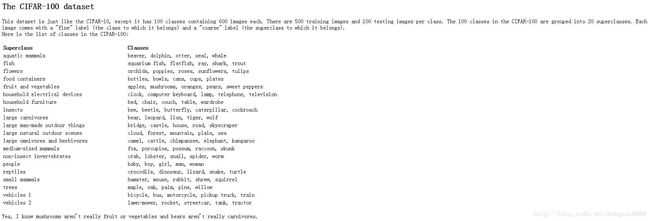
5cifar100数据集的读取-5.1/5.2/5.3TensorFlow读取Cifar100数据集(上/中/下)
http://www.cs.toronto.edu/~kriz/cifar.html
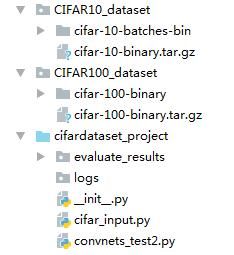
两个文件:cifar_input.py 和 convnets_test.py
只需修改这两个值,完成cifar10和cifar100之间切换
cifar_input.py:
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Routine for decoding the CIFAR-10 binary file format."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
import sys
from six.moves import urllib
import tarfile
# Process images of this size. Note that this differs from the original CIFAR
# image size of 32 x 32. If one alters this number, then the entire model
# architecture will change and any model would need to be retrained.
# IMAGE_SIZE = 24
# Global constants describing the CIFAR-10 data set.
#用于描述CiFar数据集的全局常量
# NUM_CLASSES = 10
IMAGE_SIZE = 32
IMAGE_DEPTH = 3
NUM_CLASSES_CIFAR10 = 10
NUM_CLASSES_CIFAR20 = 20
NUM_CLASSES_CIFAR100 = 100
NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN = 50000
NUM_EXAMPLES_PER_EPOCH_FOR_EVAL = 10000
print('调用我啦...cifar_input...')
#从网址下载数据集存放到data_dir指定的目录下
CIFAR10_DATA_URL = 'http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz'
CIFAR100_DATA_URL = 'http://www.cs.toronto.edu/~kriz/cifar-100-binary.tar.gz'
#从网址下载数据集存放到data_dir指定的目录中
def maybe_download_and_extract(data_dir,data_url=CIFAR10_DATA_URL):
"""下载并解压缩数据集 from Alex's website."""
dest_directory = data_dir #'../CIFAR10_dataset'
DATA_URL = data_url
if not os.path.exists(dest_directory):
os.makedirs(dest_directory)
filename = DATA_URL.split('/')[-1] #'cifar-10-binary.tar.gz'
filepath = os.path.join(dest_directory, filename)#'../CIFAR10_dataset\\cifar-10-binary.tar.gz'
if not os.path.exists(filepath):
def _progress(count, block_size, total_size):
sys.stdout.write('\r>> Downloading %s %.1f%%' % (filename,
float(count * block_size) / float(total_size) * 100.0))
sys.stdout.flush()
filepath, _ = urllib.request.urlretrieve(DATA_URL, filepath, _progress)
print()
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
if data_url== CIFAR10_DATA_URL:
extracted_dir_path = os.path.join(dest_directory,'cifar-10-batches-bin') # '../CIFAR10_dataset\\cifar-10-batches-bin'
else :
extracted_dir_path = os.path.join(dest_directory, 'cifar-100-binary') # '../CIFAR10_dataset\\cifar-10-batches-bin'
if not os.path.exists(extracted_dir_path):
tarfile.open(filepath, 'r:gz').extractall(dest_directory)
def read_cifar10(filename_queue,coarse_or_fine=None):
"""Reads and parses examples from CIFAR10 data files.
Recommendation: if you want N-way read parallelism, call this function
N times. This will give you N independent Readers reading different
files & positions within those files, which will give better mixing of
examples.
Args:
filename_queue: A queue of strings with the filenames to read from.
Returns:
An object representing a single example, with the following fields:
height: number of rows in the result (32)
width: number of columns in the result (32)
depth: number of color channels in the result (3)
key: a scalar string Tensor describing the filename & record number
for this example.
label: an int32 Tensor with the label in the range 0..9.
uint8image: a [height, width, depth] uint8 Tensor with the image data
"""
class CIFAR10Record(object):
pass
result = CIFAR10Record()
# Dimensions of the images in the CIFAR-10 dataset.
# See http://www.cs.toronto.edu/~kriz/cifar.html for a description of the
# input format.
#cifar10 binary中的样本记录:3072=32x32x3
#<1 x label><3072 x pixel>
#...
