MSRA副院长郭百宁:20+行代码就能写出微软颜龄机器人
近年来的计算机视觉(CV)无疑是深度学习的天下,微软亚洲研究院(MSRA)去年公布的152层残差网络(ResNet)更是大幅推动计算机视觉的进展。日前,微软亚洲研究院常务副院长郭百宁博士向CSDN记者介绍了微软亚洲研究院近期在计算机视觉领域的研究成果以及应用案例,包括面向开发人员的微软认知服务的计算机视觉API,可以只用20多行代码就写出微软颜龄机器人How-Old.net。
MSRA的CV研究
视觉计算组是1998年微软亚洲研究院建院时成立的第一个小组,那时候计算机视觉应用非常少,很冷门。计算机视觉发现到现在成为热门,两个因素的影响比较重大:
- 统计方法代替几何解析成为计算机视觉问题的解决办法,视觉跟踪和视觉分析的研究随后诞生,大型的图像和数据库的出现对计算机视觉起了很大作用。
- 基于深度学习的图像识别的出现,使得识别率逐年上涨,并促进了工业界的一些应用,比如车牌识别、游戏中动作的追踪、帮助医生检测疾病等等。
计算机视觉分为几个级别。一个是低级视觉,主要目的是抽取一些低级(基础)的特征,包括滤波、边缘检测、纹理抽取,然后提供给上层进行更好的应用。高级视觉则是拿到低级的信息之后,在这个上面来理解图像并做进一步的决定。还有一个就是中级视觉,就是分析图像,让决定做的更准确。
从长远考虑,微软十分重视计算机的基础研究,并且在每个重要领域都有研究。研究领域涵盖:
- 图像识别和检测
- 图像分类
- 人脸追踪
- 人脸检测、识别、属性识别
- 视频分析
- 视频检测
- 情绪识别
- 物体分割
- 图像编辑和计算摄影
- 图像搜索
早在微软亚洲研究院刚刚建院的时候我们就有这样一个原则:我们要做最好的研究。怎么定义最好的研究?就是在研究领域里最好的5%的会议当中要有5%的论文是从微软亚洲研究院出来的。现在已经远远超出5%了。
MSRA的CV进展
从ImageNet说起,郭百宁介绍了微软亚洲研究院计算机视觉组最新的研究进展,包括残差学习、物体识别、视频中的物体分割、视频人脸识别和图像去雾等。
深层残差网络
在ImageNet 2015的比赛中,微软亚洲研究院视觉计算组的研究员们凭借深层神经网络技术的最新突破,以绝对优势获得图像分类、图像定位以及图像检测全部三个主要项目的冠军。其中的独门秘诀就叫深层残差网络(Deep Residual Networks)。【参考文章:刷新神经网络新深度:ImageNet计算机视觉挑战赛微软中国研究员夺冠】
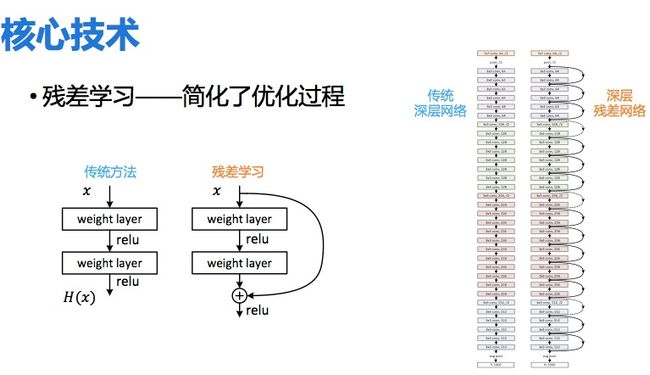
2012年多伦多大学的研究者有一个新突破——Alexnet,神经网络做到8层。这批人以前是做机器学习的。之前做神经网络也就做到一两层,一般都是两三层,做深了会不稳定,就算不出结果了。2014年剑桥大学的研究者把深度升级到19层。为什么基于残差学习的神经网络ResNet能够那么好的成果?它能达到152层,而且还可以做的更深。
残差学习的想法是这样的:数据放进去后,计算机要学习一个函数,再在函数里面加一个值的变化。现在不要直接学习函数,而是有一个粗略的值,这个粗略的值可能不是最精确,但是学习的是它和真的函数之间的残差。残差学习最重要的突破在于重构了学习的过程,并重新定向了深层神经网络中的信息流。
