Ensemble Learning 和 stacking、blending 区别
1 Ensemble Learning-模型融合
通过对多个单模型融合以提升整体性能。
1.1 Voting
投票制即为,投票多者为最终的结果。例如一个分类问题,多个模型投票(当然可以设置权重)。最终投票数最多的类为最终被预测的类。
1.2 Averaging
Averaging即所有预测器的结果平均。
回归问题,直接取平均值作为最终的预测值。(也可以使用加权平均)
分类问题,直接将模型的预测概率做平均。(or 加权)
加权平均,其公式如下: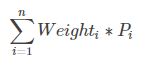
其中n表示模型的个数, 表示该模型权重,表示模型i的预测概率值。
例如两个分类器,XGBoost(权重0.4)和LightGBM(权重0.6),其预测概率分别为:0.75、0.5,那么最终的预测概率,(0.4 * 0.75+0.6 * 0.5)/(0.4+0.6)=0.6
模型权重也可以通过机器学习模型学习得到
1.3 Ranking
Rank的思想其实和Averaging一致,但Rank是把排名做平均,对于AUC指标比较有效。
个人认为其实就是Learning to rank的思想,可以来优化搜索排名。具体公式如下:

其中n表示模型的个数, 表示该模型权重,所有权重相同表示平均融合。![]() 表示样本在第i个模型中的升序排名。它可以较快的利用排名融合多个模型之间的差异,而不需要加权融合概率。
表示样本在第i个模型中的升序排名。它可以较快的利用排名融合多个模型之间的差异,而不需要加权融合概率。
1.4 Binning
将单个模型的输出放到一个桶中。参考pdf paper , Guocong Song ,
1.5 Bagging
使用训练数据的不同随机子集来训练每个 Base Model,最后每个 Base Model 权重相同,分类问题进行投票,回归问题平均。
随机森林就用到了Bagging,并且具有天然的并行性。
1.6 Boosting
Boosting是一种迭代的方法,每一次训练会更关心上一次被分错的样本,比如改变被错分的样本的权重的Adaboost方法。还有许多都是基于这种思想,比如Gradient Boosting等。
经典问题:随机森林、Adaboost、GBDT、XGBoost的区别是什么?(面试常常被问)
1.7 Stacking
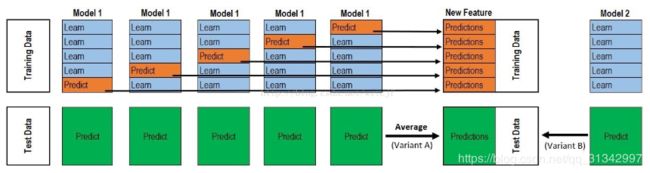
上半部分是用一个基础模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为testing data。注意:在stacking中此部分数据会用到整个traing set。如:假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,testing data是2000行。
每一次的交叉验证包含两个过程,1. 基于training data训练模型;2. 基于training data训练生成的模型对testing data进行预测。在整个第一次的交叉验证完成之后我们将会得到关于当前testing data的预测值,这将会是一个一维2000行的数据,记为a1。注意!在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这个过程会生成2500个预测值,这部分预测值将会作为下一层模型testing data的一部分,记为b1。因为我们进行的是5折交叉验证,所以以上提及的过程将会进行五次,最终会生成针对testing set数据预测的5列2000行的数据a1,a2,a3,a4,a5,对testing set的预测会是5列2500行数据b1,b2,b3,b4,b5。
在完成对Model1的整个步骤之后,我们可以发现a1,a2,a3,a4,a5其实就是对原来整个training set的预测值,将他们拼凑起来,会形成一个10000行一列的矩阵,记为A1。而对于b1,b2,b3,b4,b5这部分数据,我们将各部分相加取平均值,得到一个2500行一列的矩阵,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。
在此之后,我们把A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为training data,B1,B2,B3,B4,B5并列合并得到一个2500行五列的矩阵作为testing data。让下一层的模型,基于他们进一步训练。
以上即为stacking的完整步骤!
1.8 Blending
Blending直接用不相交的数据集用于不同层的训练。
以两层的Blending为例,训练集划分为两部分(d1,d2),测试集为test。
第一层:用d1训练多个模型,讲其对d2和test的预测结果作为第二层的New Features。
第二层:用d2的New Features和标签训练新的分类器,然后把test的New Features输入作为最终的预测值。