#<1 x label><3072 x pixel>
# 类型标签字节数
label_bytes = 1 # 2 for CIFAR-100
result.height = 32
result.width = 32
result.depth = 3
#图像字节数
image_bytes = result.height * result.width * result.depth
# Every record consists of a label followed by the image, with a
# fixed number of bytes for each.
# 每一条样本记录由 标签 + 图像 组成,其字节数是固定的。
record_bytes = label_bytes + image_bytes
# Read a record, getting filenames from the filename_queue. No
# header or footer in the CIFAR-10 format, so we leave header_bytes
# and footer_bytes at their default of 0.
# 创建一个固定长度记录读取器,读取一个样本记录的所有字节(label_bytes + image_bytes)
# 由于cifar10中的记录没有header_bytes 和 footer_bytes,所以设置为0
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes,header_bytes=0,footer_bytes=0)
# 调用读取器对象的read 方法返回一条记录
result.key, value = reader.read(filename_queue)
# Convert from a string to a vector of uint8 that is record_bytes long.
#将一个字节组成的string类型的记录转换为长度为record_bytes,类型为unit8的一个数字向量
record_bytes = tf.decode_raw(value, tf.uint8)
# The first bytes represent the label, which we convert from uint8->int32.
# 将一个字节代表了标签,我们把它从unit8转换为int32.
result.label = tf.cast(
tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32)
# The remaining bytes after the label represent the image, which we reshape
# from [depth * height * width] to [depth, height, width].
# 剩余的所有字节都是图像数据,把他从unit8转换为int32
# 转为三维张量[depth,height,width]
depth_major = tf.reshape(
tf.strided_slice(record_bytes, [label_bytes],
[label_bytes + image_bytes]),
[result.depth, result.height, result.width])
# Convert from [depth, height, width] to [height, width, depth].
# 把图像的空间位置和深度位置顺序由[depth, height, width] 转换成[height, width, depth]
result.uint8image = tf.transpose(depth_major, [1, 2, 0])
return result
def read_cifar100(filename_queue,coarse_or_fine='fine'):
"""Reads and parses examples from CIFAR100 data files.
Recommendation: if you want N-way read parallelism, call this function
N times. This will give you N independent Readers reading different
files & positions within those files, which will give better mixing of
examples.
Args:
filename_queue: A queue of strings with the filenames to read from.
Returns:
An object representing a single example, with the following fields:
height: number of rows in the result (32)
width: number of columns in the result (32)
depth: number of color channels in the result (3)
key: a scalar string Tensor describing the filename & record number
for this example.
label: an int32 Tensor with the label in the range 0..9.
uint8image: a [height, width, depth] uint8 Tensor with the image data
"""
class CIFAR100Record(object):
pass
result = CIFAR100Record()
result.height = 32
result.width = 32
result.depth = 3
# cifar100中每个样本记录都有两个类别标签,每一个字节是粗略分类标签,
# 第二个字节是精细分类标签:<1 x coarse label><1 x fine label><3072 x pixel>
coarse_label_bytes = 1
fine_label_bytes = 1
#图像字节数
image_bytes = result.height * result.width * result.depth
# 每一条样本记录由 标签 + 图像 组成,其字节数是固定的。
record_bytes = coarse_label_bytes + fine_label_bytes + image_bytes
# 创建一个固定长度记录读取器,读取一个样本记录的所有字节(label_bytes + image_bytes)
# 由于cifar100中的记录没有header_bytes 和 footer_bytes,所以设置为0
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes,header_bytes=0,footer_bytes=0)
# 调用读取器对象的read 方法返回一条记录
result.key, value = reader.read(filename_queue)
#将一系列字节组成的string类型的记录转换为长度为record_bytes,类型为unit8的一个数字向量
record_bytes = tf.decode_raw(value, tf.uint8)
# 将一个字节代表了粗分类标签,我们把它从unit8转换为int32.
coarse_label = tf.cast(tf.strided_slice(record_bytes, [0], [coarse_label_bytes]), tf.int32)
