Kettle快速入门
Kettle作为ETL工具,用于数据的抽取、转换、加载,为数据的整理提供数据采集、 转换、导入、导出等功能。
Kettle中两种脚本
-
transformation——完成针对数据的基本转换
-
job——完成整个工作流的控制
Kettle中的组件
-
spoon——图形用户界面,用于运行kettle中的脚本transformation和job。
-
pan——数据转换引擎,运行transformation工具,主要用于执行数据源读取、操作和写入。
-
kitchen——运行job任务的工具,利用XML或数据源库来描述。
kettle中连接和事务
-
每一个作业项或每一个连接的步骤操作都打开和关闭一个独立的数据库连接。
-
解决打开多个连接的问题,可在连接对话框的选项中,选择【转换放在数据库事务中】,可是所有步骤的数据库连接都使用同一个数据库过程。
Kettle——连接组件
-
multiway merge joi
Multiway Merge Join 用于多张表的联合查询。
-
排序合并
(1) 排序合并的多个输入流,其字段需要完全一致,不能多也不能少;
(2) 排序合并的结果是合并所有结果,不去重。
-
合并记录
合并记录的标志字段:
identical——表示新、旧数据一样,没有发生变化;changed——表示数据发生了变化;
new——表示新数据中有,旧数据中没有;deleted——表示旧数据中有,新数据中没有;
注意事项:
(1)关键字段:用于定位新旧数据源中的同一条记录;
(2)数据字段:用于指定需要比较的字段;
(3)旧数据和新数据拥有相同的字段;
(4)合并前,需要将新、旧数据按照关键字排序;
(5)若新数据发送了变化,合并后新数据会替换旧数据。
Kettle——转换
-
增加常量
增加常量,相当于在现有的输入流中,增加一列,列的value值自定义;增加常量后,每条记录的该常量列的值都相同。
-
排序记录
指定记录的某个字段安装指定的排序规则进行排序。
-
去除重复记录
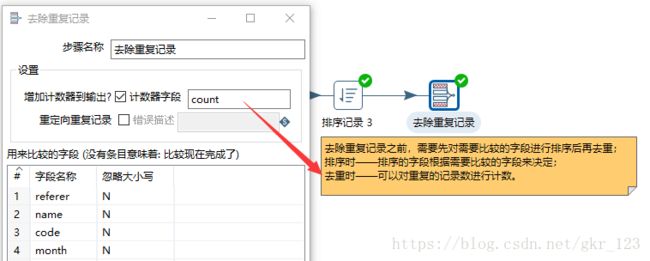
-
值映射
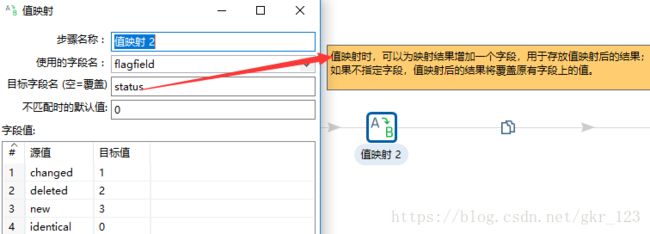
-
拆分字段
(1)拆分字段是指:将指定列的值,按照指定的拆分规则进行拆分;
(2)需要自定义列名来接收拆分后的字段值,拆成几部分就需指定多少列。
-
数值范围
输入字段——用于判断和比较的字段;输出字段——用于输出输入字段判断、比较的结果;缺省值——相当于默认值。
Kettle——流程
-
switch/case
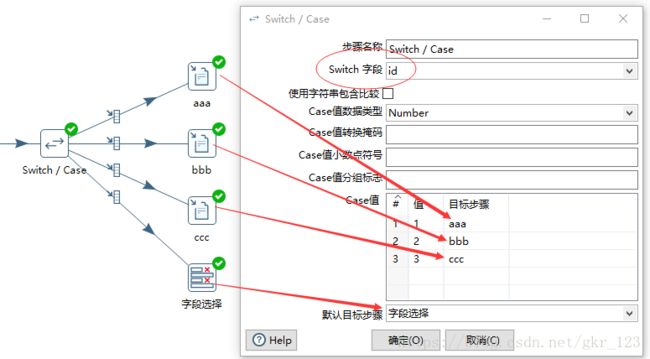
Kettle——数据清洗与校验
- 清洗——模糊匹配
(1)模糊匹配,通过计算器比较两个数据流中的两个字段的相似度。
(2)算法:
| 算法名称 | 算法作用 |
|---|---|
| Jaro和Jaro-winkler | 计算两个字符串的相似度,结果在0-1之间 |
| levenshtein和Damerau-Levenshtein | 编辑一个字符串到另一个字符串需要多少步,返回结果为步骤数 |
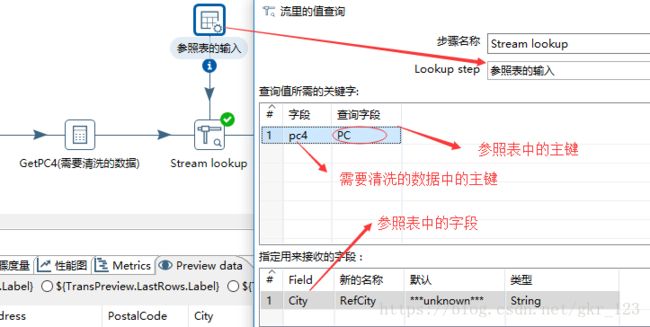
- 清洗——流里的值查询
(1)作用:对比参照表和需要清洗的数据,即将参照表和需要清洗的数据进行关联查询
(2)属性
| 属性名 | 属性说明 |
|---|---|
| lookup step | 指定参照表的输入步骤 |
| 查询值所需的关键字——字段、查询字段 | 需要清洗的数据中的关键字、参照表中的关键字 |
| 接收的字段 | 参照表中的字段值。注意:需要设置默认值。 |
- 数据校验
(1)注意:强烈推荐指定不满足条件的数据的流行;校验日期时,必须设置转换掩码(日期格式);
(1)数据校验的特点
| 可以给一个列设置多个约束 |
| 可以校验数据类型 |
| 错误合并 |
| 约束条件参数化 |
| 可以 |
Kettle——数据排重
- 去除完全重复的数据
(1)unique rows——去除重复数据:去重前,需要对数据先进行排序处理。
(2)unique rows——唯一行(Hash):可以在内存中进行操作。
- 不完成重复的数据
设计排除重复记录的转换:
(1)获取输入字段;
(2)使用模糊匹配算法,擦还行另一个数据流中 的一个字段;
(3)返回匹配结果。
Kettle——脚本
- 公式
(1)注意事项
| 步骤本身定义的字段不能参与运算; |
| 公式步骤里的字段需要手工输入; |
- java脚本

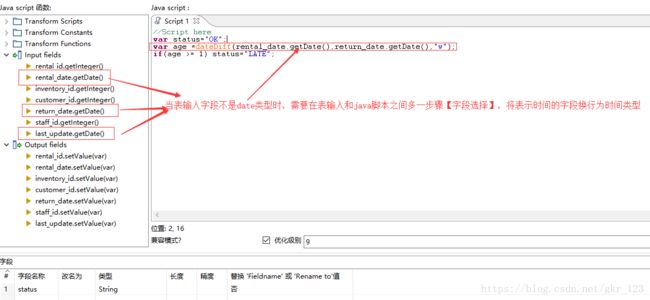
- 正则表达式

注意事项:
(1)为了能在正在表达式中使用空格和注释,需要在【内容】标签下选中“在表达式中允许有空格和注释”;
(2)为了能把捕获组保存到输出字段里,需要在【设置】标签下选中“为每个匹配组创建一个字段”选项;
(3)一个捕获组就是圆括号中的正在表达式。
Kettle——统计、应用
-
分组
(1)使用分组前,需要对输入流进行排序;排序的字段为构成分组的字段;
(2)【包括所有的行】:用于指定分组后是否输出输入流中的所有字段;
(3)【构成分组的字段】:用于指定按哪些字段进行分组;
(4)【聚合-名称】:指定一个保存分组计算结果的字段名称;
(5)【聚合-Subject】:指定哪个字段用于分组计算;
(6)【聚合-类型】:指定分组计算的方法,比如求和等。
-
设置为NULL
将指定字段(名称——指定字段名称)的指定值(需要替换为NULL的值)替换为NULL值。
-
替换NULL值
将NULL值得地方,按照指定的方式(根据字段 或 根据值类型),替换成指定的值。