无监督学习及其主要研究进展
原文:Navigating the unsupervised learning landscape
作者:Eugenio Culurciello,普渡大学副教授&Teradeep创办人
译者:刘帝伟 审校:刘翔宇
责编:周建丁([email protected])
无监督学习可谓是深度学习的圣杯,其目标是建立可兼容小数据集进行训练的通用系统,即便是很少的数据。
如今深度学习模型往往在大型监督型数据集上训练。所谓监督型数据集,即每条数据都有一个对应的标签。比如流行的ImageNet数据集,有一百万张人为标记的图像。一共有1000个类,每个类有1000张图像。创建这样的数据集需要花费大量的精力,同时也需要很多的时间。现在想象创建一个有1M个类的数据集。试想一下,对有100M数据帧的视频数据集的每一帧进行分类。该任务量简直不可估量。
现在,回想一下你在小时候是如何进行学习的。是的,那时候会有人指导你,你的父母会告诉你这是一个“猫”,但是他们不会在你余生的每一分每一秒都告诉你这是一只“猫”!如今的监督学习也是这样:我一次一次地告诉你,什么是“猫”,也许高达100万次。然后你的深度学习模型就学会了。
理想情况下,我们希望有一个模型,它的表现与我们的大脑非常相似。只需少量的标签便可理解这个多类的世界。这里所说的类,主要是指对象类、动作类、环境类、对象组成类等等。
基本概念
无监督学习研究的主要目标是预训练一个模型(称作“识别”或“编码”)网络,供其他任务使用。编码特征通常能够用到分类任务中:例如在ImageNet上训练会表现出很好的结果,这与监督模型非常接近。
迄今为止,监督模型总是比无监督的预训练模型表现的要好。其主要原因是监督模型对数据集的特性编码的更好。但如果模型运用到其他任务,监督工作是可以减少的。在这方面,希望达到的目标是无监督训练可以提供更一般的特征,用于学习并实现其它任务。
自动编码器(auto-encoders)
该理论主要源于1996年Bruno Olshausen and David Field发表的文章。此文表明,编码理论可应用于视觉皮层感受野。他们发现,我们大脑的主要视觉皮层(V1)使用稀疏原理来创建可以用来重建输入图像的最小基函数子集。
更多内容请点击这里。
YannLeCun团队在该领域也做了很多工作。在余下的文章中,你将看到一个很好的例子来解释类似V1的稀疏滤波器是如何学习的。
栈式自动编码器也会被用到,以贪婪式的方式逐层重复训练。
自动编码器方法也被称为“直接映射”方法。
堆叠无监督层(stacked unsupervised layers)
一种结合k-均值聚类方法去学习多层中过滤器的技术。
我们团队把这种方法称为:聚类学习(Clustering Learning)、聚类连接(Clustering Connections)和卷积聚类(Convolutional Clustering),最近在流行的STL-10无监督数据集上取得很好的效果。
