关于奇异值以及奇异值分解SVD的思考
前言:
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。SVD的原理不难,只要有基本的线性代数知识就可以理解,实现也很简单因此值得仔细的研究。当然,SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用
1,SVD的数学基础
1.1为什么要做SVD分解?
回顾特征值和特征向量
我们首先回顾下特征值和特征向量的定义如下:
其中 A 是一个 n×n 的矩阵, x 是一个 n 维向量,则我们说 λ 是矩阵A的一个特征值,而 x 是矩阵 A 的特征值 λ 所对应的特征向量。求出特征值和特征向量有什么好处呢? 就是我们可以将矩阵A特征分解。如果我们求出了矩阵A的 n 个特征值 λ1≤λ2≤...≤λn ,以及这n个特征值所对应的特征向量 {w1,w2,...wn} ,那么矩阵A就可以用下式的特征分解表示:
其中 W 是这 n 个特征向量所张成的 n×n 维矩阵,而 Σ 为这 n 个特征值为主对角线的 n×n 维矩阵。一般我们会把 W 的这 n 个特征向量标准化,即满足 ||wi||2=1 , 或者说 wTiwi=1 ,此时 W 的 n 个特征向量为标准正交基,满足 WTW=I ,即 WT=W−1 , 也就是说 W 为酉矩阵(不知道什么是 酉矩阵?)。
这样我们的特征分解表达式可以写成
注意到要进行特征分解,矩阵 A 必须为方阵。那么如果 A 不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了。
SVD的定义
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵 A 是一个 m×n 的矩阵,那么我们定义矩阵 A 的SVD为:
其中U是一个 m×m 的矩阵, Σ 是一个 m×n 的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值, V 是一个 n×n 的矩阵。 U 和 V 都是酉矩阵,即满足 UTU=I,VTV=I 。下图可以很形象的看出上面SVD的定义:

SVD的直观解释
下面的讨论需要一点点线性代数的知识。线性代数中最让人印象深刻的一点是,要将矩阵和空间中的线性变换视为同样的事物。比如对角矩阵 M 作用在任何一个向量上
其几何意义为在水平 x 方向上拉伸3倍, y 方向保持不变的线性变换。换言之对角矩阵起到作用是将水平垂直网格作水平拉伸(或者反射后水平拉伸)的线性变换。

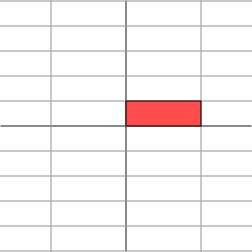
如果 M 不是对角矩阵,而是一个对称矩阵
那么,我们也总可以找到一组网格线,使得矩阵作用在该网格上仅仅表现为(反射)拉伸变换,而没有旋转变换
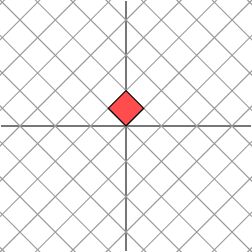

总结一下,对角矩阵的作用是对某一向量进行“正向”伸缩(即沿着 x 轴和 y 周),对称矩阵的所用是读某一向量进行“对称”伸缩(即沿着与对称抽对称的方向伸缩,对称轴是什么?上面的 M 矩阵中有两个向量分别是:(2,1)和(1,2),它们在坐标平面中两个点,这两个点的连线就是矩阵的对称轴)
考虑更一般的非对称矩阵
很遗憾,此时我们再也找不到一组网格,使得矩阵作用在该网格上之后只有拉伸变换(找不到背后的数学原因是对一般非对称矩阵无法保证在实数域上可对角化,不明白也不要在意)。我们退求其次,找一组网格,使得矩阵作用在该网格上之后允许有拉伸变换和旋转变换,但要保证变换后的网格依旧互相垂直。这是可以做到的
下面我们就可以自然过渡到奇异值分解的引入。奇异值分解的几何含义为:对于任何的一个矩阵,我们要找到一组两两正交单位向量序列,使得矩阵作用在此向量序列上后得到新的向量序列保持两两正交。下面我们要说明的是,奇异值的几何含义为:这组变换后的新的向量序列的长度。
看到这里你可能又糊涂了。我们不妨回过头来,看一下SVD的定义:
其中,矩阵 U 和 VT 分别是 m×m 和 n×n 的酉矩阵,酉矩阵的意思就是其转置与本身的乘积为单位矩阵。其实就是我们本科学的正交矩阵,只不过酉矩阵将正交矩阵的实数域扩展到了复数域。对于酉矩阵而言,如果其为方阵,那么这个酉矩阵的行(列)向量就构成了一组 标准正交基
(模为1的正交基向量)由于 VT=V−1 因此等式两边都右乘 V 得到:


