mysql innodb 数据安全性分析
影响数据安全的几个参数
log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行.该模式下,在事务提交的时候,不会主动触发写入磁盘的操作
log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行.该模式下,在事务提交的时候,不会主动触发写入磁盘的操作
1
每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去
mysql服务崩溃,不会丢失数据
2
每次事务提交时MySQL都会把log buffer的数据写入log file.但是flush(刷到磁盘)操作并不会同时进行
MySQL会每秒执行一次 flush(刷到磁盘)操作
MySQL会每秒执行一次 flush(刷到磁盘)操作
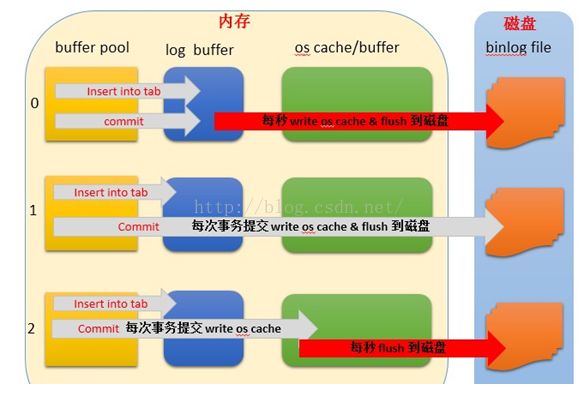
sync_binlog
0
像操作系统刷其他文件的机制一样,MySQL不会同步到磁盘中去而是依赖操作系统来刷新binary log。
像操作系统刷其他文件的机制一样,MySQL不会同步到磁盘中去而是依赖操作系统来刷新binary log。
n ,n>0
MySQL 在每写 N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
MySQL 在每写 N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
1
最安全,每次写binary log 都写入到磁盘
最安全,每次写binary log 都写入到磁盘
innodb_support_xa
innodb_support_xa=true
此时MySQL首先要求innodb prepare,对应的redolog 将写入log buffer;如果有其他的引擎,其他引擎也需要做事务提交的prepare,然后MySQL server将binlog将写入;并通知各事务引擎真正commit;InnoDB将commit标志写入,完成真正的提交,响应应用程序为提交成功。
innodb_support_xa=false
redolog和binlog将无法同步,可能存在事务在主库提交,但是没有记录到binlog的情况。这样也有可能造成事务数据的丢失。
字典
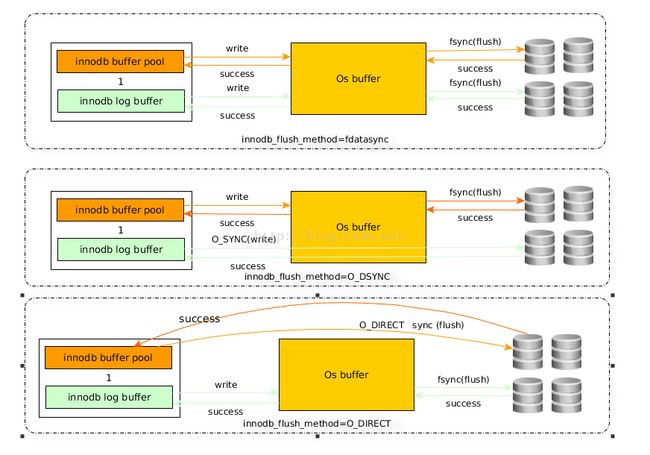
fdatasync
日志文件和数据文件写入后在进行文件刷新时:调用fsync()系统调用
O_DSYNC
打开日志文件是带上0_DSYNC标志;数据文件写入后在进行文件刷新时:调用fsync()系统调用
O_DIRECT
日志文件和数据文件写入后在进行文件刷新时:调用fsync()系统调用
打开数据文件时使用参数O_DIRECT
详细差别见下图:

mysql 事务日志 和binlog 如何协同工作
ib_logfile是InnoDB的事务日志文件。ib_logfile与bin-log共同控制事务恢复。本文简要说明其写入时机、写入策略, 以及分析系统异常对主从数据一致性的影响。
1、 基本概念
a) ib_logfile文件个数由innodb_log_files_in_group配置决定,若为2,则在datadir目录下有两个文件,命令从0开始,分别为ib_logfile0和ib_logfile1.
b) 文件为顺序写入,当达到最后一个文件末尾时,会从第一个文件开始顺序复用。
c) lsn: Log Sequence Number,是一个递增的整数。 Ib_logfile中的每次写入操作都包含至少1个log,每个log都带有一个lsn。在内存page修复过程中,只有大于page_lsn的log才会被使用。
d) lsn的保存在全局变量log_sys中。递增数值等于每个log的实际内容长度。即如果新增的一个log长度是len,则log_sys->lsn += len.