物体检测与视频物体分割
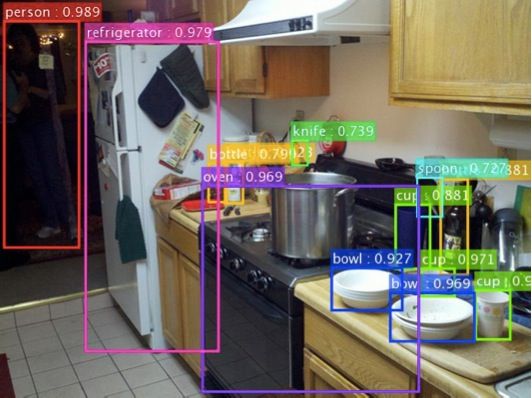
在图像识别中,比图片分类更加难的一件事情就是物体的检测。物体检测:有什么东西?东西在哪?在哪就要找一个框框出来,且这些框是可以重叠的。这就是人类以前做计算机视觉时候的一个梦想——拿到一张图可以辨认里面有什么东西。这里面的数字表示的是概率,机器现在并不能说100%就是某个物体,只能说看上去概率很高的基本上就是了,这是行业里面的一个惯例。
比图像识别和物体检测还要更进一层的就是物体分割,不但框住,还把它真真切切的边界找出来。拿一张图像识别这里面有没有某个人,在图像级别我就说有或者没有,这是第一个级别。另外一个级别更细一些,除了要回答这里面有没有这个人,还要框出来。到了物体分割这个级别,就是像素级了,除了要回答这里面有没有人,还要标出来哪一个像素是这个人的像素,哪一个像素是背景的。这是三个级别,任务越来越难。
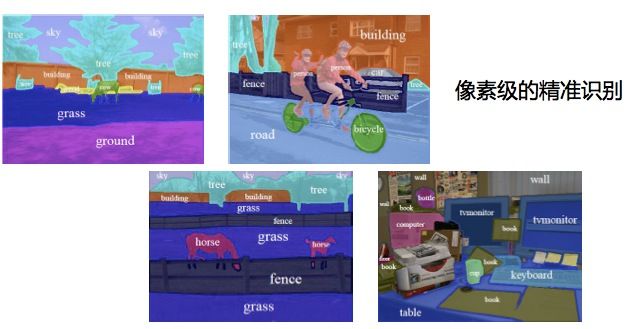
可以看到今天像素级的精准识别做到了一种的程度,每一个像素都可以很精确地识别它是属于哪一个物体的。
视频人脸识别
ImageNet是非常大的竞赛,在视频人脸识别的测试集上,微软在近期三个视频人脸标准测试集上都排名第一,且都有很大的优势。
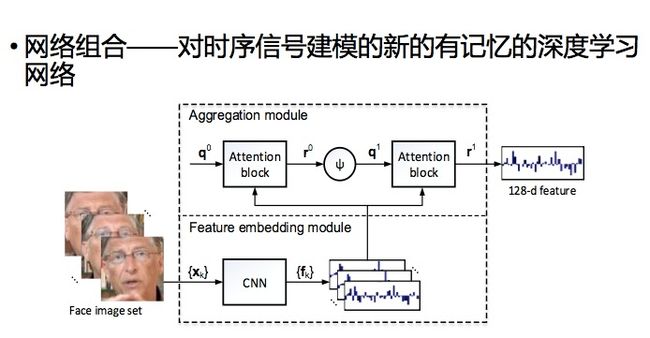
和传统人脸识别的不同, 视频人脸识别的输入是视频而不是单张的图像。传统方法需要算法将第一个视频中每一个人脸和第二个视频中的每一个人脸一对一的做一个比较,然后取所有相似度的平均值作为两个视频人脸的相似度。而微软方法的不同在于针对不同长度的人脸视频,会产生一个固定长度的特征表示,然后可以直接比较这两个特征表示,这两个特征相当于两组人的DNA,DNA如果对上,就是同样的人。这样不仅可以节省计算,也可以节省存储空间。
微软采用的方法是一个对时序信号建模的新的有记忆的深度学习网络叫做组合网络,可以做端到端的学习。Residue Network解决的是单张图片的识别问题,组合网络解决的是视频输入的识别问题。
图像去雾
图像的去雾技术可以还原图像的颜色和能见度,同时也能利用雾的浓度来估计物体的距离,这些在计算机视觉上都有重要应用(例如三维重建,物体识别)。
在无雾图像中,每一个局部区域都很有可能会有阴影,或者是纯颜色的,又或者是黑色的。因此,每一个局部区域都很有可能有至少一个颜色通道会有很低的值。微软把这个统计规律叫做Dark Channel Prior(暗原色先验)。直观来说,Dark Channel Prior认为每一个局部区域都总有一些很暗的东西。这个规律很简单,但在微软研究的去雾问题上却是本质的基本规律。由于雾总是灰白色的,因此一旦图像受到雾的影响,那么这些本来应该很暗的东西就会变得灰白。不仅如此,根据物理上雾的形成公式,还能根据这些东西的灰白程度来判断雾的浓度。因此,微软提出的Dark Channel Prior能很有效地去除雾的影响,同时利用物的浓度来估算物体的距离。