当矩阵 M 作用在正交单位向量 v1 和 v2 上之后,得到 Mv1 和 Mv2 也是正交的(此时我们的 V 矩阵被表示成这个样子: V=(v1,v2) , v1,v2 分别为列向量)。令 u1 和 u2 分别是 Mv1 和 Mv2 方向上的单位向量,即 Mv1=σ1u1,Mv2=σ2u2 ,写在一起就是 M[v1v2]=[σ1v1σ2v2] ,整理得:
这样就得到矩阵的奇异值分解。奇异值和分别是和的长度。很容易可以把结论推广到一般 n 维情形。
下面给出一个更简洁更直观的奇异值的几何意义。
假设 A 的奇异值分解为:
其中是 u1,u2,v1,v2 二维平面的向量(例如 u1=(3,4) )。根据奇异值分解的性质, u1,u2 线性无关, v1,v2 线性无关(前面已经说了,它们互相正交)。那么对二维平面上任意的向量 x ,都可以表示为: x=ξ1v1+ξ2v2 。
当 A 作用在 x 上时,
令 η1=3ξ1,η2=ξ2 ,我们可以得出结论:如果是 x 在单位圆 ξ21+ξ22=1 上,那么 y 正好在椭圆 ξ21/32+ξ22/12=1 上。这表明:矩阵 A 将二维平面中单位圆变换成椭圆,而两个奇异值正好是椭圆的两个半轴长,长轴所在的直线是 span(u1) ,短轴所在的直线是 span(u2) .(span函数是?–span()表示以括号里的向量做基底,拓展的线性空间
)
推广到一般情形:一般矩阵 A 将单位球 ∥x∥2=1 变换为超椭球面 Em={y∈Cm:y=Ax,x∈Cm,|x|2=1|} ,那么矩阵的每个奇异值恰好就是超椭球的每条半轴长度。
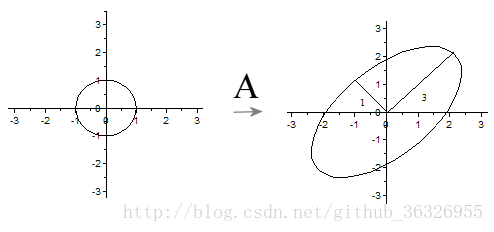
与特征值分解的联系
奇异值分解能够用于任意 m×n 矩阵,而特征分解只能适用于特定类型的方阵,故奇异值分解的适用范围更广。不过,这两个分解之间是有关联的。给定一个M的奇异值分解,根据上面的论述,两者的关系式如下:
关系式的右边描述了关系式左边的特征值分解。于是:
V 的列向量(右奇异向量)是 MTM 的特征向量。
U 的列向量(左奇异向量)是 MMT 的特征向量。
Σ 的非零对角元(非零奇异值)是 MTM 或者 MMT 的非零特征值的平方根。
手工推导见下图:

