Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
文章目录
- 说说这个网站
- 今天要爬去的网页
- 反爬措施展示
- 爬取关键信息
- 找关键因素
- 处理汽车参数
- 关键字破解
- 入库操作
- 小扩展:格式化JS
- 思路汇总
- 关注公众账号:非本科程序员
说说这个网站
汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之间对抗。
CSDN上关于汽车之家的反爬文章千千万万了,但是爬虫就是这点有意思,这一刻写完,下一刻还能不能用就不知道了,所以可以一直不断有人写下去。希望今天的博客能帮你学会一个反爬技巧。
今天要爬去的网页
https://car.autohome.com.cn/config/series/59.html#pvareaid=3454437
我们要做的就是爬取汽车参数配置
具体的数据如下

查看页面源代码发现,一个好玩的事情,源代码中使用了大量的CSS3的语法
下图,我标注的部分就是关键的一些数据了,大概在600行之后。

反爬措施展示
源文件数据
刹车/安全系统
页面显示数据

一些关键数据被处理过了。
爬取关键信息
我们要把源代码中的关键信息先获取到,即使他数据是存在反爬的。获取数据是非常简单的。通过request模块即可
def get_html():
url = "https://car.autohome.com.cn/config/series/59.html#pvareaid=3454437"
headers = {
"User-agent": "你的浏览器UA"
}
with requests.get(url=url, headers=headers, timeout=3) as res:
html = res.content.decode("utf-8")
return html
找关键因素
在html页面中找到关键点:
- var config
- var levelId
- var keyLink
- var bag
- var color
- var innerColor
- var option
这些内容你找到之后,你下手就用重点了,他们是什么?数据啊,通过简单的正则表达式就可以获取到了
def get_detail(html):
config = re.search("var config = (.*?)};", html, re.S)
option = re.search("var option = (.*?)};", html, re.S)
print(config,option)
输出结果
>python e:/python/demo.py
<re.Match object; span=(167291, 233943), match='var config = {"message":"<span class=\'hs_kw50_co>
>python e:/python/demo.py
<re.Match object; span=(167291, 233943), match='var config = {"message":" >
处理汽车参数
通过正则表达式的search方法,匹配数据,然后调用group(0) 即可得到相关的数据
def get_detail(html):
config = re.search("var config = (.*?)};", html, re.S)
option = re.search("var option = (.*?)};", html, re.S)
# 处理汽车参数
car_info = ""
if config and option :
car_info = car_info + config.group(0) + option.group(0)
print(car_info)
拿到数据之后,没有完,这是混淆之后的数据,需要解析回去,继续关注网页源代码,发现一段奇怪的JS。这段JS先不用管,留点印象即可~

关键字破解

注意到
hs_kw数字_configfH是一个span的class
我选中span之后的::before

对应的css为

发现实测两个字出现了,对应的class请记住
.hs_kw28_configfH::before
全局搜索一下
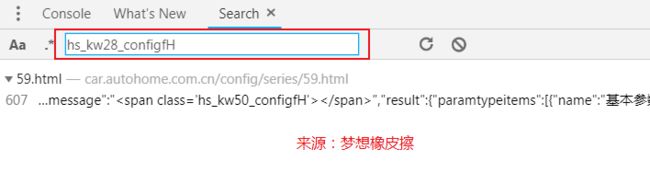
双击找到来源
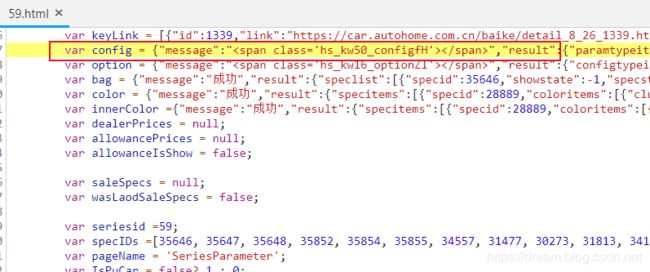
确定数据就在html源码当中。
格式化html源码,在内部搜索hs_kw,找到关键函数

function $GetClassName$($index$) {
return '.hs_kw' + $index$ + '_baikeCt';
}
这段JS的来源就是我们刚才保留的那个JS代码段,复制所有的JS源码,到source里面新建一个snippet,然后我们运行一下。