# 将二个字节代表了细分类标签,我们把它从unit8转换为int32.
fine_label = tf.cast(tf.strided_slice(record_bytes, [coarse_label_bytes], [coarse_label_bytes + fine_label_bytes]), tf.int32)
if coarse_or_fine == 'fine':
result.label = fine_label #100个精细分类标签
else:
result.label = coarse_label #100个粗略分类标签
# 剩余的所有字节都是图像数据,把他从一维张量[depth * height * width]
# 转为三维张量[depth,height,width]
depth_major = tf.reshape(
tf.strided_slice(record_bytes, [coarse_label_bytes + fine_label_bytes],
[coarse_label_bytes + fine_label_bytes + image_bytes]),
[result.depth, result.height, result.width])
# 把图像的空间位置和深度位置顺序由[depth, height, width] 转换成[height, width, depth]
result.uint8image = tf.transpose(depth_major, [1, 2, 0])
return result
def _generate_image_and_label_batch(image, label, min_queue_examples,
batch_size, shuffle):
"""Construct a queued batch of images and labels.
Args:
image: 3-D Tensor of [height, width, 3] of type.float32.
label: 1-D Tensor of type.int32
min_queue_examples: int32, minimum number of samples to retain
in the queue that provides of batches of examples.
batch_size: Number of images per batch.
shuffle: boolean indicating whether to use a shuffling queue.
Returns:
images: Images. 4D tensor of [batch_size, height, width, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
# Create a queue that shuffles the examples, and then
# read 'batch_size' images + labels from the example queue.
num_preprocess_threads = 16
if shuffle:
images, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size,
min_after_dequeue=min_queue_examples)
else:
images, label_batch = tf.train.batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size)
# Display the training images in the visualizer.
tf.summary.image('images', images)
return images, tf.reshape(label_batch, [batch_size])
def distorted_inputs(cifar10or20or100,data_dir, batch_size):
"""使用Reader ops 构造distorted input 用于CIFAR的训练
输入参数:
cifar10or20or100:指定要读取的数据集是cifar10 还是细分类的cifar100 ,或者粗分类的cifar100
data_dir: 指向CIFAR-10 或者 CIFAR-100 数据集的目录
batch_size: 每个批次的图像数量
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
#判断是读取cifar10 还是 cifar100(cifar100可分为20类或100类)
if cifar10or20or100 == 10:
filenames = [os.path.join(data_dir,'data_batch_%d.bin' % i) for i in xrange(1,6)]
read_cifar = read_cifar10
coarse_or_fine = None
if cifar10or20or100 == 20:
filenames = [os.path.join(data_dir,'train.bin')]
read_cifar = read_cifar100
coarse_or_fine = 'coarse'
if cifar10or20or100 == 100:
filenames = [os.path.join(data_dir, 'train.bin')]
read_cifar = read_cifar100
coarse_or_fine = 'fine'
#检查文件是否存在
for f in filenames:
if not tf.gfile.Exists(f):
raise ValueError('Failed to find file: ' + f)
# 根据文件名列表创建一个文件名队列
filename_queue = tf.train.string_input_producer(filenames)
# 从文件名队列的文件中读取样本
read_input = read_cifar(filename_queue)
# 将无符号8位图像数据转换成float32位
casted_image = tf.cast(read_input.uint8image, tf.float32)
# 要生成的目标图像的大小,在这里与原图像的尺寸保持一致
height = IMAGE_SIZE
width = IMAGE_SIZE
#为图像添加padding = 4,图像尺寸变为[32+4,32+4],为后面的随机裁切留出位置
padded_image = tf.image.resize_image_with_crop_or_pad(casted_image,width+4,height+4)
#下面的这些操作为原始图像添加了很多不同的distortions,扩增了原始训练数据集
# 在[36,36]大小的图像中随机裁切出[height,width]即[32,,32]的图像区域
distorted_image = tf.random_crop(padded_image, [height, width, 3])
# 将图像进行随机的水平翻转(左边和右边的像素对调)
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 下面这两个操作不满足交换律,即 亮度调整+对比度调整 和 对比度调整+亮度调整
# 产生的结果是不一样的,你可以采取随机的顺序来执行这两个操作
distorted_image = tf.image.random_brightness(distorted_image,max_delta=63)
distorted_image = tf.image.random_contrast(distorted_image,lower=0.2, upper=1.8)
# 数据集标准化操作:减去均值+方差归一化(divide by the variance of the pixels)
float_image = tf.image.per_image_standardization(distorted_image)
# 设置张量的形状
float_image.set_shape([height, width, 3])
read_input.label.set_shape([1])