为什么要做SVD?
上面几节我们对SVD的定义做了详细的描述,似乎看不出我们费这么大的力气做SVD有什么好处。那么SVD有什么重要的性质值得我们注意呢?
对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的 r 个的奇异值和对应的左右奇异向量来近似描述矩阵。也就是说:
其中r要比n小很多,也就是一个大的矩阵 A 可以用三个小的矩阵来表示。如下图所示,现在我们的矩阵 Data 只需要灰色的部分的三个小矩阵就可以近似描述了。那么在实际操作中,我们是如何知道仅需要保留 r 个奇异值呢?
确定 r 的值有很多启发式的算法。当然,最直接的是直接用肉眼观察。
除此之外,一个典型做法是保留矩阵中90%的能量信息。具体来讲,我们可以对奇异值求平方和。于是可以对奇异值的平方和累加直至总和的90%为止。
另一个启发式的策略是,当矩阵上有上千万的奇异值时,那么就保留前面的2000或3000个。尽管不优雅,但是很有效。
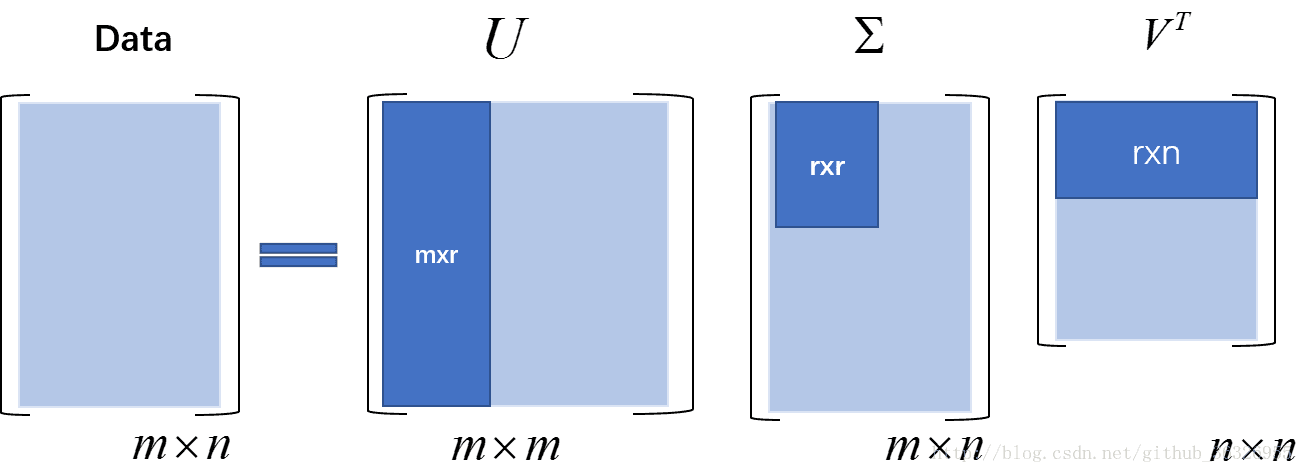
图注:上图中, Datai,j=uTiΣvj , uTi, 和 vj, 分别是矩阵 U 和 VT 的行向量和列向量。
由于 r 值这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)。
当然,降维、去噪声在不同的领域里,有不同的内涵。
我们看一个例子:
假设这个 Data 矩阵表示的是某个网站 m 个用户对 n 个商品的评分矩阵,在推荐系统中,我们常常希望根据用户的评分求某几个商品的相似度。如果我们不进行SVD分解,那么每两个商品-用户向量(也就是 Data 矩阵中的某两列)的维度是 m 维,你可以想想一下,淘宝网的用户应该有多少。按照这个数量级,商品-用户向量(也就是 Data 矩阵中的某两列)将高达几百万维度,我们做这两个向量的相似度将非常计算将非常巨大,而且这还仅仅是两个向量。
现在我们通过SVD分解后,发现对于每一个商品而言,实际具有代表性的用户(你也可以称之为意见领袖)只有 r 个,而且很幸运,根据我们刚才讨论的SVD性质,这个 r 相比于 m 而言,应该是极大的变小了的。这样一来,我们在矩阵 Data 中求某两列的相似性,可以移植到 VT 矩阵中前 r 行子矩阵。这个 r×n 的子矩阵有一个非常好的特点,那就是在行数上由 m 降低到 r ( r≪m ),而列数等于商品个数( n ),这样我们计算任意两个商品相似度时候,每个商品-用户向量(也就是这个子矩阵的某一列)只有2个维度。这就叫做“降维”。
同样的道理,如果我们希望计算某两个用户的相似度,我们也可以将其移植到矩阵 U 中前 r 列构成的子矩阵中。这个子矩阵保留了所有用户,但是简化了商品数目。也实现了降维。
那么现在的问题是,他们是怎么简化的呢?换言之,对于 VT 矩阵中前 r 行构成的子矩阵,他们的列我们知道表示的是商品,与矩阵 Data 是对应的,那么他们的每一行表示的是哪个用户呢?
