SQL的很多概念无法直接映射到流计算,这就是在流计算上定义SQL的难点。
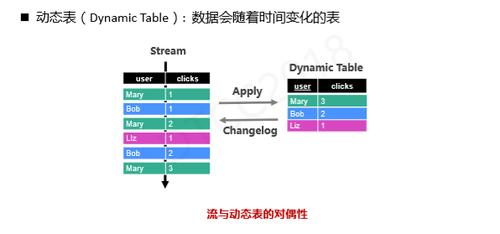
为了在流计算上定义SQL,我们需要引入几个概念。既然批处理需要定义SQL表的概念,那在流计算上也需要表的概念,我们需要将传统静态表扩展成动态表,所谓动态表就是数据会随时间而不断变化的表。此时,我们发现流和动态表之间有一种对偶性,也就是说流和动态表可以相互转换。将流的每条数据插入到数据库中,就得到了一张表;同时我们可以抽取动态表的changelog还原原始流。
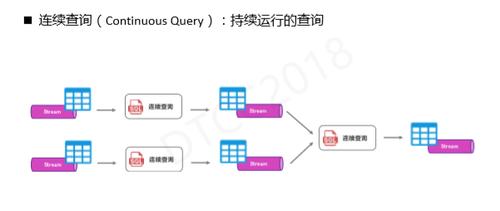
从流计算到SQL,我们可以把它看成是连续查询。连续查询区别于传统的批处理查询,需要源源不断地接收数据,每收到一条新数据就会更新结果且结果也是一张动态表,那结果的动态表又可以作为下一个查询的输入,从而串起整个流计算。 基于上述两个概念,我们可以在SQL上定义流计算。但是,流计算中的数据需要不断修正和更新,因此这些数据下发后可能导致最终结果的错误,我们需要把这些错误数据进行修正,这就涉及到流计算中一个非常重要的概念——Retraction。
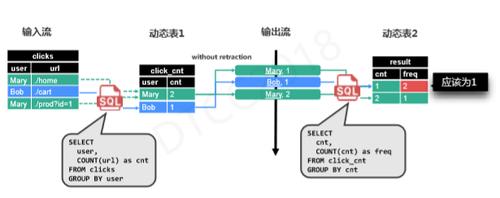
为了解释此概念,我们举一个简单的例子,上图所示有一个点击输入流,它具备两个字段:user和url,经过第一个查询根据用户进行分组,统计每个用户的点击次数;进入第二个查询,根据点击次数进行分组,统计每个次数的具体点击人数。最终,我们会收到两条记录,点击次数所对应的人数。从结果明显可以看出计算有误,Mary的数据并没有合并计数,这就需要引入修正的概念。
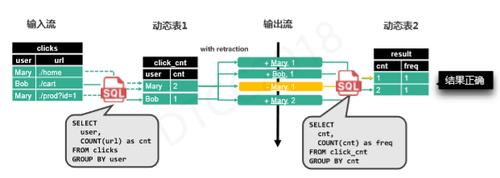
如上图所示,经过修正之后,经过第二个查询时,Mary的总查询次数会被合并计算,Mary 1的结果会被告知撤回,从而输出正确的结果,这就是引入Retraction的作用。在整个过程中,是否触发Retraction以及发送方式均由优化器决定,用户对整个过程是无感知的。 在此基础上,我们发现世界不需要所谓的Stream SQL语法,标准的ANSI SQL就可用来定义流计算,Flink SQL就是标准的ANSI SQL语法。其部分核心功能如下:DDL用来定义数据源表、数据结构表;UDF、UDTF、UDAF用户自定义函数,可以定制化用户复杂的业务需求;JOIN是一个比较复杂的功能,包括流与流之间的Join,流与表之间的Join以及Windows Join等;聚合功能包括类似Group AGG,Windoes Agg以及Over Agg等。

接下来我会结合实例对核心功能进行介绍。首先是装载数据,需要create table语法。如上图所示,我们先定义一张clicks表,然后定义表的schema、user、cTime以及url,with里是表的一系列属性,它是一个来自kafka的日志表,我们可以用SELECT * FROM clicks查询转载表里面的数据。

如果要将上述查询数据写到某个表中,我们需要用create table定义结果表,语法同上,创建一张 last_clicks 结果表,主键是user,通过INSERT INTO 语法将上述查询数据插入Mysql表中。

如果想把中间处理结果同时写入多个存储,比如把数据处理结果同时写到Mysql和HBase,如上使用CREATE VIEW 定义一个来自淘宝的点击记录,同时连续写多个INSERT INTO到Mysql和HBase。
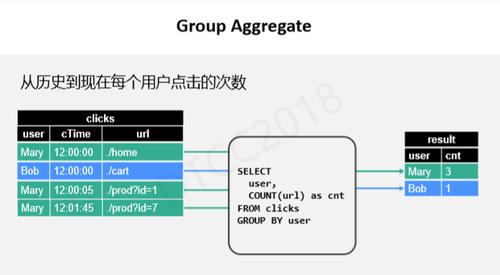
接下来是Group Aggregate,也就是无限流量聚合。所谓无限流量聚合指从历史开始到现在的所有用户点击数据,如上查询展示的是根据用户分组,然后统计点击次数。如果来了一条Mary1的数据,我们就先插入该数据,后续如果Mary再次进行点击,我们就在原数据基础上进行修改更新,以此类推。
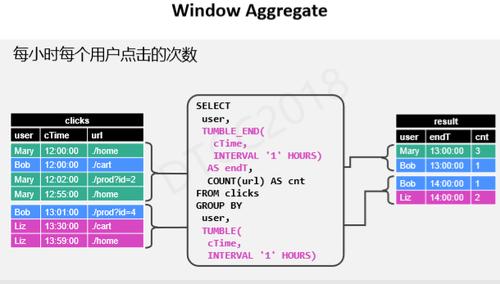
Window Aggregate是定义在窗口上的聚合,有别于上述无限流聚合,它的原理是是每个窗口对应输出一个结果,比如每小时每个用户的点击次数,需要在group by的结果上加上endT数据,也就是窗口标识。

