Python爬虫入门教程 30-100 高考派大学数据抓取 scrapy
1. 高考派大学数据----写在前面
终于写到了scrapy爬虫框架了,这个框架可以说是python爬虫框架里面出镜率最高的一个了,我们接下来重点研究一下它的使用规则。
安装过程自己百度一下,就能找到3种以上的安装手法,哪一个都可以安装上
可以参考 https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html 官方说明进行安装。
2. 高考派大学数据----创建scrapy项目
通用使用下面的命令,创建即可
scrapy startproject mySpider
完成之后,你的项目的目录结构为
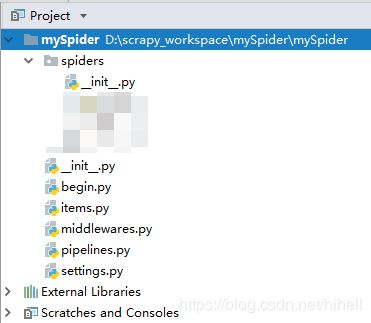
每个文件对应的意思为
- scrapy.cfg 项目的配置文件
- mySpider/ 根目录
- mySpider/items.py 项目的目标文件,规范数据格式,用来定义解析对象对应的属性或字段。
- mySpider/pipelines.py 项目的管道文件,负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库)
- mySpider/settings.py 项目的设置文件
- mySpider/spiders/ 爬虫主目录
- middlewares.py Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。 本篇文章没有涉及
高考派大学数据----创建Scrapy爬虫
通过命令行进入到 mySpider/spiders/ 目录,然后执行如下命令
scrapy genspider GaoKao “www.gaokaopai.com”
打开mySpider/spiders/ 目录里面的 GaoKao,默认增加了 下列代码
import scrapy
class GaoKaoSpider(scrapy.Spider):
name = "GaoKao"
allowed_domains = ["www.gaokaopai.com"]
start_urls = ['http://www.gaokaopai.com/']
def parse(self, response):
pass
默认生成的代码,包含一个GaoKaoSpider的类,并且这个类是用scrapy.Spider继承来的
而且默认实现了三个属性和一个方法
name = “” 这个是爬虫的名字,必须唯一,在不同的爬虫需要定义不同的名字
allowed_domains = [] 域名范围,限制爬虫爬取当前域名下的网页
start_urls =[] 爬取的URL元组/列表。爬虫从这里开始爬取数据,第一次爬取的页面就是从这里开始,其他的URL将会从这些起始的URL爬取的结果中生成
parse(self,response) 解析网页的方法,每个初始URL完成下载后将调用,调用的时候传入每一个初始URL返回的Response对象作为唯一参数,主要作用1、负责解析返回的网页数据,response.body 2、生成下一页的URL请求
高考派大学数据----第一个案例
我们要爬取的是高考派大学数据 数据为 http://www.gaokaopai.com/rank-index.html

页面下部有一个加载更多,点击抓取链接

尴尬的事情发生了,竟然是一个POST请求,本打算实现一个GET的,这回代码量有点大了~

scrapy 模式是GET请求的,如果我们需要修改成POST,那么需要重写Spider类的start_requests(self) 方法,并且不再调用start_urls里面的url了,所以,咱对代码进行一些修改。重写代码之后,注意下面这段代码
request = FormRequest(self.start_url,headers=self.headers,formdata=form_data,callback=self.parse)
FormRequest 需要引入模块 from scrapy import FormRequest
self.start_url 写上post请求的地址即可
formdata用来提交表单数据
callback调用网页解析参数
最后的 yield request 表示这个函数是一个生成器
import scrapy
from scrapy import FormRequest
import json
from items import MyspiderItem
class GaokaoSpider(scrapy.Spider):
name = 'GaoKao'
allowed_domains = ['gaokaopai.com']
start_url = 'http://www.gaokaopai.com/rank-index.html'
def __init__(self):
self.headers = {
"User-Agent":"自己找个UA",
"X-Requested-With":"XMLHttpRequest"
}
# 需要重写start_requests() 方法
def start_requests(self):
for page in range(0,7):
form_data = {
"otype": "4",
"city":"",
"start":str(25*page),
"amount": "25"
}
request = FormRequest(self.start_url,headers=self.headers,formdata=form_data,callback=self.parse)
yield request
def parse(self, response):
print(response.body)
print(response.url)
print(response.body_as_unicode())
我们在 def parse(self, response): 函数里面,输出一下网页内容,这个地方,需要用到1个知识点是
获取网页内容 response.body response.body_as_unicode()
- response.url获取抓取的rul
- response.body获取网页内容字节类型
- response.body_as_unicode()获取网站内容字符串类型
我们接下来就可以运行一下爬虫程序了
在项目根目录创建一个begin.py 文件,里面写入如下代码