其实,他们的每一行表示的不是 Data 中的哪个用户,而是根据奇异值,对 Data 中的用户进行了分组。也就是说,将 m 个用户,分成了 r 组,每一组叫做一个抽象用户,或者叫做映射用户。那么,对于其中的某一行而言,这一行就是某个抽象用户对商品的打分情况。然而,有趣的是,这一行中的每一个分数值,并没有什么实际意义。只是在计算相似性的时候,有价值,或者说,这个分数值,只是一个相对于其他向量的相对值。在实际工作中,你常常会发现,本来我们规定打分是0-5区间的数值,但是你看一下这个矩阵,里面常常是负数。这也是为什么,有人说矩阵分解的缺陷就是解释性不强的原因。
同样的道理,相信你也可以理解 U 矩阵的含义了。
整理一下我们看到,对 VT 矩阵,我们使用的是他的前 r 行构成的子矩阵,这个子矩阵保留了所有商品的信息,但是简化了用户的构成。因此,我们说 VT 矩阵将用户映射到了一个“奇异空间”中,即,本来人家是 m 用户, m 维的向量,现在让你映射到了 r 维。变成了 r 个映射用户了。同样的,我们也说,矩阵 U 将商品映射到了“奇异空间”中去了。
那么这个“奇异空间”是什么呢?
对的,就是奇异矩阵构成的空间。准确的说,是上图中那个 r×r 的子矩阵,他将 n 维商品,映射到了 r 维抽象商品中,将 m 维用户,映射到了 r 维抽象用户中。
1.2 SVD的计算过程
回顾一下:
那么我们如何求出SVD分解后的 U , Σ , V 这三个矩阵呢?这部分,在上一节的开头部分已经说了。
如果我们将 A 的转置和 A 做矩阵乘法,那么会得到 n×n 的一个方阵 ATA 。既然 ATA 是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:
这样我们就可以得到矩阵 ATA 的 n 个特征值和对应的 n 个特征向量 v 了。将 ATA 的所有特征向量张成一个 n×n 的矩阵 V ,就是我们SVD公式里面的 V 矩阵了。一般我们将 V 中的每个特征向量叫做 A 的右奇异向量。
如果我们将 A 和 A 的转置做矩阵乘法,那么会得到 m×m 的一个方阵 AAT 。既然 AAT 是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:
这样我们就可以得到矩阵 AAT 的 m 个特征值和对应的 m 个特征向量 u 了。将 AAT 的所有特征向量张成一个 m×m 的矩阵 U ,就是我们SVD公式里面的 U 矩阵了。一般我们将 U 中的每个特征向量叫做A的左奇异向量。
U 和 V 我们都求出来了,现在就剩下奇异值矩阵 Σ 没有求出了。由于 Σ 除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值 σ 就可以了。
我们注意到:
这样我们可以求出我们的每个奇异值,进而求出奇异值矩阵 Σ 。进一步我们还可以看出我们的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