# 确保: the random shuffling has good mixing properties.
min_fraction_of_examples_in_queue = 0.4
min_queue_examples = int(NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN *
min_fraction_of_examples_in_queue)
print ('Filling queue with %d CIFAR images before starting to train. '
'This will take a few minutes.' % min_queue_examples)
# Generate a batch of images and labels by building up a queue of examples.
return _generate_image_and_label_batch(float_image, read_input.label,
min_queue_examples, batch_size,
shuffle=True)
def inputs(cifar10or20or100, eval_data, data_dir, batch_size):
"""使用Reader ops 读取数据集,用于CIFAR的评估
输入参数:
cifar10or20or100:指定要读取的数据集是cifar10 还是细分类的cifar100 ,或者粗分类的cifar100
eval_data: True or False ,指示要读取的是训练集还是测试集
data_dir: 指向CIFAR-10 或者 CIFAR-100 数据集的目录
batch_size: 每个批次的图像数量
返回:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
#判断是读取cifar10 还是 cifar100(cifar100可分为20类或100类)
if cifar10or20or100 == 10:
read_cifar = read_cifar10
coarse_or_fine = None
if not eval_data:
filenames = [os.path.join(data_dir,'data_batch_%d.bin' % i) for i in xrange(1,6)]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
else:
filenames = [os.path.join(data_dir,'test_batch.bin')]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_EVAL
if cifar10or20or100 == 20 or cifar10or20or100 == 100:
read_cifar = read_cifar100
if not eval_data:
filenames = [os.path.join(data_dir,'train.bin')]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
else:
filenames = [os.path.join(data_dir,'test.bin')]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_EVAL
if cifar10or20or100 == 100:
coarse_or_fine = 'fine'
if cifar10or20or100 == 20:
coarse_or_fine = 'coarse'
for f in filenames:
if not tf.gfile.Exists(f):
raise ValueError('Failed to find file: ' + f)
# 根据文件名列表创建一个文件名队列
filename_queue = tf.train.string_input_producer(filenames)
# 从文件名队列的文件中读取样本
read_input = read_cifar(filename_queue, coarse_or_fine = coarse_or_fine)
# 将无符号8位图像数据转换成float32位
casted_image = tf.cast(read_input.uint8image, tf.float32)
# 要生成的目标图像的大小,在这里与原图像的尺寸保持一致
height = IMAGE_SIZE
width = IMAGE_SIZE
# 用于评估过程的图像数据预处理
# Crop the central [height, width] of the image.(其实这里并未发生裁剪)
resized_image = tf.image.resize_image_with_crop_or_pad(casted_image,width,height)
#数据集标准化操作:减去均值 + 方差归一化
float_image = tf.image.per_image_standardization(resized_image)
# 设置数据集中张量的形状
float_image.set_shape([height, width, 3])
read_input.label.set_shape([1])
# Ensure that the random shuffling has good mixing properties.
min_fraction_of_examples_in_queue = 0.4
min_queue_examples = int(num_examples_per_epoch *
min_fraction_of_examples_in_queue)