MSRA研究成果的应用
微软自拍
微软自拍是一款面向终端用户的应用,主要是通过计算机视觉技术实现把照片拍得更漂亮更自然、智能降噪以及合理地进行曝光调整三项功能。
自然美颜:首先,系统要对照片进行JDA人脸检测,检测出这张图片是否存在人脸,一共有多少张人脸,以及人脸出现在图片的什么地方。随后,系统利用特征点检测技术分析每一张人脸的不同五官需要什么程度的美化。微软自拍采用的是微软亚洲研究院在2014年CVPR大会上发表的论文中提出的68个人脸特征点检测方法。借用该方法,系统能够快速准确地检测出脸型和特征点。接下来,基于高层的智能方式,算法会对图片中的人脸进行信息提取,包括年龄和性别的判别。最后,该应用采用的“数字化洁面”算法会基于已经提取的面部信息对人脸进行美化处理。
智能降噪:智能降噪功能的关键技术包括快速帧间对齐和多帧降噪技术。单张照片上的噪点是围绕平均值进行上下波动的,而如果把两张有噪点的图片进行叠加的话,就可以得出一张更为干净的图片。图片数量增多,照片中的噪点也会逐步下降。但针对拍照过程中的手抖现象,如果只是简单地把连拍的多张照片进行平均叠加的话,则会产生重影的效果。因此,研究员对帧和帧之间采用了相机模型估计的方法,不通过传感器而是完全通过数字化的帧间对齐方法进行处理。其次,当帧和帧对齐之后,因为场景中深度有所不同,一个微小的运动都会导致同一个像素点在不同帧对应的物体不一样,所以如果只是简单地做图片平均的话,还是有可能导致图片重影。所以,研究员采用的算法会甄别选取一致的像素点拿来做平均,这个平均不仅是发生在时间域上也会发生在空间域上,从而让该降噪算法对于无论是人脸照片还是非人脸照片都有着非常理想的效果。
增强曝光:微软自拍会自动对画幅中各区域进行曝光分析和调整。首先系统会自动检测背光情况,并对各区域提供最佳的局部曝光补偿,避免整体图片调整而导致图片过度曝光,并保证照片在能够看清逆光景物的同时保持照片的层次感。而针对风景照常见的薄雾情况,研究员还开发了去雾算法。该算法能与曝光校正算法融合增强照片的清晰度,从而达到使用紫外线滤镜(UV)或圆偏振镜(CPL)的专业级照片效果。
人脸识别
视觉算法对光的敏感度很高,会受到光强弱的影响。红外线的光就很稳定,不受这些光的影响。于是微软通过大量的实验推出了Windows Hello,它与password有一致的安全率。因为它的错误率低于10万分之一。它连双胞胎都可以分辨出来。当然它还有反干扰的功能,用照片和视频来伪装成电脑主人是无法通过的。为了反干扰的算法,微软甚至请了著名的黑客,不过几个星期也没有攻进去。
OneDrive图片识别
该功能会自动为用户上传的照片创建标签,比如人、狗、沙滩、落日等等,使用户借助标签能够更轻松地寻找到自己想要的图片。输入关键词或标签,就能搜索出心仪照片。
这个技术是利用微软亚洲研究院实现的一种称为“空间金字塔聚合”(Spatial Pyramid Pooling,SPP)的新算法——通过内部特征识别,而不是每个区域从头检测,对整个图片只做一次计算,在不损失准确度的前提下,物体检测速度有了上百倍的提升。
微软小冰