接下来介绍双流join,目前我们支持INNER, LEFT, RIGHT, FULL, SEMI, ANTI等Join类型,举例说明双流Join的主要使用场景,比如把主流打成宽表,并补上额外字段等。如上图所示,我们需要将订单和物流表信息进行Join操作,在Join的物理实现上会有两份状态,用来存储两条流到目前为止收到的所有历史数据,淘汰机制时间设定为一天半一次。两者中任何一方信息延迟都会先在表中等待,直到同一个订单的信息与物流关联之后才会通过Join输出。
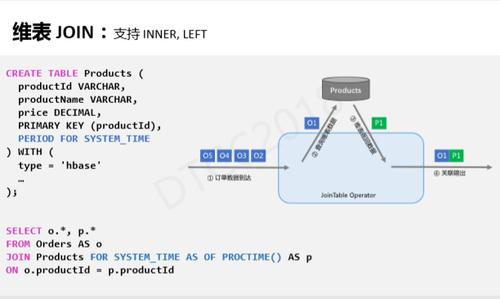
维表Join与双流Join类似,目前支持INNER, LEFT两种交易类型。维表Join的使用同样为补全主流,但想补全的字段在另一维表中。如上图所示,使用时首先需要通过CREATE TABLE 语法定义一张维表,此处定义的是 Products 表,存储与产品相关信息,查询同样使用Join语法。Order与Products表通过Products ID实现Join。关键字PERIOD FOR SYSTEM_TIME 是 SQL 2.11标准里的语法,意思是当前关联的Products是当前时刻的信息,关联之后不再更新信息。上图右侧展示的是维表Join物理执行的概念。我们可以根据Order去Products数据库里查询信息,最终Products维表返回关联信息。 核心功能如上所述,接下来主要聊优化。维表中,订单O1查询时是堵塞等待IO的状态,此时无论如何调优性能,吞吐量和CPU使用率都上不去,因此我们引入异步IO功能。

如上左半部分为未引入异步IO时的状态,如上右半部分为引入后,此时若发起A请求,不需等待IO就可立刻发起BCD查询请求,然后异步等待返回结果。返回ABCD以后再管理输出,极大地提高了整体性能。

如上,异步IO使用时与维表Join只有一行配置改动,对于用户来说,这个使用是非常简便的。
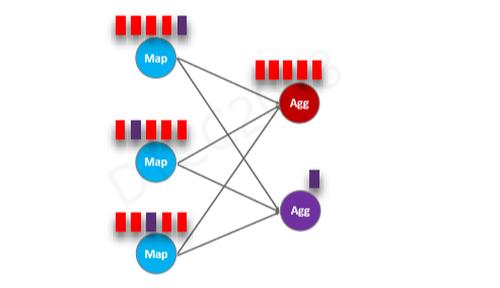
第二个优化是大数据中的常见场景——数据倾斜。如上为改进之前,红色聚合节点出现数据积压现象,而紫色节点相对较空。

如果持续一段时间,红色聚合节点就会被打满,从而变为热点,所有上游map节点就会反压,停止处理数据进入等待状态,而下游的紫色节点基本处于空闲状态。
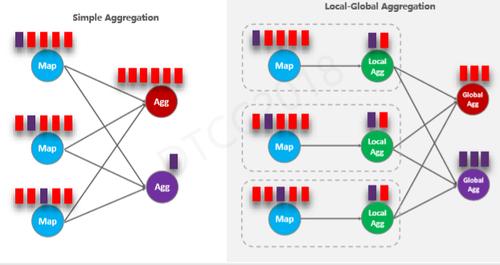
我们引入Local-Global 聚合优化。左图是未优化拓扑图,右边是引入Local-Global优化后的图,我们在Map后引入Local Agg节点,Map与Local Agg是链在一起的一个线程,之间的数据传输没有任何网络开销。Local Agg可以将收到的数据按照 key进行预聚合,然后将结果按照 key分发给下游Global Agg进行汇总。 假如每个Map的 TPS 是每秒1万的数据量,全局就2个 key:红色和紫色。如果 Local Agg聚合的间隔是每秒钟一次,那么每个Local Agg能将1万条数据预聚合成最多2条(全局共2个 key)。那么Global Agg每秒钟最多收到只会三条消息,能有效降低Global Agg 的热点。优化后,我们对此进行性能测试,发现Local-Global 可以带来超过20倍的性能提升。因此,整个方案是十分有效的。