# Generate a batch of images and labels by building up a queue of examples.
# 通过构造样本队列(a queue of examples)产生一个批次的图像和标签
return _generate_image_and_label_batch(float_image, read_input.label,
min_queue_examples, batch_size,
shuffle=False)
convnets_test.py:
#-*- coding:utf-8 -*-
#实现简单卷积神经网络对MNIST数据集进行分类:conv2d + activation + pool + fc
import csv
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import sys
from six.moves import urllib
import tarfile
import cifar_input
import numpy as np
# 设置算法超参数
learning_rate_init = 0.001
training_epochs = 2
batch_size = 100
display_step = 10
conv1_kernel_num = 64
conv2_kernel_num = 64
fc1_units_num = 512
fc2_units_num = 512
activation_func = tf.nn.relu
activation_name = 'relu'
l2loss_ratio = 0.05
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
#数据集中输入图像的参数
# dataset_dir_cifar10 = '../CIFAR10_dataset/cifar-10-batches-bin'
# dataset_dir_cifar100 = '../CIFAR100_dataset/cifar-100-binary'
dataset_dir_cifar10 = '../CIFAR10_dataset'
dataset_dir_cifar100 = '../CIFAR100_dataset'
num_examples_per_epoch_for_train = cifar_input.NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN#50000
num_examples_per_epoch_for_eval = cifar_input.NUM_EXAMPLES_PER_EPOCH_FOR_EVAL#10000
image_size = cifar_input.IMAGE_SIZE
image_channel = cifar_input.IMAGE_DEPTH
cifar10_data_url = cifar_input.CIFAR10_DATA_URL
cifar100_data_url = cifar_input.CIFAR100_DATA_URL
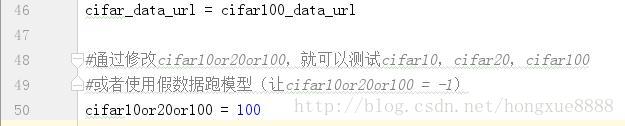
cifar_data_url = cifar100_data_url
#通过修改cifar10or20or100,就可以测试cifar10,cifar20,cifar100
#或者使用假数据跑模型(让cifar10or20or100 = -1)
cifar10or20or100 = 100
if cifar10or20or100 == 10:
n_classes = cifar_input.NUM_CLASSES_CIFAR10
dataset_dir = dataset_dir_cifar10
if cifar10or20or100 == 20:
n_classes = cifar_input.NUM_CLASSES_CIFAR20
dataset_dir = dataset_dir_cifar100
if cifar10or20or100 == 100:
n_classes = cifar_input.NUM_CLASSES_CIFAR100
dataset_dir = dataset_dir_cifar100
#从网址下载数据集存放到data_dir指定的目录中
# def maybe_download_and_extract(data_dir):
# """下载并解压缩数据集 from Alex's website."""
# dest_directory = data_dir
# DATA_URL = 'http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz'
# if not os.path.exists(dest_directory):
# os.makedirs(dest_directory)
# filename = DATA_URL.split('/')[-1] #'cifar-10-binary.tar.gz'
# filepath = os.path.join(dest_directory, filename)#'../CIFAR10_dataset\\cifar-10-binary.tar.gz'
# if not os.path.exists(filepath):
# def _progress(count, block_size, total_size):
# sys.stdout.write('\r>> Downloading %s %.1f%%' % (filename,
# float(count * block_size) / float(total_size) * 100.0))
# sys.stdout.flush()
# filepath, _ = urllib.request.urlretrieve(DATA_URL, filepath, _progress)
# print()
# statinfo = os.stat(filepath)
# print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
#
# extracted_dir_path = os.path.join(dest_directory, 'cifar-10-batches-bin')#'../CIFAR10_dataset\\cifar-10-batches-bin'
# if not os.path.exists(extracted_dir_path):
# tarfile.open(filepath, 'r:gz').extractall(dest_directory)
def get_distorted_train_batch(cifar10or20or100,data_dir,batch_size):
"""Construct distorted input for CIFAR training using the Reader ops.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
Raises:
ValueError: If no data_dir
"""
if not data_dir:
raise ValueError('Please supply a data_dir')
if cifar10or20or100==10:
data_dir = os.path.join(data_dir, 'cifar-10-batches-bin')
else :
data_dir = os.path.join(data_dir, 'cifar-100-binary')
images, labels = cifar_input.distorted_inputs(cifar10or20or100=cifar10or20or100,data_dir=data_dir,batch_size=batch_size)
return images,labels
def get_undistorted_eval_batch(cifar10or20or100,data_dir,eval_data, batch_size):
"""Construct input for CIFAR evaluation using the Reader ops.