这样也就是说,我们可以不用 σi=Avi/ui 来计算奇异值,也可以通过求出ATA的特征值取平方根来求奇异值。
SVD计算举例
这里我们用一个简单的例子来说明矩阵是如何进行奇异值分解的。我们的矩阵A定义为:
我们首先求出 ATA 和 AAT :
进而求出 ATA 的特征值和特征向量:
接着求 AAT 的特征值和特征向量:
利用 Avi=σiui,i=1,2 求奇异值:
当然,我们也可以用 σi=λi−−√ 直接求出奇异值为 3√ 和1.
最终得到 A 的奇异值分解为:
Python 实现:
本节首先给出工程应用中,我们直接使用Skearn库做SVD的代码,并进行详细的解释。然后再给出SVD的模型实现代码。
2, SVD用于推荐
2.1 推荐系统概述
正在更新
2.2 为什么要用矩阵分解?
在推荐系统中,我们常常遇到的问题是这样的,我们有很多用户和物品,也有少部分用户对少部分物品的评分,我们希望预测目标用户对其他未评分物品的评分,进而将评分高的物品推荐给目标用户。对于每个用户,我们希望较准确的预测出用户对未评分物品的评分。对于这个问题我们有很多解决方法,本文我们关注于用矩阵分解的方法来做。如果将m个用户和n个物品对应的评分看做一个矩阵M我们希望通过矩阵分解来解决这个问题。
2.3 传统的SVD用于推荐
说道矩阵分解,我们首先想到的就是奇异值分解SVD。此时可以将这个用户物品对应的m×n矩阵M进行SVD分解,并通过选择部分较大的一些奇异值来同时进行降维,也就是说矩阵M此时分解为:
可以看出这种方法简单直接,似乎很有吸引力。但是有一个很大的问题我们忽略了,就是SVD分解要求矩阵是稠密的,也就是说矩阵的所有位置不能有空白。有空白时我们的M是没法直接去SVD分解的。大家会说,如果这个矩阵是稠密的,那不就是说我们都已经找到所有用户物品的评分了嘛,那还要SVD干嘛! 的确,这是一个问题,传统SVD采用的方法是对评分矩阵中的缺失值进行简单的补全,比如用全局平均值或者用用户物品平均值补全,得到补全后的矩阵。接着可以用SVD分解并降维。
虽然有了上面的补全策略,我们的传统SVD在推荐算法上还是较难使用。因为我们的用户数和物品一般都是超级大,随便就成千上万了。这么大一个矩阵做SVD分解是非常耗时的。那么有没有简化版的矩阵分解可以用呢?我们下面来看看实际可以用于推荐系统的矩阵分解。
2.4 FunkSVD算法用于推荐
FunkSVD是在传统SVD面临计算效率问题时提出来的,既然将一个矩阵做SVD分解成3个矩阵很耗时,同时还面临稀疏的问题,那么我们能不能避开稀疏问题,同时只分解成两个矩阵呢?也就是说,现在期望我们的矩阵M这样进行分解:
我们知道SVD分解已经很成熟了,但是FunkSVD如何将矩阵M分解为P和Q呢?这里采用了线性回归的思想。我们的目标是让用户的评分和用矩阵乘积得到的评分残差尽可能的小,也就是说,可以用均方差作为损失函数,来寻找最终的P和Q。
对于某一个用户评分mij,如果用FunkSVD进行矩阵分解,则对应的表示为q_j^Tp_i,采用均方差做为损失函数,则我们期望 (mij−qTjpi)2 尽可能的小,如果考虑所有的物品和样本的组合,则我们期望最小化下式:
当然,在实际应用中,我们为了防止过拟合,会加入一个L2的正则化项,因此正式的FunkSVD的优化目标函数J(p,q)是这样的:
则在梯度下降法迭代时,pi,qj的迭代公式为:
通过迭代我们最终可以得到P和Q,进而用于推荐。FunkSVD算法虽然思想很简单,但是在实际应用中效果非常好,这真是验证了大道至简。
2.5 BiasSVD算法用于推荐
在FunkSVD算法火爆之后,出现了很多FunkSVD的改进版算法。其中BiasSVD算是改进的比较成功的一种算法。BiasSVD假设评分系统包括三部分的偏置因素:一些和用户物品无关的评分因素,用户有一些和物品无关的评分因素,称为用户偏置项。而物品也有一些和用户无关的评分因素,称为物品偏置项。这其实很好理解。比如一个垃圾山寨货评分不可能高,自带这种烂属性的物品由于这个因素会直接导致用户评分低,与用户无关。
假设评分系统平均分为μ,第i个用户的用户偏置项为bi,而第j个物品的物品偏置项为bj,则加入了偏置项以后的优化目标函数J(p,q)是这样的
这个优化目标也可以采用梯度下降法求解。和FunkSVD不同的是,此时我们多了两个偏执项bi
bjbi,,pi,qj的迭代公式和FunkSVD类似,只是每一步的梯度导数稍有不同而已,这里就不给出了。而bi,bj一般可以初始设置为0向量,然后参与迭代。这里给出bi,bj的迭代方法
通过迭代我们最终可以得到P和Q,进而用于推荐。BiasSVD增加了一些额外因素的考虑,因此在某些场景会比FunkSVD表现好。
2.6 SVD++算法用于推荐
SVD++算法在BiasSVD算法上进一步做了增强,这里它增加考虑用户的隐式反馈。好吧,一个简单漂亮的FunkSVD硬是被越改越复杂。
对于某一个用户i,它提供了隐式反馈的物品集合定义为N(i), 这个用户对某个物品j对应的隐式反馈修正的评分值为cij, 那么该用户所有的评分修正值为∑s∈N(i)csj。一般我们将它表示为用qTjys形式,则加入了隐式反馈项以后的优化目标函数J(p,q)是这样的:
其中,引入|N(i)|−1/2是为了消除不同|N(i)|个数引起的差异。式子够长的,不过需要考虑用户的隐式反馈时,使用SVD++还是不错的选择。
2.7 推荐技术的未来
FunkSVD将矩阵分解用于推荐方法推到了新的高度,在实际应用中使用也是非常广泛。当然矩阵分解方法也在不停的进步,目前张量分解和分解机方法是矩阵分解推荐方法今后的一个趋势。
对于矩阵分解用于推荐方法本身来说,它容易编程实现,实现复杂度低,预测效果也好,同时还能保持扩展性。这些都是它宝贵的优点。当然,矩阵分解方法有时候解释性还是没有基于概率的逻辑回归之类的推荐算法好,不过这也不影响它的流形程度。小的推荐系统用矩阵分解应该是一个不错的选择。大型的话,则矩阵分解比起现在的深度学习的一些方法不占优势。
3 SVD用于图像压缩
从一张图片出发,让我们来看看奇异值代表什么意义。这张照片,像素为高度450*宽度333。

