Ubuntu 18.04 安装显卡驱动+CUDA10+多版本CUDA+Tensorflow gpu1.13.1
废话不多说,直奔主题!
一.安装驱动
1.去官网下载驱动,这个根据自己的显卡去搜索,比如我的卡是RTX2070:

然后点击“搜索”按钮,出现界面:

这里提示对应的驱动版本,点击下载就好了,下载的是一个xxx.run文件,我的是:NVIDIA-Linux-x86_64-418.56.run 。
2.删除之前的驱动,不管有没有装过,执行一次下面命令就好:
sudo apt-get remove --purge nvidia*
3.禁用nouveau,执行命令:
sudo vim /etc/modprobe.d/blacklist.conf
打开后,在文本最后添加开源驱动,添加以下内容:
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
退出并保存
4.继续执行命令禁用内核:
echo options nouveau modeset=0
sudo update-initramfs -u
5.重启,并执行下面命令:
lsmod | grep nouveau
如果没有任何信息输出,则说明禁用成功!
6.ctr+alt+f3(f3-f6都可能,这个根据机器而定,自己可以试下自己的机器.另外,也有可能是alt+f3-f6) 进入文本编辑界面,然后执行下面的命令:
sudo systemctl set-default multi-user.target
sudo chmod u+x NVIDIA-Linux-x86_64-418.56.run
sudo ./NVIDIA-Linux-x86_64-418.56.run –no-opengl-files
第一个是关闭图形界面命令,第二个是添加权限,第三个是安装。
执行上面命令后会弹出一个蓝色的界面,这时候选择“Continue installation” ,然后回车,这样接下来会再连续弹出两次选择,这两次选择操作均选择“no”项即可(忘记截图了…). 最后会弹出一个说明界面,意思是安装成功了,直接回车就好了(只有一个“ok”)选项。
7.开启用户图形界面并重启:
sudo systemctl set-default graphical.target
sudo reboot
8.重启并检查否安装成功:
nvidia-smi
成功的话会显示:
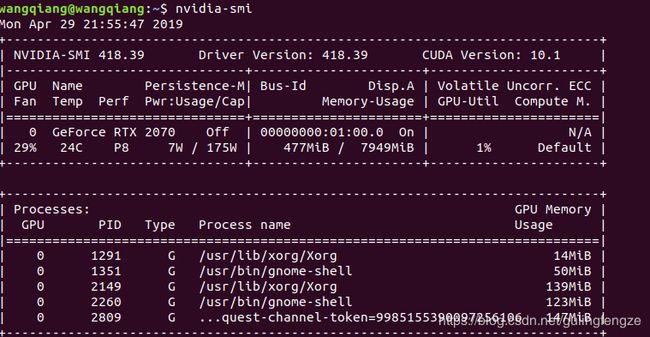
这样就说明驱动安装成功了,接下来就是安装cuda和cudnn了。
二.安装CUDA和cuDNN
1.官网下载CUDA和cuDNN
CUDA