Args:
eval_data: bool, indicating if one should use the train or eval data set.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
Raises:
ValueError: If no data_dir
"""
if not data_dir:
raise ValueError('Please supply a data_dir')
if cifar10or20or100==10:
data_dir = os.path.join(data_dir, 'cifar-10-batches-bin')
else :
data_dir = os.path.join(data_dir, 'cifar-100-binary')
images, labels = cifar_input.inputs(cifar10or20or100=cifar10or20or100,eval_data=eval_data,data_dir=data_dir,batch_size=batch_size)
return images,labels
#根据指定的维数返回初始化好的指定名称的权重 Variable
def WeightsVariable(shape, name_str, stddev=0.1):
# initial = tf.random_normal(shape=shape, stddev=stddev, dtype=tf.float32)
initial = tf.truncated_normal(shape=shape, stddev=stddev, dtype=tf.float32)
return tf.Variable(initial, dtype=tf.float32, name=name_str)
#根据指定的维数返回初始化好的指定名称的偏置 Variable
def BiasesVariable(shape, name_str, init_value=0.00001):
initial = tf.constant(init_value, shape=shape)
return tf.Variable(initial, dtype=tf.float32, name=name_str)
# 二维卷积层activation(conv2d+bias)的封装
def Conv2d(x, W, b, stride=1, padding='SAME',activation=tf.nn.relu,act_name='relu'):
with tf.name_scope('conv2d_bias'):
y = tf.nn.conv2d(x, W, strides=[1, stride, stride, 1], padding=padding)
y = tf.nn.bias_add(y, b)
with tf.name_scope(act_name):
y = activation(y)
return y
# 二维池化层pool的封装
def Pool2d(x, pool= tf.nn.max_pool, k=2, stride=2,padding='SAME'):
return pool(x, ksize=[1, k, k, 1], strides=[1, stride, stride, 1], padding=padding)
# 全连接层activate(wx+b)的封装
def FullyConnected(x, W, b, activation=tf.nn.relu, act_name='relu'):
with tf.name_scope('Wx_b'):
y = tf.matmul(x, W)
y = tf.add(y, b)
with tf.name_scope(act_name):
y = activation(y)
return y
#为每一层的激活输出添加汇总节点
def AddActivationSummary(x):
tf.summary.histogram('/activations',x)
tf.summary.scalar('/sparsity',tf.nn.zero_fraction(x))
#为所有损失节点添加(滑动平均)标量汇总操作
def AddLossesSummary(losses):
#计算所有(individual losses)和(total loss)的滑动平均
loss_averages = tf.train.ExponentialMovingAverage(0.9,name='avg')
loss_averages_op = loss_averages.apply(losses)
#为所有individual losses 和 total loss 绑定标量汇总节点
#为所有平滑处理过的individual losses 和 total loss也绑定标量汇总节点
for loss in losses:
#没有平滑过的loss名字后面加上‘(raw)’,平滑以后的loss使用其原来的名称
tf.summary.scalar(loss.op.name + '(raw)',loss)
tf.summary.scalar(loss.op.name + '(avg)',loss_averages.average(loss))
return loss_averages_op
#修改了4处激活函数:Conv2d_1、Conv2d_2、FC1_nonlinear、FC2_nonlinear
def Inference(image_holder):
# 第一个卷积层activate(conv2d + biase)
with tf.name_scope('Conv2d_1'):
# conv1_kernel_num = 64
weights = WeightsVariable(shape=[5, 5, image_channel, conv1_kernel_num],
name_str='weights',stddev=5e-2)
biases = BiasesVariable(shape=[conv1_kernel_num], name_str='biases',init_value=0.0)
conv1_out = Conv2d(image_holder, weights, biases, stride=1, padding='SAME',activation=activation_func,act_name=activation_name)
AddActivationSummary(conv1_out)
# 第一个池化层(pool 2d)
with tf.name_scope('Pool2d_1'):
pool1_out = Pool2d(conv1_out, pool=tf.nn.max_pool, k=3, stride=2,padding='SAME')
# 第二个卷积层activate(conv2d + biase)
with tf.name_scope('Conv2d_2'):
# conv2_kernels_num = 64
weights = WeightsVariable(shape=[5, 5, conv1_kernel_num, conv2_kernel_num], name_str='weights', stddev=5e-2)
biases = BiasesVariable(shape=[conv2_kernel_num], name_str='biases', init_value=0.0)
conv2_out = Conv2d(pool1_out, weights, biases, stride=1, padding='SAME',activation=activation_func,act_name=activation_name)
AddActivationSummary(conv2_out)
# 第二个池化层(pool 2d)
with tf.name_scope('Pool2d_2'):
pool2_out = Pool2d(conv2_out, pool=tf.nn.max_pool, k=3, stride=2, padding='SAME')
