ICML 2018 深度学习论文及代码集锦(3)
[1] Which Training Methods for GANs do actually Converge?
Lars Mescheder, Andreas Geiger, Sebastian Nowozin
MPI, ETH, Microsoft Research
http://proceedings.mlr.press/v80/mescheder18a/mescheder18a.pdf
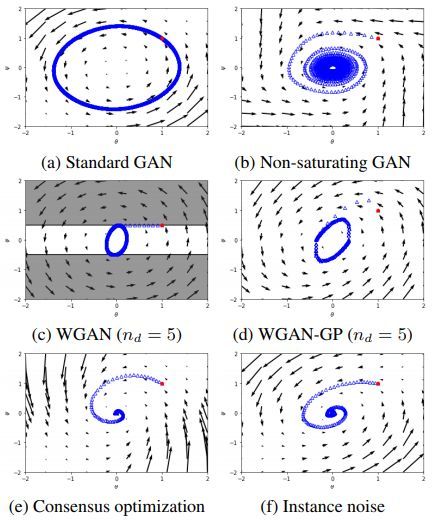
不同方法的收敛特性对比如下

基于梯度下降的GAN优化算法通常不收敛的示例如下

Dirac-GAN定义如下

不同方法对比如下

几种方法的收敛特性对比如下

代码地址
https://github.com/LMescheder/GAN_stability
 我是分割线
我是分割线
[2] Orthogonal Recurrent Neural Networks with Scaled Cayley Transform
Kyle E. Helfrich, Devin Willmott, Qiang Ye
University of Kentucky
http://proceedings.mlr.press/v80/helfrich18a/helfrich18a.pdf
各方法对比如下

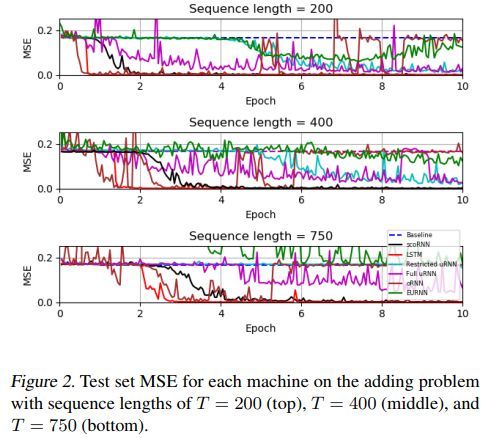

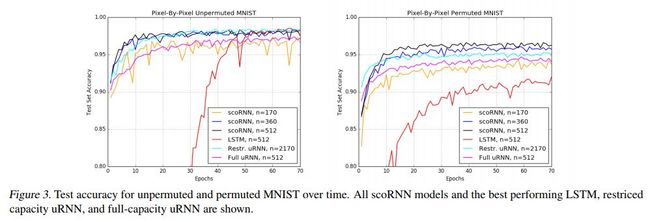
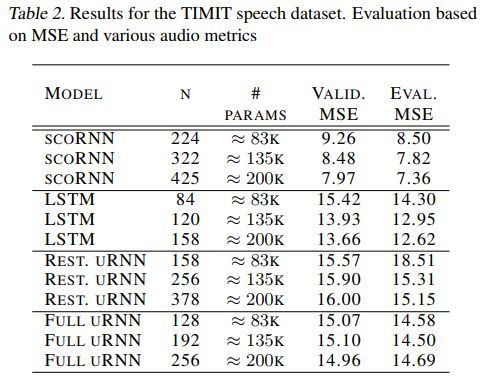

代码地址
https://github.com/SpartinStuff/scoRNN
我是分割线
[3] Spotlight: Optimizing Device Placement for Training Deep Neural Networks
Yuanxiang Gao, Li Chen, Baochun Li
University of Toronto, University of Electronic Science and Technology of China
http://proceedings.mlr.press/v80/gao18a/gao18a.pdf
多阶段马尔科夫决策过程用于设备放置问题的示例如下
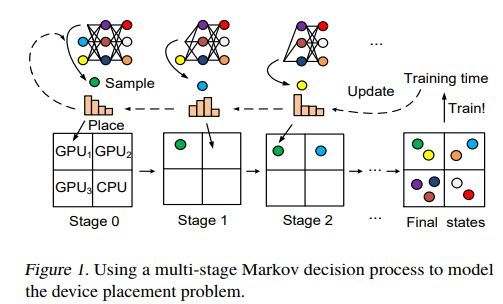
设备放置马尔科夫决策过程的状态树示例如下
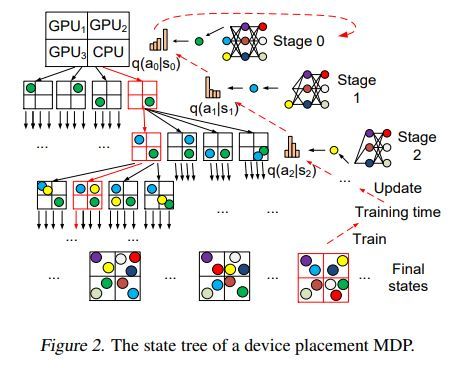
算法伪代码如下