我选择安装的是“CUDA Tookit 10.1 [Feb 2019],Versioned Onlie Documentation”
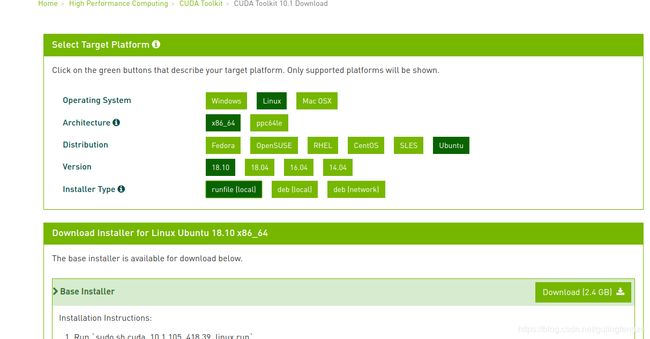
点击下载即可。
cuDNN
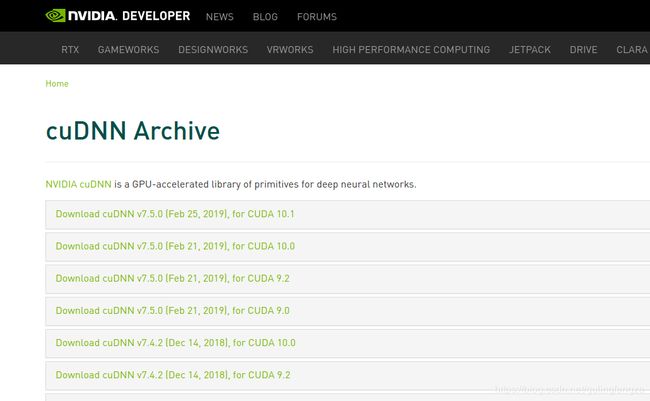
我选择安装的是“Download cuDNN v7.5.0 [Feb 25,2019],for CUDA 10.1”,下载的cuDNN一定要和CUDA版本对应!
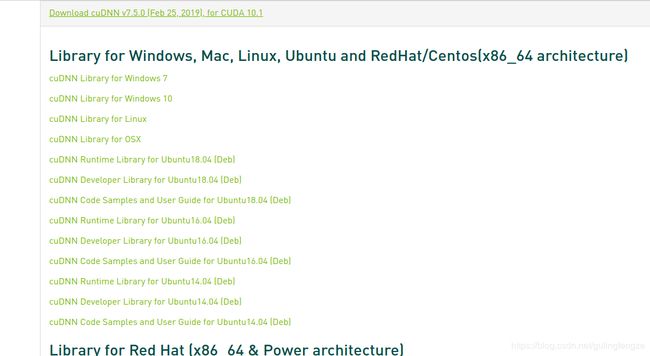
这里选择cuDNN Library for Linux,不是cuDNN Runtime Library for Ubuntu18.04 (Deb) 或cuDNN Developer Library for Ubuntu18.04 (Deb) 等,别搞错了!
cuDNN下载后解压即可。
2.开始安装
ctr+alt+f3(f3-f6都可能,这个根据机器而定,自己可以试下自己的机器) 进入文本编辑界面,然后执行下面的命令:
sudo systemctl set-default multi-user.target
sudo sh cuda_10.1.105_418.39_linux.run
稍等会弹出选择信息,然后 按ctr + c ,根据提示输入accept,回车后会再弹出选择项(中间会问是否安装显卡驱动,这个一定要选择输入n!!),之后的就按照提示选择就好了,这个安装可能需要一些时间,耐心等待即可。
最后会弹出诸如下信息:
Driver:Installed
Toolkit:Installed in /usr/local/cuda-10.1
Samples:Installed in /home/wangqiang
Please make sure that........
这样说明已经安装好了。
3.开启用户图形界面并重启:
sudo systemctl set-default graphical.target
sudo reboot
4.添加环境变量:
vim ~/.bashrc
添加下面内容:
export CUDA_HOME=/usr/local-10.1/cuda
export PATH=$PATH :$CUDA_HOME/bin
export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
保存退出,再执行命令:source ~/.bashrc
5.配置cuDNN
解压出来是一个名为cuda的文件夹,接下来执行下面命令:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
如果上面没有出现安装异常,那到这里可以说cuda和cudnn都已经安装完毕。查看cuda版本和cudnn版本信息:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2

