(七)sklearn绘制验证曲线
1、绘制验证曲线
在此图中,随着内核参数gamma的变化,显示了SVM的训练分数和验证分数。
对于非常低的gamma值,可以看到训练分数和验证分数都很低。这被称为欠配合。
gamma的中值是两个分数的高值,即分类器表现相当好。如果gamma太高,则分类
器将过度拟合,这意味着训练分数良好但验证分数较差。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
digits = load_digits()
X, y = digits.data, digits.target
param_range = np.logspace(-6, -1, 5)
train_scores, test_scores = validation_curve(
SVC(), X, y, param_name="gamma", param_range=param_range,
cv=10, scoring="accuracy", n_jobs=1)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.title("Validation Curve with SVM")
plt.xlabel("$\gamma$")
plt.ylabel("Score")
plt.ylim(0.0, 1.1)
lw = 2
#半对数坐标函数:只有一个坐标轴是对数坐标,另一个是普通算术坐标
plt.semilogx(param_range, train_scores_mean, label="Training score",
color="darkorange", lw=lw)
#在区域内绘制函数包围的区域
plt.fill_between(param_range, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.2,
color="darkorange", lw=lw)
plt.semilogx(param_range, test_scores_mean, label="Cross-validation score",
color="navy", lw=lw)
plt.fill_between(param_range, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.2,
color="navy", lw=lw)
plt.legend(loc="best")
plt.show()
2、绘制学习曲线
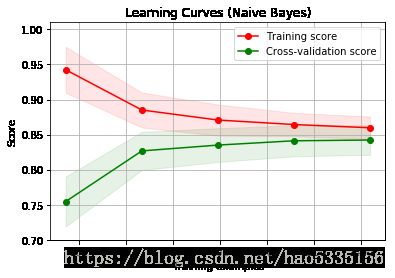
图中,显示了数字数据集的朴素贝叶斯分类器的学习曲线。曲线的形状可以经常在更复杂的数
据集中找到:训练分数在开始时非常高并且减少,并且交叉验证分数在开始时 非常低并且增加我们看到了带有RBF内核的SVM的学习曲线。我们可以清楚地看到训练分数仍然在最大值附近,并且可以通过更多训练样本来增加 验证分数。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
#ylim定义绘制的最小和最大y值
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
digits = load_digits()
X, y = digits.data, digits.target
title = "Learning Curves (Naive Bayes)"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = GaussianNB()
plot_learning_curve(estimator, title, X, y, ylim=(0.7, 1.01), cv=cv, n_jobs=4)
title = "Learning Curves (SVM, RBF kernel, $\gamma=0.001$)"
# SVC is more expensive so we do a lower number of CV iterations:
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
estimator = SVC(gamma=0.001)
plot_learning_curve(estimator, title, X, y, (0.7, 1.01), cv=cv, n_jobs=4)
plt.show()