Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析
mitmdump是mitmproxy的命令行接口,比Fiddler、Charles等工具方便的地方是它可以对接Python脚本。
有了它我们可以不用手动截获和分析HTTP请求和响应,只需写好请求和响应的处理逻辑即可。
它还可以实现数据的解析、存储等工作,这些过程都可以通过Python实现。
1.1 启动mitmdump 保存到文件
使用命令
mitmdump -w crawl.txt
其中 crawl.txt 可以为任意文件名,就可以保存相应的结果了
1.2 调用脚本文件
mitmdump -s script.py
script.py 文件中编写如下代码
# 修改UA
def request(flow):
flow.request.headers['User-Agent'] = 'MitmProxy'
print(flow.request.headers)
在夜神模拟器中打开http://httpbin.org/get
出现如下内容

出现上述内容比较你已经可以对网页request进行修改了,下面打开手机惠农APP,看一下如何去捕获相应的请求
2. 捕获手机惠农APP请求
这个地方千万不要单独依赖mitmdump,要不你会直接卡死的,你可以采用mitmweb,打开APP之后,等待一会,点击一个菜单进入。比如点击下面的供应大厅。
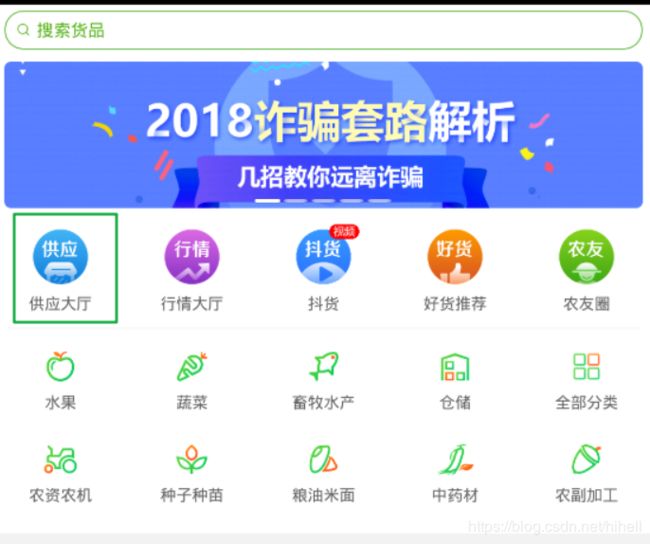
之后在mitmweb中捕获到列表页的数据连接,保存地址 https://truffle.cnhnb.com/banana/supply/query/list 方便进行后续的操作。
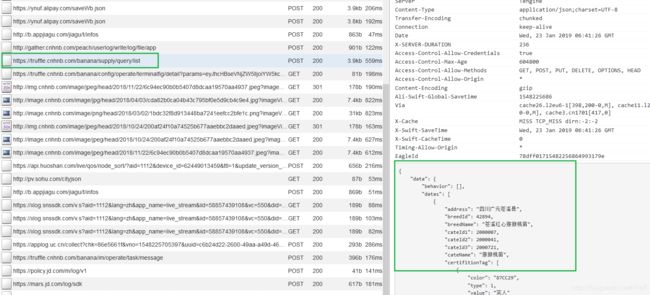
3. 完善script脚本
脚本主要有两部分构成,数据获取与数据存储,数据获取要注意,当访问的url匹配到刚才的地址的时候,就表示可以进行处理了
from mitmproxy import ctx
import json
import pymongo
# def request(flow):
# #flow.request.headers['User-Agent'] = 'MitmProxy'
# print(flow.request.headers)
def response(flow):
start_url = "https://truffle.cnhnb.com/banana/supply/query/list"
response = flow.response
info = ctx.log.info
if flow.request.url.startswith(start_url):
text = response.text
data = json.loads(text)
save(data)
def save(data):
DATABASE_IP = '127.0.0.1'
DATABASE_PORT = 27017
DATABASE_NAME = 'sun'
client = pymongo.MongoClient(DATABASE_IP, DATABASE_PORT)
db = client.sun
db.authenticate("dba", "dba")
collection = db.huinong # 准备插入数据
print(data["data"]["datas"])
collection.insert_many(data["data"]["datas"])
实现的效果
注意,现在还没有设置手机自动操作,所以操作是我手动滑动的。左侧数据已经成功的捕获到了。
4. 入库效果
数据存储到mongodb中,在处理就比较简单了

5. 其他说明
mitmdump提供了专门的日志输出功能,可以设定不同级别以不同颜色输出结果。
ctx模块有log功能,调用不同的输出方法就可以输出不同颜色的结果,以方便我们做调试。
ctx.log.warn(str(flow.request.query))
ctx.log.error(str(flow.request.headers))
更多的脚本例子,可以去参考。
https://github.com/mitmproxy/mitmproxy/tree/master/examples/simple
后续,我们将尝试将刚才的手动滑动修改成自动操作…