cat /usr/local/cuda/version.txt 或者nvcc --version

实际这里应该输出的是release 10.1 的信息,只是后来我切换到了10.0而已。
好了,如果运气不差的话到这里就算把所有环境配置好了。
三.多版本CUDA并存
开始我安装的CUDA版本是10.1的,之后又安装了CUDA 10.0版本,那就参考CUDA 10.0的安装为例说明多版本CUDA并存的方法吧。
首先还是到官网下载对应的CUDA版本以及cuDNN版本,在/home/wangqiang路径下创建一个文件夹:NVIDIA_CUDA-10.0_Samples,这个其实可以创建在任何地方,用户存放cuda的例子.
更改CUDA的权限: sudo sh cuda_10.0.130_410.48_linux.run (我下载的cuda10.0)
接下来是安装过程如要指定的内容:
输入“accept”,接下来问是否安装显卡驱动,这里一定要输入“no”,再接着问是否安装CUDA10.0 Toolkit,输入“yes”,接着问是否链接到/usr/local/cuda,输入“no”,接着问安装CUDA10.0 Samples,输入“yes”,之后将刚才创建的NVIDIA_CUDA-10.0_Samples路径输入到[ default is /home/wangqiang ]: 后面即可,这样就可以成功安装了。
这里放个截图参考:
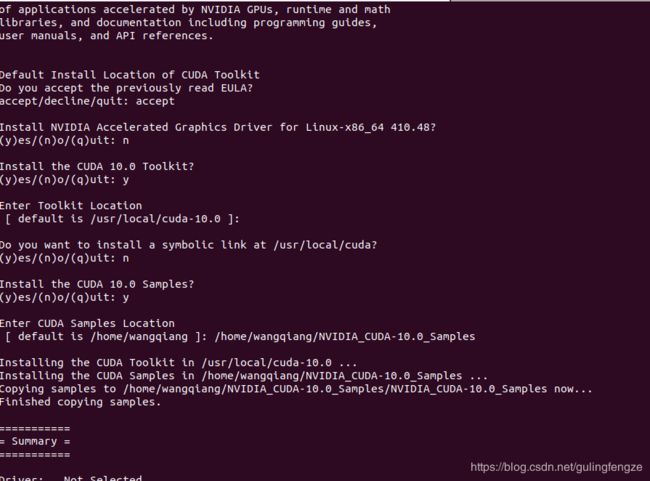
接下来修改环境变量:
vim ~/.bashrc
为了方便以后CUDA版本切换,将上面配置的CUDA环境信息注释掉,然后添加以下内容:
export PATH="/usr/local/cuda/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"
export LIBRARY_PATH="/usr/local/cuda/lib64:$LIBRARY_PATH"
类似这样:

保存退出,并更新环境变量:source ~/.bashrc
切换CUDA版本也比较简单,我这里是将CUDA10.1切换到CUDA10.0,创建软链接,执行命令:
sudo rm -rf /usr/local/cuda
sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda
可以通过命令测试一下:nvcc --version
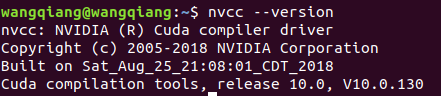
这里就切换到CUDA10.0版本了,对于其它版本也是这种做法。另外,记得安装对应版本的cuDNN,做法和上面一样.
附:可以到/usr/local路径下通过命令:stat cuda 查看当前CUDA软链接指向的CUDA版本:
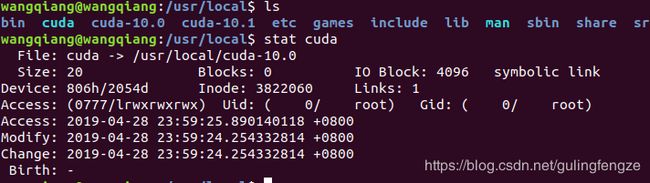
可以看到我的机器CUDA软链接指向的是10.0版本。
三.安装Tensorflow gpu 1.13.1 版本
Tensoflow gpu 1.13.1版本要求CUDA版本必须是10以上,可以参考官方提供的Tensorflow与CUDA版本对应关系 了解一下。
安装:
pip install tensorflow-gpu==1.13.1
附:如果需要用TF的object detection API的话,在models/research/object_detection/legacy执行train.py进行网络训练或在models/research/object_detection执行model_main.py进行网络训练时,出现错误:
2019-05-08 23:08:11.781338: I tensorflow/stream_executor/dso_loader.cc:152] successfully opened CUDA library libcublas.so.10.0 locally
2019-05-08 23:08:12.916602: E tensorflow/stream_executor/cuda/cuda_dnn.cc:334] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
2019-05-08 23:08:12.933511: E tensorflow/stream_executor/cuda/cuda_dnn.cc:334] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
INFO:tensorflow:Error reported to Coordinator: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
解决办法:
看似是cuDNN问题,但貌似不是。网上查了一些可能的解决办法,其中有说是因为GPU内存使用的问题,自己尝试了一下,可以解决我的问题。
方法1:
在 models/research/object_detection/legacy/trainer.py 中添加会话执行时分配的gpu大小,参照下图添加代码即可

