HBase-HFile分析
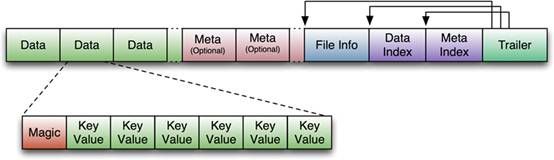
HFile的整体结构图如下:

整个HFile分四部分:
1.可以被迭代器扫描的部分,如数据块
2.不被迭代器扫描到的部分,如中间层索引
3.直接加载到内容的部分,如根索引,文件信息
4.尾部文件块部分,通过尾文件块找到根索引,再由索引定位中间索引以及叶索引,最后找到需要的数据。
需要注意的是第三点中,直接被加载到内存的部分,如根索引,文件信息,这部分的内容对于一个正确的HFile实现来说就是这样做的,如HFileReaderv2,但如果是自己实现一个读取类的话,也可以根据需要不遵守这个原则。
HFile在读取时,首先定位到尾文件块,这个大小是固定的212字节,之后通过尾文件块再找到文件信息块,元数据索引块,根数据索引块。之后使用这些索引块再去查找最终的数据,横向图如下:
HFile中包含各种数据块:
| 文件块类型 | 魔术头 |
| 数据块 | DATABLK* |
| 编码的数据块(如使用DIFF编码) | DATABLKE |
| 叶索引块 | IDXLEAF2 |
| 布隆过滤器块 | BLMFBLK2 |
| 元数据块 | METABLKc |
| 中间索引块 | IDXINTE2 |
| 根索引块(数据索引,元数据索引) | IDXROOT2 |
| 文件信息块 | FILEINF2 |
| 通用的布隆过滤器元数据块索引 | BLMFMET2 |
| 布隆过滤器删除的元数据块索引 | DFBLMET2 |
| 尾文件引块 | TRABLK"$ |
| 索引块(版本1中使用) | IDXBLK)+ |
文件块分两种,左边的是未包含checksum的格式,右边是使用了checksum的格式

其中蓝色的部分是数据,而黄色的部分是文件头,它对于每种类型的文件块都是一样的(尾文件块除外)
数据内容有各种编码方式,同时数据内容是可被压缩的
压缩类型:
NONE、GZ、LZ4、LZO、SNAPPY
压缩都是针对数据内容的,简单的可分为有压缩和无压缩
数据编码类型:
NONE、PREFIX、DIFF、FAST_DIFF
数据编码也是针对数据内容的,并发压缩方式,而是内容的存储方式
checksum类型:
CRC32, CRC32C, NULL
checksum计算指定为数(默认16K)的数据做一次校验和,校验和放在另一个文件中以.crc结尾,为了提升效率可以将这个校验和放到HFile中在数据块中的末尾,这样读取的时候就不用读.crc文件了,可以提升效率。不过.crc文件还是会生成这是hadoop的api生成的
综合有无压缩算法,是否在HFile中生成checksum,一共有4种情况:
1.在HFile中包含checksum,数据无压缩
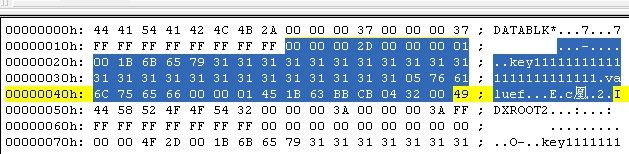
这里显示的压缩数据是3B(59字节),未压缩数据是37(55字节),前一个数据块偏移量是FFFF....,之后会比无checksum多9个字节的内容。分别是
1字节的checksumtype(01),在支持block checksum中,表示checksum的类型
4字节的bytePerCheckSum(00 00 40 00也就是16K),多少字节的数据做一次checksum
SizeDataOnDisk(00 00 00 58) 记录了block在disk中的数据大小,不包括checksumChunk
高亮标注的部分是数据内容(包含了CRC32部分)
可以看到,未压缩的55字节就是纯数据,而压缩的数据是55字节+CRC32(4字节),所以一共59字节