微软小冰也有很多图像识别功能。最有名的是小冰识狗,它可以把狗认出来,还可以和明星挂上钩。它能够识书,你要买什么书,让小冰看,它就可以认出来,告诉你哪里可以买到,而且告诉你书里面的信息。另外,小冰还可以通过人脸识别技术猜测人与人之间的关系,或者对人的性格做一些分析。你还能发照片给小冰对其进行一个颜值打分。
计算机视觉API
在Build 2016微软开发者大会上,微软发布了微软认知服务(Microsoft Cognitive Services),集合了视觉、语音、语言、知识和搜索五大类共二十一项API(后续会增加),让没有人工智能的知识背景也能轻松开发出属于自己的智能应用。
图像API
视觉类里面有计算机视觉API、情感识别API、人脸识别API和视频检测API,图片方面可以识别图像、估计年龄、识别男女、识别是不是有成人的内容,包括具体的位置等信息和程序员关心的一些数字。有了这些API之后就开发者不需要自己再花很多时间去开发这个技术了,直接用几行Code就可以调用,并生成APP。
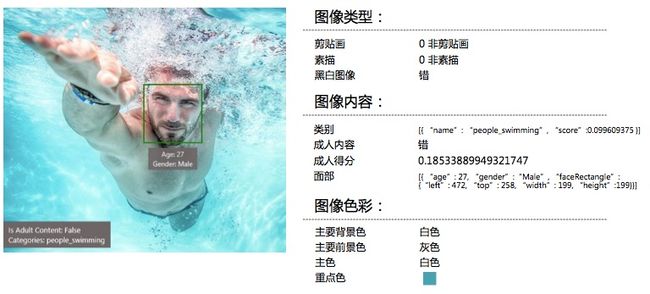
郭百宁举了一个How-Old.net(微软颜龄机器人)的例子:这款应用只要用20几行代码去调用微软认知服务中的API,就可以写出来。
static async void MakeRequest()
{
var client = new HttpClient();
var queryString = HttpUtility.ParseQueryString(string.Empty);
// Specify values for optional parameters, as needed
// queryString["analyzesFaceLandmarks"] = "false";
// queryString["analyzesAge"] = "false";
// queryString["analyzesGender"] = "false";
// queryString["analyzesHeadPose"] = "false";
// Specify your subscription key
queryString["subscription-key"] = "";
// Specify values for path parameters (shown as {...})
var uri = "https://api.projectoxford.ai/face/v0/detections?" + queryString;
HttpResponseMessage response;
// Specify request body
byte[] byteData = Encoding.UTF8.GetBytes("");
using (var content = new ByteArrayContent(byteData))
{
response = await client.PostAsync(uri, content);
}
if (response.Content != null)
{
var responseString = await response.Content.ReadAsStringAsync();
