ElasticSearch教程——创建索引、类型、文档
ElasticSearch汇总请查看:ElasticSearch教程——汇总篇
介绍
- 索引是ElasticSearch存放数据的地方,可以理解为关系型数据库中的一个数据库。事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。然而,这只是一些内部细节——我们的程序完全不用关心分片。对于我们的程序而言,文档存储在索引(index)中。剩下的细节由Elasticsearch关心既可。(索引的名字必须是全部小写,不能以下划线开头,不能包含逗号)
- 类型用于区分同一个索引下不同的数据类型,相当于关系型数据库中的表。在Elasticsearch中,我们使用相同类型(type)的文档表示相同的“事物”,因为他们的数据结构也是相同的。每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所有类型下的文档被存储在同一个索引下,但是类型的映射(mapping)会告诉Elasticsearch不同的文档如何被索引。
- 文档是ElasticSearch中存储的实体,类比关系型数据库,每个文档相当于数据库表中的一行数据。 在Elasticsearch中,文档(document)这个术语有着特殊含义。它特指最顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID标识并存储于Elasticsearch中)。
- 文档由字段组成,相当于关系数据库中列的属性,不同的是ES的不同文档可以具有不同的字段集合。
对比关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields文档元数据
一个文档不只有数据。它还包含了元数据(metadata)——关于文档的信息。三个必须的元数据节点是:
| 节点 | 说明 |
|---|---|
_index |
文档存储的地方 |
_type |
文档代表的对象的类 |
_id |
文档的唯一标识 |
_index:索引
_type:类型
_id:id仅仅是一个字符串,它与_index和_type组合时,就可以在Elasticsearch中唯一标识一个文档。当创建一个文档,你可以自定义_id,也可以让Elasticsearch帮你自动生成。
索引创建原则
- 类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。如果你把比如product,sales,human resource(employee),全都放在一个大的index里面,比如说company index,不合适的。
- index中包含了很多类似的document:类似是什么意思,其实指的就是说,这些document的fields很大一部分是相同的,你说你放了3个document,每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。
- 索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
创建索引、类型、文档(接口的方式)
以kibana的方式操作ES的可以查看ElasticSearch教程——Kibana简单操作ES
以博客内容管理为例,索引名为blog,类型为article,自定义id是“1”,新加一个文档:
curl -H 'Content-Type:application/json' -XPUT http://localhost:9200/blog/article/1 -d '
{
"id": "1",
"title": "New version of Elasticsearch released!",
"content": "Version 1.0 released today!",
"priority": 10,
"tags": ["announce", "elasticsearch", "release"]
}'自增ID
当我们想要一个自增ID的时候,直接不用设置id即可,即原来是把文档存储到某个ID对应的空间,现在是把这个文档添加到某个_type下(注意:这边是POST不是PUT)
curl -H 'Content-Type:application/json' -XPOST http://localhost:9200/blog/article/ -d '
{
"title": "New version of Elasticsearch released!",
"content": "Version 1.0 released today!",
"priority": 10,
"tags": ["announce", "elasticsearch", "release"]
}'返回结果:
{
"_index": "blog",
"_type": "article",
"_id": "eTmX5mUBtZGWutGW0TNs",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突。
检索文档
在对应的浏览器地址栏输入如下地址
http://XXX.XXX.XXX.XX:9200/blog/article/1?pretty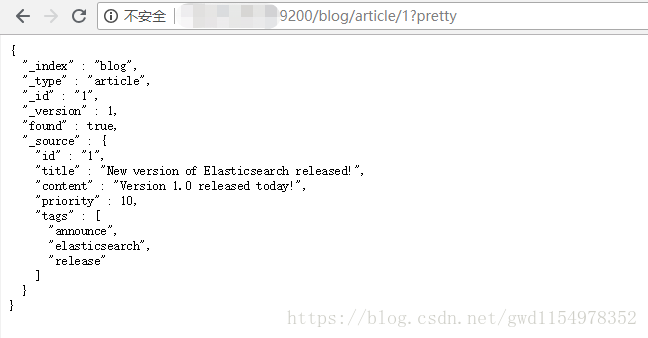
或者在Linux中使用如下脚本:
curl -H 'Content-Type:application/json' -XGET http://localhost:9200/blog/article/1?pretty
响应包含了现在熟悉的元数据节点,增加了_source字段,它包含了在创建索引时我们发送给Elasticsearch的原始文档。
pretty:在任意的查询字符串中增加pretty参数,类似于上面的例子。会让Elasticsearch美化输出(pretty-print)JSON响应以便更加容易阅读。
_source字段不会被美化,它的样子与我们输入的一致,现在只包含我们请求的字段,而且过滤了date字段。
或者你只想得到_source字段而不要其他的元数据,你可以这样请求:
curl -H 'Content-Type:application/json' -XGET http://localhost:9200/blog/article/1/_source返回结果:
{
"id": "1",
"title": "New version of Elasticsearch released!",
"content": "Version 1.0 released today!",
"priority": 10,
"tags": ["announce", "elasticsearch", "release"]
}
请求返回的响应内容包括{"found": true}。这意味着文档已经找到。如果我们请求一个不存在的文档,依旧会得到一个JSON,不过found值变成了false。此外,HTTP响应状态码也会变成'404 Not Found'代替'200 OK'。我们可以在curl后加-i参数得到响应头:
curl -H 'Content-Type:application/json' -i -XGET http://localhost:9200/blog/article/1?pretty显示结果:
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 337
{
"_index" : "blog",
"_type" : "article",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"id" : "1",
"title" : "New version of Elasticsearch released!",
"content" : "Version 1.0 released today!",
"priority" : 10,
"tags" : [
"announce",
"elasticsearch",
"release"
]
}
}
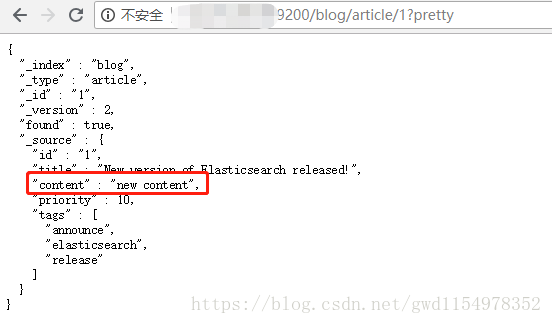
更新文档
curl -H 'Content-Type:application/json' -XPOST http://localhost:9200/blog/article/1/_update -d '{
"script": "ctx._source.content = \"new content\""
}'
删除文档
curl -XDELETE http://localhost:9200/blog/article/1 