2.HFile中不包含checksum,数据无压缩
高亮的部分是纯数据,显示的是37(55字节),可以看到压缩的数据值和未压缩的数据值是一样的,都是37(55字节)
3.HFile中包含了checksum,数据有压缩
高亮的部分是纯数据,显示的压缩数据是39(57字节),未压缩的数据是37(55字节),之后是上一个数据块偏移量FFFF...,checksum类型(01),bytePerCheckSum(00 00 40 00也就是16K),SizeDataOnDisk(00 00 00 56),高亮显示的是压缩后的数据,包含了checksum。
这里的压缩数据长度就是整个数据长度(包含CRC部分),而未压缩数据部分是37(55个字节),跟上面两种情况的长度是一样的,所以这个数据长度部分就是数据解压缩后原始数据的长度55个字节。

4.HFile中未包含checksum,数据有压缩
高亮部分显示的是压缩后的数据部分,压缩的数据长度34(52字节),未压缩的数据长度37(55字节),跟上面情况一样,未压缩的数据就是原始数据长度(数据解压缩后的长度)
数据块和编码的数据块格式如下:
文件块头部分就是8个字节的魔术头,4个字节的压缩长度,4个字节的未压缩长度,8个字节的上一个块偏移量(如果是checksum类型则会多一些内容)
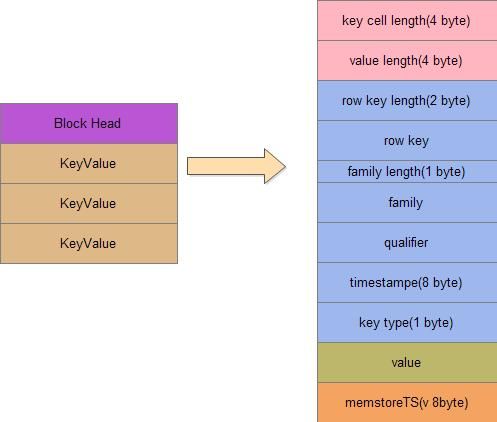
一个KeyCell由下面字段组成:
1.row key的长度
2.row key
3.family 长度
4.family
5.qualifier
6.timestampe
7.key type
KeyValue的一张横向图如下:

key type类型如下:
| 类型 | 值 |
| Minimum | 0 |
| Put | 4 |
| Delete | 8 |
| DeleteColumn | 12 |
| DeleteFamily | 14 |
| Maximum | 255 |
memstoreTS是一个变长8字节,是否有memstoreTS这个标记为是在FileInfo块中记录的,如果没有这个标记为,则memstoreTS长度为0,也就是不会生成这个字段。
其中变成算法的写入实现类是 org.apache.hadoop.io.WritableUtils#writeVLong()
读取实现是 org.apache.hadoop.io.WritableUtils#readVLong()
从上面的定义可以得到:
1.rowKey的长度不能大于0x7fff(32767),即32K,且rowkey不能为null
2.family(列族)的长度不能大于0x7f(127)
3.qualify(限定符)的长度不能大于(0x7fffffff(2147483647) – row长度 – family长度)
4.value的长度不能大于0x7fffffff(2147483647),即2G,且value不能为null
叶索引和中间索引格式如下:
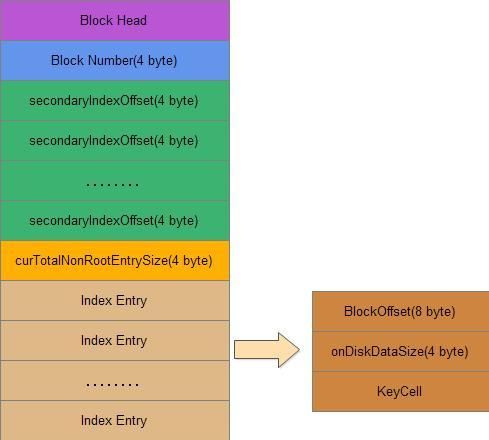
文件块头部分就是8个字节的魔术头,4个字节的压缩长度,4个字节的未压缩长度,8个字节的上一个块偏移量(如果是checksum类型则会多一些内容),索引块字段内容:
1.Block Number: 索引的个数
2.secondaryIndexOffset:每一个secondary index offset都表示一个index enry在索引块中的偏移量(相对于第一个index entry),这是用作二分查找使用的,可以快速定位一个index entry。
3.curTotalNonRootEntrySize:所有的index entry在磁盘中的总大小
4.Index Entry:一个具体的索引条目,包含三部分
BlockOffset 引用的block在文件中的偏移量
onDiskDataSize block快在磁盘中的大小
KeyCell 一个keycell格式,参考上面的数据快和编码数据块中的key cell格式。
secondary offset是用作二级索引查找的,它的原理如下:
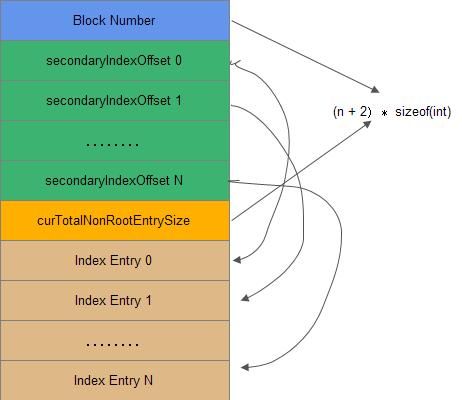
secondary offset 0 的内容就是index entry0的偏移量,secondary offset N的内容就是index entry N的偏移量,index entry前面有n+2个偏移量索引(n个索引+索引数据+index entry大小)
通过索引计算查找的时候需要先跳过前面n+2个记录。
首先定位中间的secondary offset查找中间的index entry,如果就是查找的内容则返回;如果比查找的内容小则查找右半边(n/2到n之间查找),否则查找左半边(0到n/2之间查找)
根索引(单级索引根和多级索引根)格式如下:
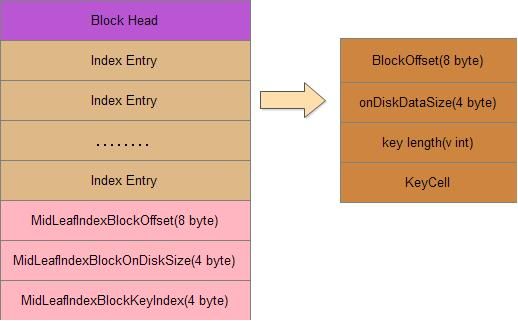
文件块头部分就是8个字节的魔术头,4个字节的压缩长度,4个字节的未压缩长度,8个字节的上一个块偏移量(如果是checksum类型则会多一些内容),索引块字段内容:
和中间索引、叶索引不同,根索引没有二级索引。整个数据内容都是由Index Entry组成的,这里的Index Entry和中间索引格式又不同,它包含了四个部分:
1.BlockOffset 引用的block在文件中的偏移量
2.onDiskDataSize block快在磁盘中的大小
3.key length,这是一个变长的int,它的读取是写入实现类是:
org.apache.hadoop.io.WritableUtils#writeVInt
org.apache.hadoop.io.WritableUtils#readVInt
这两个函数内部又是由org.apache.hadoop.io.WritableUtils#writeVlong实现的
4.KeyCell 一个keycell格式,参考上面的数据快和编码数据块中的key cell格式。
索引文件块最后有一个粉色的部分,如果是单级的根索引就没有这部分,如果是多级的根索引则会包含这部分,这是用来定位中间key的,它的字段含义如下:
1.MidLeafIndexBlockOffset:指向的leaf index chunk的起始偏移量
2.MidLeafIndexBlockOnDiskSize:指向的leaf index chunk的长度
3.MidLeafIndexBlockKeyIndex:在leaf index chunk中的偏移位置
索引的生成和查找过程:
一个索引的生成如下图