Console.WriteLine(responseString);
}
}视频API
目前开放的视频API能够自动实时的对视频进行分析和编辑,其中包括稳定处理、人脸检测及追踪和运动检测这三大功能。
稳定处理:稳定处理技术主要解决的是视频拍摄过程中出现的抖动、不平稳的问题,如手持摄影等第一人称视角视频中常见而不可避免的抖动问题等等。用户上传了原本剧烈抖动的视频之后,通过云端对视频进行快速编辑,几乎能实时生成一个更加平稳、流畅与清晰的视频。
人脸检测及追踪:这项技术能对视频文件中出现的多个人脸进行持续检测与追踪,并对不同人脸进行信息甄别,以区分不同的人脸。例如亲友聚会的派对视频、安防摄像头拍到的视频等都可以应用于此,找出某一个到多个特定的人脸在视频中的持续动态。
运动检测:简单的来说,这项功能可以检测出视频画面中有无运动行为等变化。随着各种智能摄像头的大量普及,这项技术在区域安全监控领域有很大的应用。例如,在家庭中,为了让儿童远离厨房等危险区域,可以利用该功能对某一区域进行运动检测,如果检测到有人或物体(儿童)进入该区域,会及时得到警报提醒。再比如,对门窗区域进行运动检测,如果有开门翻窗等动静,用户也能得到及时提醒。
郭百宁认为,计算机视觉未来一定有更多的应用,包括机器人领域、安防和监控、文化遗产保护(将一些文物古迹进行数字化,微软已经在保护敦煌莫高窟方面与敦煌研究院有一些合作,有专门的摄像机保护那些洞窟里的壁画和佛龛)、自动驾驶汽车和物联网等。
Q&A
问:以前做深度神经网络做深了不稳定,是什么改变了稳定性,让深度神经网络可以运行下去?
郭百宁:神经网络做的时间很长,而且做的人非常多。以前用到计算机视觉里的很少,也不知道用到计算机领域上有什么好处。有的人说神经网络像炼丹,这里放一些东西,那里放一些东西,出来一些东西,里面怎么做大家都不知道。不是像一般的数学,你知道这里面有一个公式也知道怎么运用它,这个有点艺术在里面,还有一点手工,你要在里面调。当时用神经网络最好是用两层,不要用三层,因为可能就不稳定,加了层数也不一定有什么优越性。
后来,由于计算机数字算法的改进实现了一些算法的稳定性。这实际上是一个积累的过程,在中国科学院也有这方面的专家,正在越做越好,让大家可以做的很深,但是当时的很深也就是六七层。有一个转折就是多伦多大学的研究员Alex,证实了七八层的神经网络不但可做,而且在机器学习上很强大,他们有一个整体的概念。2012年是他们第一次有了这个概念,赢得了ImageNet之后,吸引了大家的注意力,大家就从做计算机视觉的角度来研究深度神经网络。
问:您还提到学习估值和真实函数的差异,真实函数是怎么确定下来的?
郭百宁:每一个神经元的函数比较简单,最简单的函数就是identity函数:X等于X。如何知道估值函数是什么?最简单的方法就是去设置估值的函数。一个小神经元就是做很简单的事,说不定也就只干这个。这个残差学习的方法可以追溯到很多工程里面,借鉴了这里面的一些思想。这个思想又是在传统领域里积累了很多年的真知灼见。我们发现了这个方法可以借鉴过来,真的行的通。
问:在计算机视觉方面,微软接下来的两三年还有哪些会重点发力的领域?