也就是添加代码:
session_config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 这里自行指定
或者
session_config.gpu_options.allow_growth = True
方法2:
修改源码,打开文件anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py ,找到类:class BaseSession(SessionInterface) ,修改如下:
class BaseSession(SessionInterface):
def __init__(self, target='', graph=None, config=None):
...
if config is not None:
if not isinstance(config, config_pb2.ConfigProto):
raise TypeError('config must be a tf.ConfigProto, but got %s' % type(config))
# 会话执行时GPU分配 <----添加
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
config.gpu_options.allow_growth = True
self._config = config
self._add_shapes = config.graph_options.infer_shapes
else:
# 会话执行时GPU分配 <----添加
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
config.gpu_options.allow_growth = True
#self._config = None
#self._add_shapes = False
# 修改为:
self._config = config
self._add_shapes = config.graph_options.infer_shapes
...
另外,别忘记导入tensorflow : import tensorflow as tf
上面这两种解决办法顺便解决了TF在训练时占用整个GPU的问题~~~
以上就是这篇博客的所有内容,希望能够帮助到各位,谢谢!
补充:
在使用过程中,有时候突然提示显卡连接不上的问题,也就是说显卡驱动掉了!
网上很多方法都有试过,但只有一种可行的办法,就是重新安装驱动!
- 安装驱动
首先还是要执行删除驱动命令:
sudo apt-get remove --purge nvidia*
- 进行安装
这个还是和上面说的安装方法一样,先进入编辑模式。这里多说一下,之前我的电脑ctrl + alt + f3 就可进入编辑模式,之后就不行了,试了alt + f3也不行,f1-f6都尝试遍了,还是不行!没办法,网上找解决办法:ubuntu16.04桌面版开机进入命令行模式
基本流程就是:开机,然后选择到第一项(*Ubuntu)处,不要按回车,需要按键盘上的“e”键,然后参照链接上的方法在指定位置输入数字 3 ,最后按ctrl+x键就可以了。理论上这样就可以进入到编辑模式了!
但是我的电脑比较坑,ctrl+x后并没有顺利进入到编辑模式,而是卡在一条未知log信息处不动了!!!
最后尝试着按alt+f3 键,然后才显示输入账户和密码的界面。。。
上面就是自己遇到的一些小坑,那下面说下安装,这个和上面的方法一样,基本就是几个命令完成,当然安装过程中的选择还是参考上面的内容即可,命令如下:
sudo systemctl set-default multi-user.target
sudo chmod u+x NVIDIA-Linux-x86_64-418.56.run
sudo ./NVIDIA-Linux-x86_64-418.56.run –no-opengl-files
sudo systemctl set-default graphical.target
sudo reboot
重启后耐心等待一下,时间可能有点长…
最后命令nvidia-smi检查下安装是否成功即可。
再补充:
关机后重启发现显卡驱动又没了!!! 查了不少资料,尝试了各种解决办法都不行,想想单位用的显卡驱动版本,尝试换了个相同版本的显卡驱动,最后这个问题就没出现过,应该是显卡驱动呵我电脑的硬件不兼容导致的。我自己的电脑换的显卡版本是:NVIDIA-Linux-x86_64-410.78.run ,太新的显卡驱动还不行.