每个数据块中包含多个KeyValue,数据块默认为64K,当写入的数据超过64K后,就会生成一个数据块,同时记录下这个数据块的第一个keycell,比如kv1。之后继续写入数据,每当生成一个新的数据块时,也会检查索引数据是否超过了上限(索引块默认为128K),如果索引的内容达到上限则会生成一个索引块。
索引块中就包含若干个keycell,每个key都对应一个数据块,并且这个key也是数据块中的第一个key。
创建过程如下图

这里的L1,L2,L3是一条索引记录Index Entry,每一个索引记录都会指向一个数据块,D就代表一个数据块。当一个索引块生成后,就会往一个标记列表中写入这个索引块的第一个key。比如最后一排有6个索引块,那么标记列表中,就会记录L1,L5,L9,L13,L17,L21这六个索引记录的key。
之后会判断如果标记记录超过指定的大小(索引块大小128K)则会继续生成中间索引。
也就是用之前的六个key再生成索引,假设这次生成了3个索引快,记录这些索引块中的第一个key,也就是L1,L9,L17。
之后发现标记列表又超过了索引块上限,则继续生成中间索引,于是用这三个key继续生成了2个索引块。记录下这两个块的第一个key,L1和L17,这次没有超过索引块上限,于是就生成了根索引(L1和L17),这样整个索引创建过程就完成了。
查找过程