放置策略可以用序列到序列的RNN来表示
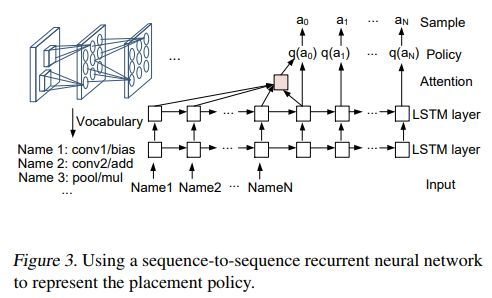
各方法对比如下


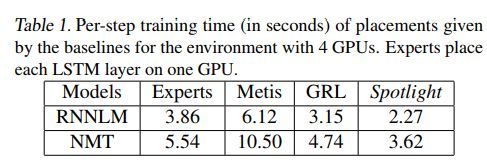
我是分割线
[4] χ 2 Generative Adversarial Network
Chenyang Tao, Liqun Chen, Ricardo Henao, Jianfeng Feng, Lawrence Carin
Duke University, Fudan University
http://proceedings.mlr.press/v80/tao18b/tao18b.pdf
卡方GAN算法伪代码示例如下

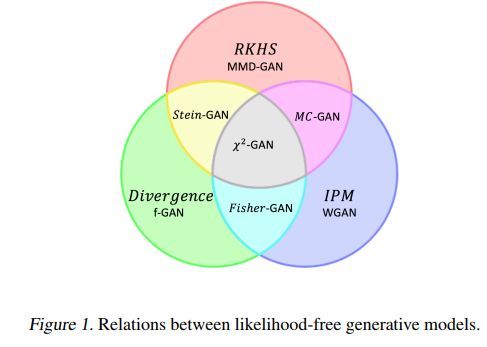
各种GAN之间的关系如下
重要性重采样算法伪代码如下

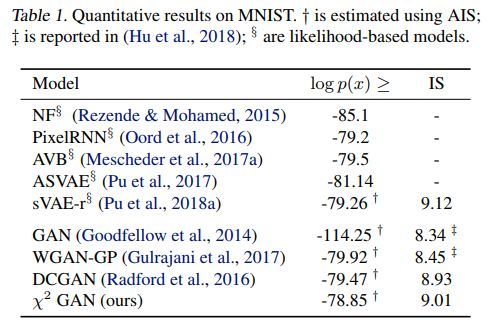
几种GAN的对比如下

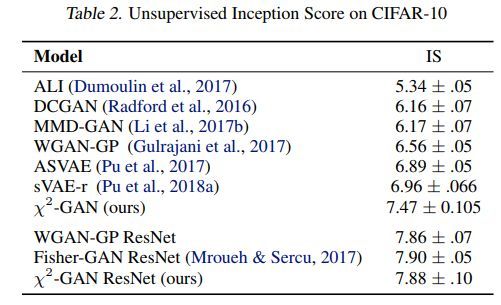
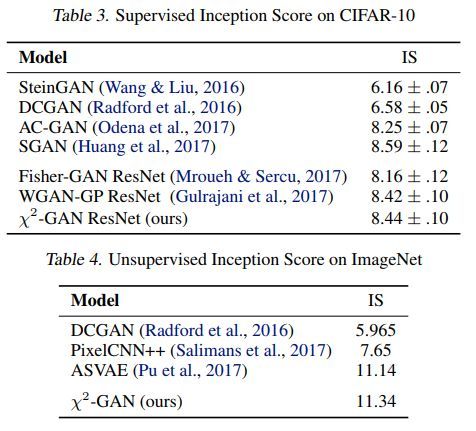
各方法效果对比如下
代码地址
https://github.com/chenyang-tao/chi2gan
(暂未上传)
我是分割线
[5] Deep Linear Networks with Arbitrary Loss: All Local Minima Are Global
Thomas Laurent, James H. von Brecht
Loyola Marymount University, California State University
http://proceedings.mlr.press/v80/laurent18a/laurent18a.pdf
这篇论文是偏理论的,相关假设和定理如下

定理一
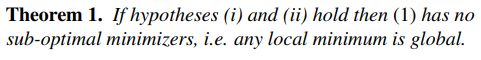
定理二
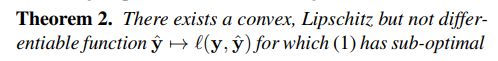
![]()
定理三

引理一

陈述一

陈述二

我是分割线
[6] Deep Predictive Coding Network for Object Recognition
Haiguang Wen, Kuan Han, Junxing Shi, Yizhen Zhang, Eugenio Culurciello, Zhongming Liu
Purdue University
http://proceedings.mlr.press/v80/wen18a/wen18a.pdf
一般CNN的结构示例如下
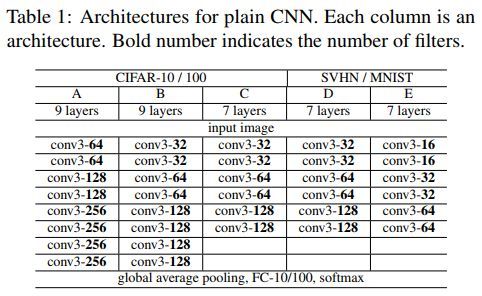
本文算法伪代码如下

PCN与CNN结构对比如下

各方法效果对比如下

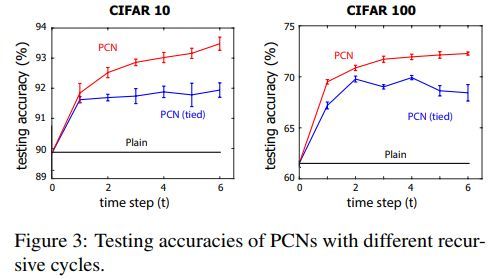
PCN用于图像分类的过程示例如下
各方法效果对比如下


代码地址
https://github.com/libilab/PCN-with-Global-Recurrent-Processing
我是分割线
您可能感兴趣