#将二维特征图变换为一维特征向量
with tf.name_scope('FeatsReshape'):
features = tf.reshape(pool2_out, [batch_size,-1])
feats_dim = features.get_shape()[1].value
# 第一个全连接层(fully connected layer)
with tf.name_scope('FC1_nonlinear'):
weights = WeightsVariable(shape=[feats_dim, fc1_units_num],name_str='weights',stddev=4e-2)
biases = BiasesVariable(shape=[fc1_units_num], name_str='biases',init_value=0.1)
fc1_out = FullyConnected(features, weights, biases, activation=activation_func,act_name=activation_name)
AddActivationSummary(fc1_out)
with tf.name_scope('L2_loss'):
weight_loss = tf.multiply(tf.nn.l2_loss(weights),l2loss_ratio,name="fc1_weight_loss")
tf.add_to_collection('losses',weight_loss)
# 第二个全连接层(fully connected layer)
with tf.name_scope('FC2_nonlinear'):
weights = WeightsVariable(shape=[fc1_units_num, fc2_units_num],name_str='weights',stddev=4e-2)
biases = BiasesVariable(shape=[fc2_units_num], name_str='biases',init_value=0.1)
fc2_out = FullyConnected(fc1_out, weights, biases, activation=activation_func,act_name=activation_name)
AddActivationSummary(fc2_out)
with tf.name_scope('L2_loss'):
weight_loss = tf.multiply(tf.nn.l2_loss(weights), l2loss_ratio, name="fc2_weight_loss")
tf.add_to_collection('losses', weight_loss)
# 第三个全连接层(fully connected layer)
with tf.name_scope('FC3_linear'):
fc3_units_num = n_classes
weights = WeightsVariable(shape=[fc2_units_num, fc3_units_num],name_str='weights',stddev=1.0/fc2_units_num)
biases = BiasesVariable(shape=[fc3_units_num], name_str='biases',init_value=0.0)
logits = FullyConnected(fc2_out, weights, biases,activation=tf.identity, act_name='linear')
AddActivationSummary(logits)
return logits
def TrainModel():
#调用上面写的函数构造计算图
with tf.Graph().as_default():
# 计算图输入
with tf.name_scope('Inputs'):
image_holder = tf.placeholder(tf.float32, [batch_size, image_size,image_size,image_channel], name='images')
labels_holder = tf.placeholder(tf.int32, [batch_size], name='labels')
# 计算图前向推断过程
with tf.name_scope('Inference'):
logits = Inference(image_holder)
# 定义损失层(loss layer)
with tf.name_scope('Loss'):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels_holder,logits=logits)
cross_entropy_loss = tf.reduce_mean(cross_entropy,name='xentropy_loss')
tf.add_to_collection('losses',cross_entropy_loss)
#总体损失(total loss)= 交叉熵损失 + 所有权重的L2损失
total_loss = tf.add_n(tf.get_collection('losses'),name='total_loss')
average_losses = AddLossesSummary(tf.get_collection('losses') + [total_loss])
# 定义优化训练层(train layer)
with tf.name_scope('Train'):
learning_rate = tf.placeholder(tf.float32)
global_step = tf.Variable(0, name='global_step', trainable=False, dtype=tf.int64)
optimizer = tf.train.RMSPropOptimizer(learning_rate=learning_rate)
# optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,momentum=0.9)
# optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
# optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# optimizer = tf.train.AdagradOptimizer(learning_rate=learning_rate)
# optimizer = tf.train.FtrlOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(total_loss,global_step=global_step)
# 定义模型评估层(evaluate layer)
with tf.name_scope('Evaluate'):
top_K_op = tf.nn.in_top_k(predictions=logits,targets=labels_holder,k=1)
#定义获取训练样本批次的计算节点
with tf.name_scope('GetTrainBatch'):
image_train,labels_train = get_distorted_train_batch(cifar10or20or100=cifar10or20or100,data_dir=dataset_dir,batch_size=batch_size)
# 定义获取测试样本批次的计算节点
with tf.name_scope('GetTestBatch'):
image_test, labels_test = get_undistorted_eval_batch(cifar10or20or100=cifar10or20or100,data_dir=dataset_dir,eval_data=True, batch_size=batch_size)
merged_summaries = tf.summary.merge_all()