这里是以多级索引为列介绍的,单根索引情况跟多级索引类似。
首先在根索引中查找指定的key,再根据这个index entry再去查找中间索引,注意,这个查找过程是二分查找,尾索引中有根索引的长度,所以可以使用二分查找定位到需要的中间索引的key。
中间索引的查找也是用二分的方式查找的,根据二级索引定位到index entry,然后用这个index entry去查找数据块。
数据块中再挨个遍历,直到找到指定的key,如果没有找到则返回null。
元数据块和版本1索引快:
版本1格式的索引块是用来索引元数据的,在版本2中被根索引替代了。
老版本中使用元数据块存储布隆过滤器信息,新版v2中将布隆过滤器的信息存储到专门的布隆过滤器块中。
元数据块格式如下:
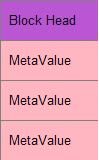
一条元数据包含name和value
meta 的name是字符串,存储在meta 的inex中
meta value是实现Writable接口的序列化的数据
meta块只存储value
比如元数据的key为:mykey123; 元数据的value为:myvalue
元数据key和value跟KeyValue中的key和value没有任何关系
元数据索引格式如下:
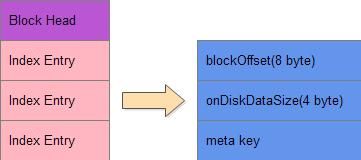
元数据的索引都是单根的,里面包含若干个Index Entry,一个Index Entry又包含三部分:
1.blockOffset:指向的元数据块的偏移量
2.onDiskDataSize:元数据块的大小
3.meta key:存储元数据的key,注意这里是元数据的key,不是keycell
布隆过滤器相关块:
布隆数据块格式如下
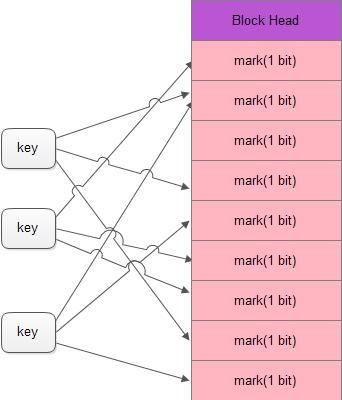
布隆数据块由一个文件头和一个二进制数组组成。
一个key经过若干函数会映射到这个数组的不同位置上,凡是映射到的位置,都将这个比特位置为1,
可以算出1W个key,需要用1.2K大小的数组就可以表示了,100W个key用128K的数组就可以保存下了。
默认是有7个函数映射,不同的key经过映射后,可能会有一些重叠,比如第一个key和第三个key经过某些函数映射后,都将第二个bit位设置为1。
布隆索引块格式如下
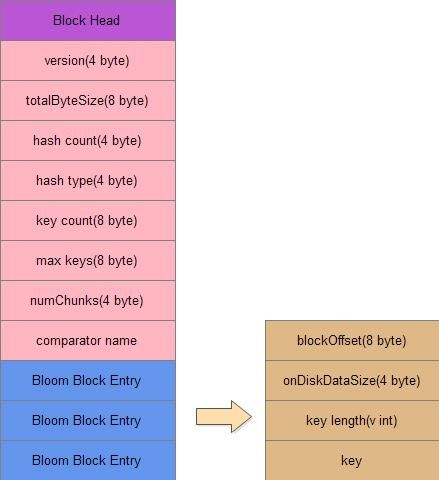
布隆过滤器元数据索引包含两种,通用的布隆过滤器元数据块索引和布隆过滤器删除的元数据块索引
前者就是用来定位查找时使用的布隆过滤器,后一种是用来判断某个key是否被删除了
这两个索引内容是一样,由以下组成:
1.version:版本
2.totalByteSize:表示布隆过滤器数组的大小
3.hash count:hash函数个数,也就是一个key在数组中用几个bit来定位
4.hash type:hash函数类型
5.key count:目前包含的key个数
6.max keys:当前布隆过滤器最多能包含多少个key
7.numChunks:包含的布隆过滤器块数目
8.comparator name:比较实现类的名称
9.一条一条的Bloom Block Entry,由以下组成
blockOffset:布隆数据块在文件中的偏移量
onDiskDataSize:布隆数据块的大小
key length:这是一个变长的int,由WritableUtils#writeVInt()实现
key:具体的key
一个HFile中可以同时存在 通用的布隆过滤器元数据块索引 和 布隆过滤器删除的元数据块索引。
文件信息块格式如下:
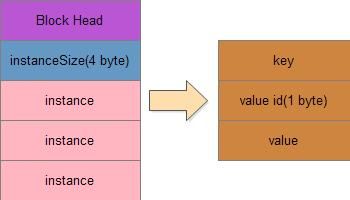
首先是instance个数,之后是若干instance,每个instance由以下组成:
1.key:二进制类型
2.value id:用来标识value的类型
3.value:二进制数组或者是Writable的实现类
这里的key和value是可以自定义的,最后会被HFile写入到文件中的,所以这里可以增加一些用户自定义的key,value信息。
其中有一些“hfile.”开头的key是hbase保留的key,如下:
| key | value | 实际存储的key |
| LASTKEY | 记录HFile中的数据块中的最后一个值的key, 该值如果为空则不进行保存 |
hfile.LASTKEY |
| AVG_KEY_LEN | HFile中的数据块中的所有值key的平均长度 |
hfile.AVG_KEY_LEN |
| AVG_VALUE_LEN | HFile中的数据块中的所有值value的平均长度 | hfile.AVG_VALUE_LEN |
此外memstoreTS,data block的编码类型等信息也会被记录到文件信息块中。
尾文件块格式如下:

尾文件块是用来定位文件信息块,根索引块,元数据根索引块的,它由以下组成:
1.fileInfoOffset:文件信息块的偏移位置
2.loadOnOpenDataOffset:需要被加载到内存中的多个文件块起始偏移量
3.dataIndexCount:根索引中包含的索引数量
4.uncompressedDataIndexSize:所有未压缩的索引总大小
5.metaIndexCount:元数据索引的数目
6.totalUncompressedBytes:所有未压缩的数据块总大小
7.entryCount:KeyValue个数
8.compressionCodec:编码算法
9.numDataIndexLevels:数据索引的级别,也就是当前HFile中是几级索引
10.firstDataBlockOffset:第一个数据块的偏移位置,scan的起始位置
11.lastDataBlockOffset:最后一个数据块之后的第一个byte偏移位置,记录scan的边界
12.comparatorClassName:比较器的类名,不能超过128个字节,默认是
org.apache.hadoop.hbase.KeyValue$KeyComparator
13.version:版本号
配置和API
HFile相关的配置如下:
| 属性 | 含义 | 默认值 |
| hfile.block.cache.size | 分配给HFile/StoreFile 的block cache占最大堆 |
0.25 |
| hbase.hash.type | 哈希函数使用的哈希算法。 可以选择两个值:: murmur (MurmurHash) 和 jenkins (JenkinsHash). 这个哈希是给 bloom filters用的 |
murmur |
| hfile.block.index.cacheonwrite | 写入中间索引时,也写入到缓存中 | false |
| hfile.index.block.max.size | 叶索引,中间索引,根索引块的大小 | 128K |
| hfile.format.version | HFile的版本 | 2 |
| hfile.block.bloom.cacheonwrite | 写入布隆过滤器索引时,也写入到 缓存中 |
false |
| io.storefile.bloom.error.rate | 布隆过滤器的错误比列 |
0.01 |
| io.storefile.bloom.max.fold | 最多映射几个函数 | 7 |
| io.storefile.bloom.max.keys | 最多存储多少key | 12.8亿 |
| io.storefile.bloom.enabled | 是否打开通用的布隆过滤器 | true |
| io.storefile.delete.family.bloom.enabled | 是否e打开删除的布隆过滤器 | tru |
| io.storefile.bloom.block.size | 布隆过滤器块大小 | 128K |
| hbase.regionserver.checksum.verify | 是否开启checksum | false |
相关的api在如下几个包中:
| 包名 | 含义 |
| org.apache.hadoop.hbase.io | 通用的类 |
| org.apache.hadoop.hbase.io.encoding | 编码相关 |
| org.apache.hadoop.hbase.io.hfile | HFile主要操作的类在此包中 |
| org.apache.hadoop.hbase.io.hfile.slab | 缓存相关 |
| org.apache.hadoop.hbase.util | 包含布隆过滤器相关类 |
类图如下:

HFile是最核心的类,通过HFile可以创建出读和写的实现
Reader有两个三个实现类,分别对应HFile的三个版本
通过Reader可以获得BlockIndexReader,这个类负责读取索引
所有的块(数据块,索引块)都被抽象为一个HFileBlock,尾文件块除外叫FixedFileTrailer
这里有一个专门负责读取的接口,FSReader,这个接口的实现负责读取具体的磁盘文件或者HDFS文件,做seek读取等操作,并将读取的块封装为HFileBlock。
此外这个接口会生成一个迭代器BlockIterator,这个迭代器的负责读取一个个的快,生成HFileBlock
Reader接口实现还会创建HFileScanner,这个也是一个接口,有各种版本的Scanner实现,这些类负责读取数据块,HFileScanner可以对KeyValue做定位查找(seek操作)
Writer也有三个实现类,分别对应HFile的三个版本
写入相关的API比读取要少很多,这里有一个InlineBlockWriter接口,布隆过滤器,数据索引就实现了这个接口,负责写入相关的数据。数据索引是强制的,也就是只要创建了Writer实现就会有BlockIndexWriter,而布隆过滤器写入类是可选的。
相关操作:
相关操作:
写入到磁盘时的内存dump:

通过这个图可以看到各种块的生成
1.数据块,叶索引,布隆过滤器块
2.中间是元数据块(可以有多个),中间索引块
3.之后是根数据索引块,元数据根索引块,文件信息块,布隆元数据块(可以有多个)
4.最后是尾文件块
对比HFile的整体结构图,更一目了然。
参考:
Hbase官方文档
HFile实现分析
HFile文件格式详解