e) ib_logfile每次写入以512(OS_FILE_LOG_BLOCK_SIZE)字节为单位。实际写入函数 log_group_write_buf (log/log0log.c)
f) 每次写盘后是否flush,由参数innodb_flush_log_at_trx_commit控制。
2、 log_sys介绍
log_sys是一个全局内存结构。以下说明几个成员的意义。
| lsn | 表示已经分配的最后一个lsn的值。 |
| written_to_all_lsn | n表示实际已经写盘的lsn。需要这个值是因为并非每次生成log后就写盘。 |
| flushed_to_disk_lsn | 表示刷到磁盘的lsn。需要这个值是因为并非每次写盘后就flush。 |
| buf | 待写入的内容保存在buf中 |
| buf_size | buf的大小。由配置中innodb_log_buffer_size决定,实际大小为innodb_log_buffer_size /16k * 16k。 |
| buf_next_to_write | buf中下一个要写入磁盘的位置 |
| buf_free | buf中实际内容的最后位置。当buf_free> buf_next_to_write时,说明内存中还有数据未写盘。 |
3、相关更新
用一个简单的更新语句来说明log_sys以及ib_logfile的更新内容的过程。假设我们的更新只涉及到非索引的固定长度字段。
a) 在log_sys->buf中写入undo log。 对于一个单一的语句,需要先创建一个undolog头。
b) 在log_sys->buf中写入undo log的实际内容。
c) 在log_sys->buf中写入buffer page的更新内容。此处保存了更新的完整信息。
d) 在log_sys->buf中写入启动事务(trx_prepare)的日志
e) 将a~d的所有log内容写入ib_logfile中。
f) 写bin-log
g) 在log_sys->buf中写入事务结束(trx_commit)的日志
h) 将f步骤的log内容写入ib_logfile中。
5、 日志策略与数据安全
ib_logfile和bin-log的作用之一是保证系统异常时的数据安全,可以分析一下上述流程过程中出现数据库异常关闭时数据安全性。从上述流程看到:
1) 在a~d过程中若出现异常关闭,由于没有写入到磁盘中,因此整个事务放弃;
2) 若在e刚完成时出现异常关闭,虽然事务内容已经写盘,但没有提交。在重启恢复的时候,发现这个事务还没有提交,逻辑上整个事务放弃。 (重启日志中会有Found 1 prepared transaction(s) in InnoDB, rollback xid…字样)。
3) 在f或g完成后出现异常关闭,bin-log写入成功后,则异常重启后能够根据bin-log恢复事务的修改。(重启日志中会有Found 1 prepared transaction(s) in InnoDB, commit xid…字样)。
4) 在h完成后出现异常关闭,由于事务日志完整,因此事务能够正常恢复。
6、 日志策略与主从同步
主从同步关心的问题是
1) 会不会由于主库能够根据ib_logfile恢复数据,而由于bin-log没写导致从库同步时少了这个事务?
2) 或者反之,bin-log写成功,而ib_logfile没有写完,导致从库执行事务,而主库不执行?
先来看控制log写入的主要流程
源码sql/handler.cc:
| ha_commit_trans{ … if ((err= ht->prepare(ht, thd, all))) —-a)
… tc_log->log_xid(thd, xid) —–b) … error=ha_commit_one_phase(thd, all) —c) … } |
说明:可以看到, InnoDB的log分成两段更新,前提是开启bin-log。(条件是有超过1个引擎需要更新日志,而bin-log也是引擎之一,因此至少两个)。
从上面的分析流程可以看到
☆ 假设在阶段a)结束之后程序异常, 此时没有写入bin-log。 则从库不会同步这个事务。 主库上,在重启之后,从恢复日志中这个事务没有trx_commit,因此会被回滚。 逻辑上主从库都不会执行这个事务。
☆ 假设在阶段b)结束后程序异常,此时bin-log已经写入,则从库会同步这个事务。 主库上,根据恢复日志和bin-log,也能够正常恢复此事务。
也就是说,若bin-log写入完成,则主从库都会正常完成事务;bin-log没有写入,则主从库都完成事务。不会出现主从不一致的问题。
这种协同工作的前提条件是:假设写入文件前提是都能持久化到硬盘:由于innodb_flush_log_at_trx_commit和sync_binlog 参数设置,实际情况可能不是这个样子
数据丢失的场景
redo log 因为innodb_flush_log_at_trx_commit设置成非1可能会存在redo log数据丢失binlog 因为sync_binlog设置非1参数也存在binlog数据丢失
innodb_support_xa 没有设置两阶段事务提交也影响事务一致性
mysql的主从复制延迟也可能导致数据丢失
由于redo log和binlog都不能保证按上述时序持久化到硬盘,因此存在两种数据丢失情况
引擎层提交了,但binlog没写入,备库丢事务;
启用半同步并设置超时时间为无线大(999999999)可以规避
保证备机能够接收到binlog
sync_binlog=1 进行规避
保证本机binlog落地
引擎层没有prepare,但binlog写入了,主库丢事务。
innodb_flush_log_at_trx_commit = 1 进行规避
最理想配置
innodb_support_xa=ONinnodb_flush_log_at_trx_commit = 1
sync_binlog=1
set global rpl_semi_sync_master_timeout = 999999999;
set global rpl_semi_sync_master_enabled=on;
理论上该种模式就不会导致数据丢失,mysql在恢复是会根据binlog进行完整恢复
启用半同步并设置超时时间为无线大(999999999)保证主备强一致性
这个当备机挂掉后,主机会卡死
参考文档:
MySQL · 引擎特性 · InnoDB undo log 漫游
MySQL · 引擎特性 · InnoDB redo log漫游
MySQL · 引擎特性 · InnoDB 崩溃恢复过程
MySQL日志——Undo | Redo
undo log与redo log原理分析
MySQL数据库丢失数据场景分析(II)
MySQL Innodb日志机制深入分析
MySQL数据库丢失数据场景分析(I)
讨论MySQL丢失数据的几种情况
MySQL数据丢失以及主从不一致情况