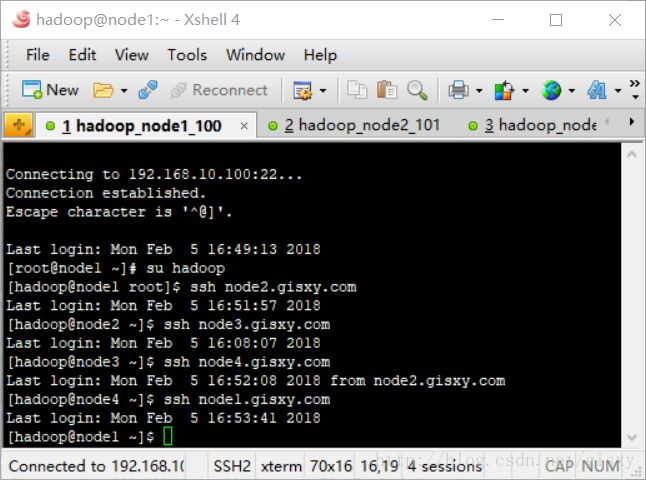
G.解除 Linux 系统的最大进程数和最大文件打开数限制
[root@esrixa home]# vim /etc/security/limits.conf
添加如下内容:
arcgis soft nofile 65535
arcgis hard nofile 65535
arcgis soft nproc 25059
arcgis hard nproc 25059
H.虚拟机CentOS与本机共享文件夹配置
1.首先需要在vmware的虚拟机设置中开启文件夹共享,并指定本地目录
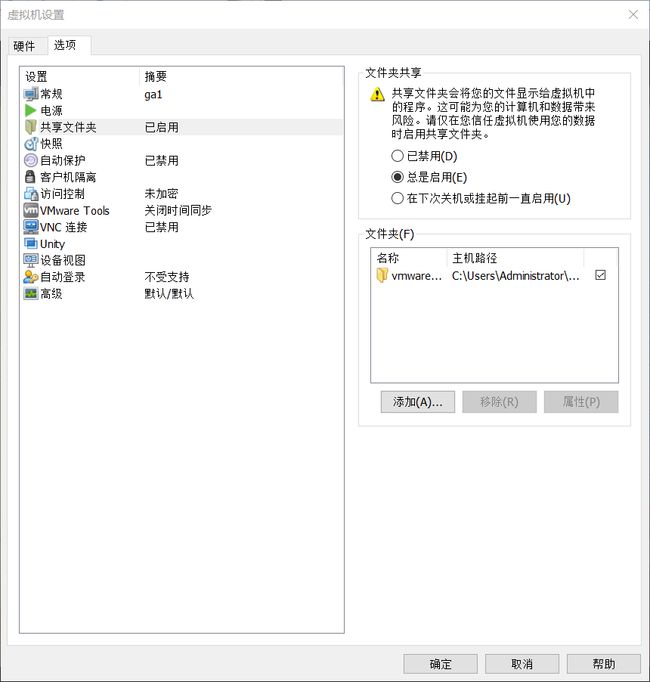
2.通过重新安装VMware Tools获取资源
3.挂载并提取文件到/home/tmp目录,然后解压
[root@ga1 tmp]# mkdir /mnt/cdrom
[root@ga1 tmp]# mount -t auto /dev/cdrom /mnt/cdrom
[root@ga1 tmp]# mkdir /mnt/cdrom
[root@ga1 tmp]# cp VMwareTools-10.1.15-6627299.tar.gz /home/tmp
[root@ga1 tmp]# tar -zxvf VMwareTools-10.1.15-6627299.tar.gz
4.安装vmware-tools
[root@ga1 tmp]# cd vmware-tools-distrib
[root@ga1 vmware-tools-distrib]# ./vmware-install.pl
5.一路回车后,cd到/mnt/hgfs查看验证
[root@ga1 hgfs]# cd /mnt/hgfs
[root@ga1 vmwareFiles]# ls
vmwareFiles
[root@ga1 hgfs]# cd vmwareFiles
[root@ga1 vmwareFiles]# ls
ArcGIS_Enterprise_Linux_1051_156418.iso
I.配置NFS
测试环境可以通过nfs来搭建共享存储环境
服务端设置:
1.创建共享目录
[root@ga1 home]# cd /usr/local
[root@ga1 local]# mkdir nfsShareFiles
2.编辑/etc/exports
[root@es1 home]# vim /etc/exports
增加如下内容
/usr/local/nfsShareFiles *(insecure,rw,sync,no_root_squash)
3.启动服务
重启rpc服务
[root@es1 home]# systemctl restart rpcbind.service
重启nfs服务
[root@es1 home]# systemctl restart nfs.service
客户端设置:
1.创建本地目录,用于挂载nfs
[root@ga1 local]# mkdir /home/arcgis/sitedatas
2.查看可挂载资源
[root@ga1 local]# showmount -e 192.168.10.101
Export list for 192.168.10.101:
/usr/local/nfsShareFiles *
3.挂载nfs目录到本地目录
[root@ga1 local]# mount -t nfs 192.168.10.101:/usr/local/nfsShareFiles /home/arcgis/sitedatas
4.上传文件到nfs目录,cd到本地目录查看编辑核查权限
Window环境的共享目录挂载
[root@ga1 sitedatas]# ls
yellow_tripdata_2014-01.csv yellow_tripdata_2014-04.csv
Z.其他内容:
1.文件权限设置
[root@node1 .ssh]# chmod -R 711 /home/hadoop/hadoop/hadoop275_tmp
[root@node1 .ssh]# chown arcgis:arcgis /data
2.kill进程或服务停止
[hadoop@node1 .ssh]$ netstat -nl | grep 2288
[hadoop@node1 .ssh]$ kill -9 2288
3.更新yum仓库
[root@node1 hadoop]# yum -y update