在里面代码最后添加一个断点,ctrl+enter运行

运行到断点,在右侧就能看到一些参数出现

- r u l e D i c t ruleDict ruleDict:
- r u l e P o s L i s t rulePosList rulePosList
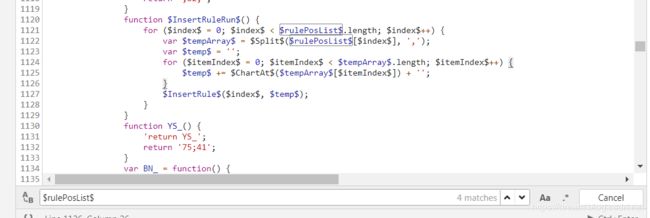
通过参数去查找,核心的替换方法
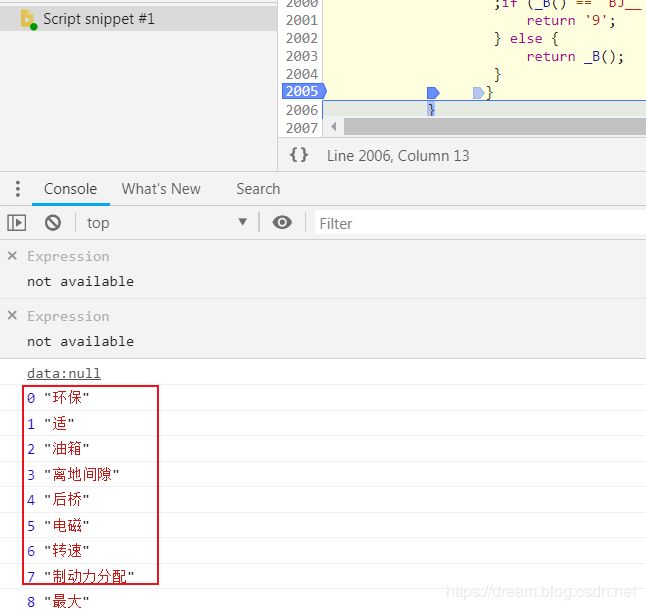
接下来,我们进行替换操作,这部流程需要用到selenium进行替换
核心代码如下,主要的注释,我写在了代码内部,希望能帮助你看懂
def write_html(js_list,car_info):
# 运行JS的DOM -- 这部破解是最麻烦的,非常耗时间~参考了互联网上的大神代码
DOM = ("var rules = '2';"
"var document = {};"
"function getRules(){return rules}"
"document.createElement = function() {"
" return {"
" sheet: {"
" insertRule: function(rule, i) {"
" if (rules.length == 0) {"
" rules = rule;"
" } else {"
" rules = rules + '#' + rule;"
" }"
" }"
" }"
" }"
"};"
"document.querySelectorAll = function() {"
" return {};"
"};"
"document.head = {};"
"document.head.appendChild = function() {};"
"var window = {};"
"window.decodeURIComponent = decodeURIComponent;")
# 把JS文件写入到文件中去
for item in js_list:
DOM = DOM + item
html_type = " "
# 再次运行的时候,请把文件删除,否则无法创建同名文件,或者自行加验证即可
with open("./demo.html", "w", encoding="utf-8") as f:
f.write(js)
# 通过selenium将数据读取出来,进行替换
driver = webdriver.PhantomJS()
driver.get("./demo.html")
# 读取body部分
text = driver.find_element_by_tag_name('body').text
# 匹配车辆参数中所有的span标签
span_list = re.findall("运行结果
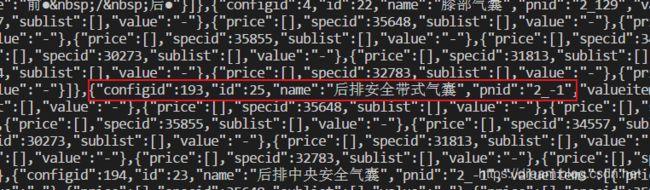
对比一下原来数据,发现问题不大,完成任务。
入库操作
剩下的步骤就是数据持久化了,数据拿到之后,其他的都是比较简单的,希望你可以直接搞定。
小扩展:格式化JS
碰到这种JS,直接找到格式化工具处理它
http://tool.oschina.net/codeformat/js/
格式完成之后,代码具备一定的阅读能力
思路汇总
汽车之家用CSS隐藏了部分真实的字体,在解决的过程中,需要首先针对class去查找,当找到JS位置的时候,必须要搞定它的加密规则,顺着规则之后,只需要完成基本的key、value替换就可以拿到真实的数据了。
关注公众账号:非本科程序员
关注之后,发送【汽车】获取源码