from scrapy import cmdline
cmdline.execute(("scrapy crawl GaoKao").split())
运行该文件,记住在scrapy中的其他py文件中,运行是不会显示相应的结果的,每次测试的时候,都需要运行begin.py 当然,你可起一个其他的名字。
如果你不这么干的,那么你只能 采用下面的操作,就是比较麻烦。
cd到爬虫目录里执行scrapy crawl GaoKao--nolog命令
说明:scrapy crawl GaoKao(GaoKao表示爬虫名称) --nolog(--nolog表示不显示日志)

运行起来,就在控制台打印数据了,测试方便,可以把上述代码中那个数字7,修改成2,有心人能看到我这个小文字
pycharm在运行过程中,会在控制台打印很多红色的字,没事,那不是BUG
一定要在红色的字中间找到黑色的字,黑色的字才是你打印出来的数据,如下,得到这样的内容,就成功一大半了。
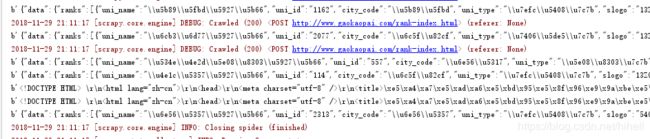
但是这个地方有个小坑,就是,你会发现返回的数据不一致,这个我测试了一下,是因为第一页的数据返回的不是JSON格式的,而是普通的网页,那么我们需要针对性处理一下,这个先不用管,我们把items.py 进行完善
import scrapy
class MyspiderItem(scrapy.Item):
# 学校名称
uni_name = scrapy.Field()
uni_id = scrapy.Field()
city_code = scrapy.Field()
uni_type = scrapy.Field()
slogo = scrapy.Field()
# 录取难度
safehard = scrapy.Field()
# 院校所在地
rank = scrapy.Field()
然后在刚才的GaokaoSpider类中,继续完善parse函数,通过判断 response.headers["Content-Type"] 去确定本页面是HTML格式,还是JSON格式。
if(content_type.find("text/html")>0):
# print(response.body_as_unicode())
trs = response.xpath("//table[@id='results']//tr")[1:]
for item in trs:
school = MyspiderItem()
rank = item.xpath("td[1]/span/text()").extract()[0]
uni_name = item.xpath("td[2]/a/text()").extract()[0]
safehard = item.xpath("td[3]/text()").extract()[0]
city_code = item.xpath("td[4]/text()").extract()[0]
uni_type = item.xpath("td[6]/text()").extract()[0]
school["uni_name"] = uni_name
school["uni_id"] = ""
school["city_code"] = city_code
school["uni_type"] = uni_type
school["slogo"] = ""
school["rank"] = rank
school["safehard"] = safehard
yield school
else:
data = json.loads(response.body_as_unicode())
data = data["data"]["ranks"] # 获取数据
for item in data:
school = MyspiderItem()
school["uni_name"] = item["uni_name"]
school["uni_id"] = item["uni_id"]
school["city_code"] = item["city_code"]
school["uni_type"] = item["uni_type"]
school["slogo"] = item["slogo"]
school["rank"] = item["rank"]
school["safehard"] = item["safehard"]
# 将获取的数据交给pipelines,pipelines在settings.py中定义
yield school
parse() 方法的执行机制
- 使用yield返回数据,不要使用return。这样子parse就会被当做一个生成器。scarpy将parse生成的数据,逐一返回
- 如果返回值是request则加入爬取队列,如果是item类型,则交给pipeline出来,其他类型报错
到这里,如果想要数据准备的进入到 pipeline 中,你需要在setting.py中将配置开启
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'mySpider.pipelines.MyspiderPipeline': 300,
}
同时编写 pipeline.py 文件
import os
import csv
class MyspiderPipeline(object):
def __init__(self):
# csv 文件
store_file = os.path.dirname(__file__)+"/spiders/school1.csv"
self.file = open(store_file,"a+",newline='',encoding="utf-8")
self.writer = csv.writer(self.file)
def process_item(self, item, spider):
try:
self.writer.writerow((
item["uni_name"],
item["uni_id"],
item["city_code"],
item["uni_type"],
item["slogo"],
item["rank"],
item["safehard"]
))
except Exception as e:
print(e.args)
def close_spider(self,spider):
self.file.close()
好了,代码全部编写完毕,还是比较简单的吧,把上面的数字在修改成7,为啥是7,因为只能获取到前面150条数据