郭百宁:我们是比较独立,不会去追踪热点。可能会集中精力投入到我们认为是核心的技术上,把核心技术做好。我们要做的核心技术有各种各样,其中一个是人脸相关的。我们认为一张图的重点就是人,人最重要的就是脸。把人脸做好已经很好了,但还要继续做好。
问:人脸包括很多方面,业界的水平基本上没有相差太多,我们会重点发力哪个细分方向?
郭百宁:竞争是很激烈的,我们会继续走下去。里面这些技术,虽然我们是最好的之一,但也知道这些技术是有缺陷的。其实最终还是要把这些技术扎扎实实地用到应用上去。比如说美国最近出现了一些警察和平民之间的暴力事件。美国出了一个法律,所有的警察跟平民交互的时候都要戴上视频摄像头,摄像头的数据直接传到云里面,假如公众要调用那个视频一定要可用(available)。这很好地改善了警察和平民之间的交互,大家的态度好了很多。
其中有一个问题:要屏蔽掉不该照的人,比如路人。屏蔽是不能漏任何一帧的,假如漏了任何一帧,那个人的身份就被暴露了,就有可能告你。举个例子,一个有色人种在高档的社区但是比较穷,警察去问问他,然后照了照片。那个照片上看不出没有任何犯罪,但是那个照片要是被人认出来,认为他在某个地方被警察询问,他完全没有干任何事情,人家会很愤怒。不能漏帧,就是人脸检测跟踪,一定要跟紧了,我们刚才看到那个跑动的demo,例子中我们跟的很紧,有的时候人脸会转,甚至人脸背过去也一定要跟住。并不是所有人都可以做的特别好,我们最近在这方面有很大的进展,你们将来会看到一些demo,我们真的可以做到比竞争对手做的更好。你去用一些著名的软件,看看它里面也都提供人脸跟踪的功能,你会发现它会漏掉。所以说安防是一个很重要的领域,有很多的商机在里面,一旦有技术突破,很多东西就可以用了。
视频分析也是我们接下来比较重要的研究。在微软认知服务中也有视频的API,我们也把这些技术对外开放,拿去让创业公司开发新的东西,制造一个生态系统。
问:计算机视觉在无人驾驶的应用还有什么问题?
郭百宁:机器视觉在无人驾驶里面肯定是核心的。目前无人车可以在演示场景跑,但是要在全世界各地都能够跑,道路还很长,很多问题还没有解决,不一定全部是计算机视觉。无人车有几个传感器,摄像头只是其中一个,还有是雷达、激光、超声。最有挑战性的可能就是在一个城市里面,像中国的小县城里面,行为完全是随机的情况下还要确保人身安全,开起来很顺,那样是有一些挑战的。可能不久的将来可以做到,但需要解决的问题不只是计算机视觉。
问:除了民用的人脸识别和视频识别之外,微软计算机视觉方面有没有这种医学方面相关的?
郭百宁:计算机在医疗方面也有很大的作用。微软研究院有一个研究组,他们用DNA做很深入的研究,跟癌症做斗争。我不太了解他们做的工作,但领导人是微软研究院的老大,他是非常著名的人工智能的专家,美国科学院院士,是计算机科学家,也有行医执照。我们在北京这边也有跟大学的合作。原来我们看癌细胞都是用人眼看的,现在有了计算机视觉技术,可以让计算机来帮助人做一些筛选,或者做一些检测。一个是在癌症方面,一个是疟疾检测方面,主要用的技术就是计算机视觉和机器学习的相关技术。
问:您觉得增强算法在图像识别里面如何应用?
郭百宁:增强算法也不是一个新的算法,但在计算机视觉里面还没有用,我们确实有人用增强算法,那是一个很好的学习框架。做语音识别的霍强研究员最近有一个是并行训练的,他的算法能够在一个大规模的GPU群上跑起来,并行化就是可以提高效率,并行了之后,你要用100个机器并行,最好希望达到100×100的效率。