深度学习之 CGAN及TensorFlow 实现
本文介绍CGAN(Conditional Generative Adversarial Nets)- 条件生成对抗网络
相关论文 https://arxiv.org/pdf/1411.1784.pdf
1、概述
CGAN( Conditional Generative Adversarial Nets),条件生成对抗网络。条件生成对抗网络指的是在生成对抗网络中
加入条件(condition),条件的作用是监督生成对抗网络。最基本的对抗网具有以下优点:永远不需要马尔可夫链,仅使用
反向传播来获得梯度,在学习期间不需要推理,并且可以容易地将各种因素和相互作用结合到模型中。
在无条件的生成模型中,无法控制正在生成的数据的模式。但是,通过在附加信息上调整模型,可以指导数据生成过程。
这种调节可以基于类别标签,在某些部分数据上进行修复,甚至是来自不同模态的数据。
2、生成对抗网络
GAN(Generative Adversarial Nets)由两个“对抗”模型组成:一个捕获数据分布的生成模型G和一个判别模型D,
它估计样本来自训练数据的概率而不是生成样本的概率. G和D都可以是非线性的映射函数,例如多层感知器。
为了在数据数据x上学习生成器分布p_z(z) ,生成器建立从先前噪声分布p_z(z)到数据空间的映射函数,如G(z;θg)。
鉴别器D(x;θd)输入是真实图像或者生成图像,输出单个标量,该标量表示x来自训练数据而不是p_g的概率。
G和D都同时训练:固定判别模型 D,调整 G 的参数使得 log(1−D(G(z))的期望最小化;固定生成模型 G,调整 D 的参数
使得 logD(X)+log(1−D(G(z)))log 的期望最大化,这个优化过程归结为二元极小极大博弈(minimax two-player game)”问题:
![]()
3、条件生成对抗网络
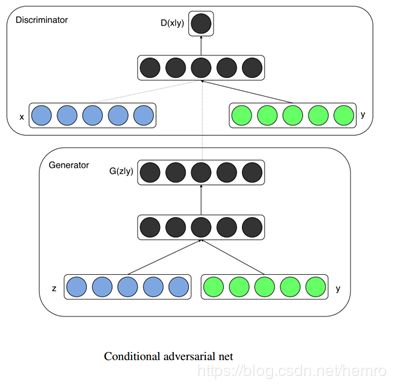
条件生成式对抗网络(CGAN)是对原始GAN的一个扩展,生成器和判别器都增加额外信息 y为条件, y可以使任意信息,
例如类别信息,或者其他模态的数据。
如下图所示,通过将额外信息 y 输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN。在生成模型中,
先验输入噪声 p(z) 和条件信息 y 联合组成了联合隐层表征。对抗训练框架在隐层表征的组成方式方面相当地灵活。类似地,
条件 GAN 的目标函数是带有条件概率的二人极小极大值博弈(two-player minimax game ):
![]()
4、TensorFlow实现通过mnist数据集生成手写数字
完整代码 https://github.com/clark82/deeplearning
4.1 代码解读
输入数据,其中 real_img_digit为真实数据的标签数据,10维的向量,即条件信息。此信息可以引导生成哪个数字。
def inputs(real_size, noise_size):
"""
真实图像tensor与噪声图像tensor
"""
real_img_digit = tf.placeholder(tf.float32, [None, k], name='real_img_digit')
real_img = tf.placeholder(tf.float32, [None, real_size], name='real_img')
noise_img = tf.placeholder(tf.float32, [None, noise_size], name='noise_img')
return real_img, noise_img, real_img_digit
生成器,和基础的GAN基本一样,先条件信息和noise数据拼接,之后操作和GAN完全一样
def generator(digit, noise_img, n_units, out_dim, reuse=False, alpha=0.01):
"""
digit:输入的条件信息
noise_img: 生成器的输入
n_units: 隐层单元个数
out_dim: 生成器输出tensor的size,这里应该为32*32=784
alpha: leaky ReLU系数
"""
with tf.variable_scope("generator", reuse=reuse):
concatenated_img_digit = tf.concat([digit, noise_img], 1)
# hidden layer
hidden1 = tf.layers.dense(concatenated_img_digit, n_units)
# leaky ReLU ,和ReLU区别:ReLU是将所有的负值都设为零,相反,Leaky ReLU是给所有负值赋予一个非零斜率。
hidden1 = tf.maximum(alpha * hidden1, hidden1)
# dropout
hidden1 = tf.layers.dropout(hidden1, rate=0.2)
# logits & outputs
logits = tf.layers.dense(hidden1, out_dim)
outputs = tf.tanh(logits)
return outputs