# 添加所有变量的初始化节点
init_op = tf.global_variables_initializer()
print('把计算图写入事件文件,在TensorBoard里面查看')
summary_writer = tf.summary.FileWriter(logdir='logs')
summary_writer.add_graph(graph=tf.get_default_graph())
summary_writer.flush()
# 将评估结果保存到文件
results_list = list()
# 写入参数配置
results_list.append(['learning_rate', learning_rate_init,
'training_epochs', training_epochs,
'batch_size', batch_size,
'conv1_kernel_num', conv1_kernel_num,
'conv2_kernel_num', conv2_kernel_num,
'fc1_units_num', fc1_units_num,
'fc2_units_num', fc2_units_num])
results_list.append(['train_step', 'train_loss','train_step', 'train_accuracy'])
with tf.Session() as sess:
sess.run(init_op)
print('===>>>>>>>==开始训练集上训练模型==<<<<<<<=====')
total_batches = int(num_examples_per_epoch_for_train / batch_size)
print('Per batch Size:,',batch_size)
print('Train sample Count Per Epoch:',num_examples_per_epoch_for_train)
print('Total batch Count Per Epoch:', total_batches)
#启动数据读取队列
tf.train.start_queue_runners()
#记录模型被训练的步数
training_step = 0
# 训练指定轮数,每一轮的训练样本总数为:num_examples_per_epoch_for_train
for epoch in range(training_epochs):
#每一轮都要把所有的batch跑一遍
for batch_idx in range(total_batches):
#运行获取训练数据的计算图,取出一个批次数据
images_batch ,labels_batch = sess.run([image_train,labels_train])
#运行优化器训练节点
_,loss_value,avg_losses = sess.run([train_op,total_loss,average_losses],
feed_dict={image_holder:images_batch,
labels_holder:labels_batch,
learning_rate:learning_rate_init})
#每调用一次训练节点,training_step就加1,最终==training_epochs * total_batch
training_step = sess.run(global_step)
#每训练display_step次,计算当前模型的损失和分类准确率
if training_step % display_step == 0:
#运行accuracy节点,计算当前批次的训练样本的准确率
predictions = sess.run([top_K_op],
feed_dict={image_holder:images_batch,
labels_holder:labels_batch})
#当前批次上的预测正确的样本量
batch_accuracy = np.sum(predictions)/batch_size
results_list.append([training_step,loss_value,training_step,batch_accuracy])
print("Training Step:" + str(training_step) +
",Training Loss = " + "{:.6f}".format(loss_value) +
",Training Accuracy = " + "{:.5f}".format(batch_accuracy) )
#运行汇总节点
summaries_str = sess.run(merged_summaries,feed_dict=
{image_holder:images_batch,
labels_holder:labels_batch})
summary_writer.add_summary(summary=summaries_str,global_step=training_step)
summary_writer.flush()
summary_writer.close()
print('训练完毕')
print('===>>>>>>>==开始在测试集上评估模型==<<<<<<<=====')
total_batches = int(num_examples_per_epoch_for_eval / batch_size)
total_examples = total_batches * batch_size
print('Per batch Size:,', batch_size)
print('Test sample Count Per Epoch:', total_examples)
print('Total batch Count Per Epoch:', total_batches)
correct_predicted = 0
for test_step in range(total_batches):
#运行获取测试数据的计算图,取出一个批次测试数据
images_batch,labels_batch = sess.run([image_test,labels_test])
#运行accuracy节点,计算当前批次的测试样本的准确率
predictions = sess.run([top_K_op],
feed_dict={image_holder:images_batch,
labels_holder:labels_batch})
#累计每个批次上的预测正确的样本量
correct_predicted += np.sum(predictions)
accuracy_score = correct_predicted / total_examples
print('---------->Accuracy on Test Examples:',accuracy_score)
results_list.append(['Accuracy on Test Examples:',accuracy_score])
# 将评估结果保存到文件
results_file = open('evaluate_results/evaluate_results.csv', 'w', newline='')
csv_writer = csv.writer(results_file, dialect='excel')
for row in results_list:
csv_writer.writerow(row)
def main(argv=None):
cifar_input.maybe_download_and_extract(data_dir=dataset_dir,data_url=cifar_data_url)
train_dir='/logs'
if tf.gfile.Exists(train_dir):
tf.gfile.DeleteRecursively(train_dir)
tf.gfile.MakeDirs(train_dir)
TrainModel()
if __name__ =='__main__':
tf.app.run()