我们在该方向的工作是对Adam Coates和Andrew Ng工作的独立开发。
受限玻尔兹曼机(RBMs)、深度玻尔兹曼机(DBMs)、深度信念网络(DBNs)因很难解决它们配分函数的数值而成为众所周知的难题。因此它们并没有被广泛地用来解决实际问题。
生成模型(generative models)
生成模型,尝试在同一时间创建一个分类(识别器或编码器)网络和一个生成图像(生成模型)模型。这种方法起源于Ian Goodfellow和 Yoshua Bengio的开创性工作。
Alec Radford、Luke Metz和Soumith Chintala的DCGAN是一种生成对抗模型,实例化这种模型,能够得到很好的结果。
模型的具体解释请点击这里。下面是系统框架图:
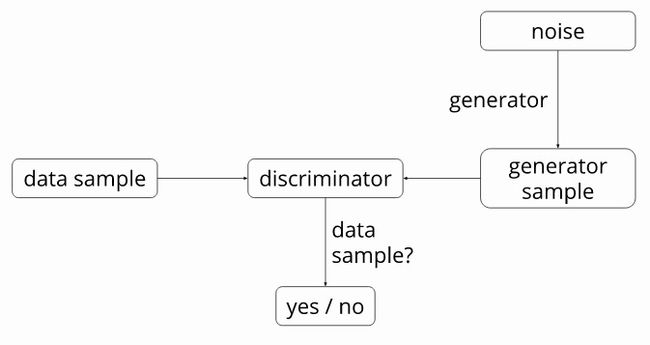
DCGAN识别器的目的是识别输入图像是否真实,或来自数据集,或是生成器生成的伪图。该生成器需要一个随机噪声向量(用1024个数值表示)作为输入,并产生一个图像。
在DCGAN中,生成器网络如下:
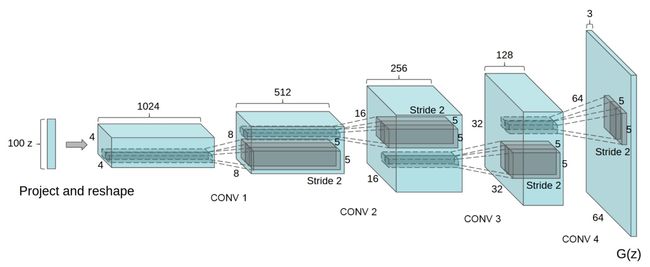
识别器是一个标准的神经网络。详情请见下文。
关键是以并行的方式训练两个网络而不是完全地过度拟合,从而复制数据集。学习特征需要推广到未知的实例,因此用于学习的数据集将不能再用。
Torch7提供了DCGAN的训练代码,可用于实验之中。
在生成器和识别器网络训练好之后,两者便可使用了。主要目标是为其它任务训练一个很好的识别器网络,例如对其它数据集进行分类。生成器则可用于生成随机向量的图像。这些图像有着非常有趣的特性。首先,他们提供了输入空间的平滑转换。看下面这个例子,它展示了在9个随机输入向量之间进行移动产出的图像:

输入向量空间还提供数学特性,表明学习特征是根据相似性进行组织的: 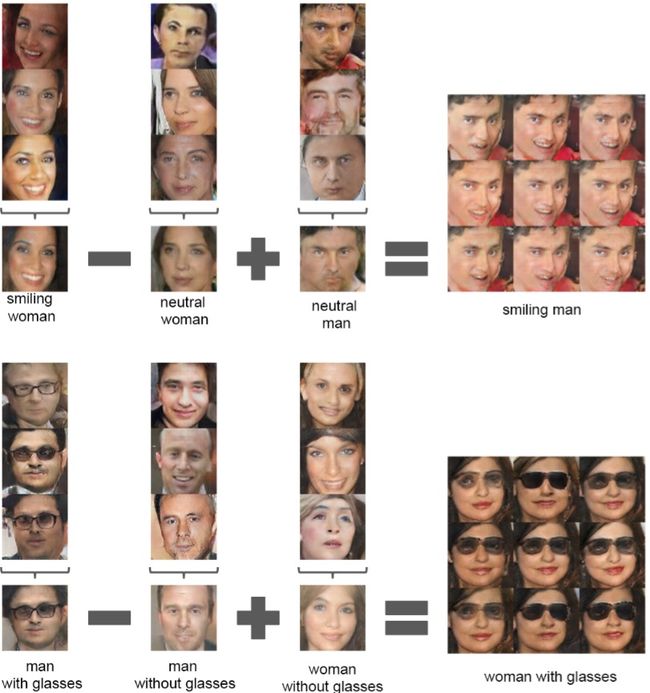
由生成器学到的光滑空间表明识别器也具有类似的性质,使它成为图像编码出色的特征提取器。这在不连续图像数据集训练CNN网络的经典问题上很有帮助,在这些数据集,对抗性噪声往往致使其走向失败。
从数据模型中学习
以解决拼图游戏来可视化表示无监督学习是个精巧的做法。作者将图像分成一个拼图,并训练一个深度神经网络来解决这个难题。由此所得网络是性能最高的预训练网络之一。
以图像补丁和局部性修复来展示无监督学习也是一个巧妙的做法。在这里,他们提取位于同一图像相近的两个补丁。从统计学来讲,这些补丁是相同的对象。第三个补丁是从一个随机的图片和位置中提取而得的,在统计学上与其它两个补丁不一样。然后使用深度神经网络进行训练,来区分同一对象的两个补丁或不同对象。由此所得网络也是性能最高的预训练网络之一。
以重建立体图像来可视化表示的无监督学习,采用立体图像,以左帧重建右帧。
使用视频可视化表示无监督学习。