我们都知道,图片实际上对应着一个矩阵,矩阵的大小就是像素大小,比如这张图对应的矩阵阶数就是450*333,矩阵上每个元素的数值对应着像素值。我们记这个像素矩阵为 A
现在我们对矩阵 A 进行奇异值分解。
直观上,奇异值分解将矩阵分解成若干个秩一矩阵之和,用公式表示就是:
既然奇异值有从大到小排列的顺序,我们自然要问,如果只保留大的奇异值,舍去较小的奇异值,这样上式里的等式自然不再成立,那会得到怎样的矩阵——也就是图像?
只保留等式右边第一项,然后作图:

结果就是完全看不清是啥……我们试着多增加几项进来, A5=σ1u1vT1+...+σ5u5vT5 再作图:

隐约可以辨别这是短发伽椰子的脸……但还是很模糊,毕竟我们只取了5个奇异值而已。当我们取到上式等式右边前50项时:

我们得到和原图差别不大的图像。也就是说当从1不断增大时,不断的逼近。让我们回到公式
矩阵 A 表示一个450*333的矩阵,需要保存个元素的值。等式右边 u 和 v 分别是450*1和333*1的向量,每一项有 1+450+333=784 个元素。如果我们要存储很多高清的图片,而又受限于存储空间的限制,在尽可能保证图像可被识别的精度的前提下,我们可以保留奇异值较大的若干项,舍去奇异值较小的项即可。例如在上面的例子中,如果我们只保留奇异值分解的前50项,则需要存储的元素为 784×50=39200 ,和存储原始矩阵相比,存储量仅为后者的26%。
因此:奇异值往往对应着矩阵中隐含的重要信息,且重要性和奇异值大小正相关。每个矩阵都可以表示为一系列秩为1的“小矩阵”之和,而奇异值则衡量了这些“小矩阵”对于的权重。
在图像处理领域,奇异值不仅可以应用在数据压缩上,还可以对图像去噪。如果一副图像包含噪声,我们有理由相信那些较小的奇异值就是由于噪声引起的。当我们强行令这些较小的奇异值为0时,就可以去除图片中的噪声。如下是一张25*15的图像

但往往我们只能得到如下带有噪声的图像(和无噪声图像相比,下图的部分白格子中带有灰色):

通过奇异值分解,我们发现矩阵的奇异值从大到小分别为:14.15,4.67,3.00,0.21,……,0.05。除了前3个奇异值较大以外,其余奇异值相比之下都很小。强行令这些小奇异值为0,然后只用前3个奇异值构造新的矩阵,得到

可以明显看出噪声减少了(白格子上灰白相间的图案减少了)。
5 SVD小结
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。SVD的原理不难,只要有基本的线性代数知识就可以理解,实现也很简单因此值得仔细的研究。当然,SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用
6 参考文献
主要参考资料:
1,知乎
https://www.zhihu.com/question/22237507
2,刘建平
3,维基百科
4,《机器学习实战》
5,《机器学习算法原理与编程实践》
welcome!
[email protected]
http://blog.csdn.net/github_36326955

Welcome to my blog column: Dive into ML/DL!
I devote myself to dive into typical algorithms on machine learning and deep learning, especially the application in the area of computational personality.
My research interests include computational personality, user portrait, online social network, computational society, and ML/DL. In fact you can find the internal connection between these concepts:
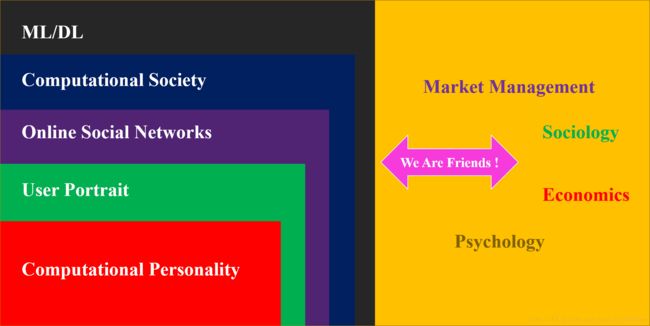
In this blog column, I will introduce some typical algorithms about machine learning and deep learning used in OSNs(Online Social Networks), which means we will include NLP, networks community, information diffusion,and individual recommendation system. Apparently, our ultimate target is to dive into user portrait , especially the issues on your personality analysis.
All essays are created by myself, and copyright will be reserved by me. You can use them for non-commercical intention and if you are so kind to donate me, you can scan the QR code below. All donation will be used to the library of charity for children in Lhasa.
手机扫一扫,即可:

附:《春天里,我们的拉萨儿童图书馆,需要大家的帮助》