判别器,和基础的GAN基本一样,先条件信息和真实数据拼接,之后操作和GAN完全一样
def discriminator(digit, img, n_units, reuse=False, alpha=0.01):
"""
digit:输入的条件信息
n_units: 隐层结点数量
alpha: Leaky ReLU系数
"""
with tf.variable_scope("discriminator", reuse=reuse):
concatenated_img_digit = tf.concat([digit, img], 1)
# hidden layer
hidden1 = tf.layers.dense(concatenated_img_digit, n_units)
hidden1 = tf.maximum(alpha * hidden1, hidden1)
# logits & outputs
logits = tf.layers.dense(hidden1, 1)
outputs = tf.sigmoid(logits)
return logits, outputs
损失函数和GAN完全一样,训练过程增加标签信息
for batch_i in range(mnist.train.num_examples//batch_size):
batch = mnist.train.next_batch(batch_size)
# 这里读取标签信息,作为real_img_digit: digits,batch数据
digits = batch[1]
batch_images = batch[0].reshape((batch_size, 784))
# 对图像像素进行scale,这是因为tanh输出的结果介于(-1,1),real和fake图片共享discriminator的参数
# 把图片灰度0~1变成 -1 到1的值, 以适应generator输出的结果(-1,1)
batch_images = batch_images*2 - 1
# generator的输入噪声
batch_noise = np.random.uniform(-1, 1, size=(batch_size, noise_size))
# Run optimizers
_ = sess.run(d_train_opt, feed_dict={real_img_digit: digits, real_img: batch_images, noise_img: batch_noise})
_ = sess.run(g_train_opt, feed_dict={real_img_digit: digits, noise_img: batch_noise})
4.2 调试
完整的代码https://github.com/clark82/deeplearning
1、下mnist数据,拷贝到MNIST_data目录下
2、训练模型
python train.py -f 0
输出如下过程,训练正常运行
Epoch 1/300… Discriminator Loss: 0.2163(Real: 0.0101 + Fake: 0.2062)… Generator Loss: 1.9151
Epoch 2/300… Discriminator Loss: 0.2752(Real: 0.0348 + Fake: 0.2404)… Generator Loss: 6.2620
Epoch 3/300… Discriminator Loss: 0.6922(Real: 0.3858 + Fake: 0.3064)… Generator Loss: 2.3120
Epoch 4/300… Discriminator Loss: 2.1965(Real: 0.8177 + Fake: 1.3788)… Generator Loss: 1.0322
3、查看训练过程中生成状态
python train.py -f 2
4、验证模型,生成一批数据
python train.py -f 1
这里可以把生成条件信息(标签)打印出来,观察其生成数据的关系
# 生成标签用户生成图片
digits = np.zeros((25, k))
for i in range(0, 25):
j = np.random.randint(0, 9, 1)
digits[i][j] = 1
print (digits)
gen_samples = sess.run(generator(real_img_digit, noise_img, g_units, img_size, reuse=True),
feed_dict={real_img_digit: digits, noise_img: sample_noise})
输出结果,可以看到输入标签和生成的数字一一对应
[[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] – 5
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] – 1
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] – 6
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]]
