Kafka

一、Kafka介绍:
` Kafka是一种分布式的、基于发布订阅的消息系统,能够高效并实时的吞吐数据,以及通过分布式集群和复本冗余机制实现数据的安全。
二、Kafka的安装配置:
-
从官网下载安装包 http://kafka.apache.org/downloads
-
上传到1号虚拟机,解压
tar -xvf kafka_2.10-0.10.0.1 -
进入安装目录下的config目录
-
对server.properties进行配置:
broker.id=0 //节点的id log.dirs=/root/kafka_2.10-0.10.0.1/kafka-logs //数据的存储路径 zookeeper.connect=zkp1:2181,zkp2:2181,zkp3:2181//zkp1、zkp2、zkp3是三台虚拟机的名称 delete.topic.enable=true //是否能真正删除主题 advertised.host.name=zkp1 advertised.port=9092//通信端口 -
保存退出后,别忘了在安装目录下创建 kafka-logs目录
cd /root/kafka_2.10-0.10.0.1 mikdir kafka-logs -
配置其他两台虚拟机,更改配置文件的broker.id编号(不重复即可)
-
先启动zookeeper集群
-
再启动kafka集群
进入bin目录
执行:sh kafka-server-start.sh ../config/server.properties
三、Kafka使用:
-
创建自定义的topic
在bin目录下执行:sh kafka-topics.sh --create --zookeeper zkp1:2181 --replication-factor 1 --partitions 1 --topic enbook
注:
副本数量要小于等于节点数量
2. 查看所有的topic
执行:
sh kafka-topics.sh --list --zookeeper zkp1:2181
3.启动producer(启动生产者)
执行:
sh kafka-console-producer.sh --broker-list zkp1:9092,zkp2:9092,zkp3:9092 --topic enbook
4.启动consumer
执行:
sh kafka-console-consumer.sh --zookeeper zkp1:2181,zkp2:2181,zkp3:2181 --topic cnbook --from-beginning
5.可以通过producer和consumer模拟消息的发送和接收
6.删除topic指令:
进入bin目录,执行:
sh kafka-topics.sh --delete --zookeeper zkp1:2181 --topic enbook
可以通过配置 config目录下的 server.properties文件,加入如下的配置:
配置示例:
delete.topic.enable=true
四、Kafka架构

在这个架构图中:
- Producer生产者,生产消息,发布消息到kafka集群的终端或服务。而且生产者只和分区复本的leader交互。
- broker是kafka集群中包含的服务器。他们都是同等级别的,没有主从之分。
- topic主题是每条发送到kafka集群的消息所属的类别。
- partition:是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。
- consumer:从 kafka 集群中消费消息的终端或服务。
- Consumer group:每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
-----创建主题时,分区数一定不能太少,可能会使得某些消费者线程处于闲置状态。
-----在为消费者线程分配分区数时,kafka策略是负载均衡策略,每个线程最低的消费分区数是1个。
即组间数据是共享的,组内数据是竞争的。 - replica:
partition 的副本,保障 partition 的高可用。 - leader:
分区多个复本replica 中的一个角色, producer 和 consumer 只跟 leader 交互。 - follower:
replica 中的一个角色,从 leader 中复制数据。单向的数据同步过程 - controller:
kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 leader failover。
controller进程随机在某台broker启动,作用是leader选举和leader失败恢复。 - zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息。zookeeper做kafka集群的协调服务,监控kroker服务器的状态(临时节点),以及主题相关的信息。
五、Kafka中的Topic和Partition
- 分区物理上是个文件目录,逻辑上是个队列结构满足先进先出的特性
- 分区中每个数据都有一个位置,称此位置为offset(偏移量)。
- 消费者消费到一条数据之后,都会记录下最新的offset,便于下次从正确的位置消费
- 消费者的offset在旧版本的kafka(1.*)是存在zookeeper上,但是这种机制的缺点是频繁的访问zookeeper,为zookeeper带来过高的负载压力,因为zookeeper集群还要服务于其他的框架,比如Hadoop集群,HBase集群,Storm集群。
- 新版本的kafka中offset是由自己管理。通过一个特殊的主题:__consumer_offsets,共50个分区。
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic(主题)。
Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.
Topic在逻辑上可以被认为是一个queue,每条消息都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。
为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
六、Kafka的消息系统语义
概述
在一个分布式发布订阅消息系统中,组成系统的计算机总会由于各自的故障而不能工作。在Kafka中,一个单独的broker,可能会在生产者发送消息到一个topic的时候宕机,或者出现网络故障,从而导致生产者发送消息失败。根据生产者如何处理这样的失败,产生了不通的语义:
至少一次语义(At least once semantics):
如果生产者收到了Kafka broker的确认(acknowledgement,ack),并且生产者的acks配置项设置为all(或-1),这就意味着消息已经被精确一次写入Kafka topic了。然而,如果生产者接收ack超时或者收到了错误,它就会认为消息没有写入Kafka topic而尝试重新发送消息。如果broker恰好在消息已经成功写入Kafka topic后,发送ack前,出了故障,生产者的重试机制就会导致这条消息被写入Kafka两次,从而导致同样的消息会被消费者消费不止一次。每个人都喜欢一个兴高采烈的给予者,但是这种方式会导致重复的工作和错误的结果。
——数据不会丢失,但是可能造成数据的重复处理
至多一次语义(At most once semantics):
如果生产者在ack超时或者返回错误的时候不重试发送消息,那么消息有可能最终并没有写入Kafka topic中,因此也就不会被消费者消费到。但是为了避免重复处理的可能性,我们接受有些消息可能被遗漏处理。
——可能数据丢失
精确一次语义(Exactly once semantics):
即使生产者重试发送消息,也只会让消息被发送给消费者一次。精确一次语义是最令人满意的保证,但也是最难理解的。因为它需要消息系统本身和生产消息的应用程序还有消费消息的应用程序一起合作。比如,在成功消费一条消息后,你又把消费的offset重置到之前的某个offset位置,那么你将收到从那个offset到最新的offset之间的所有消息。这解释了为什么消息系统和客户端程序必须合作来保证精确一次语义。
——数据不丢失,而且不会重复处理
——此语义是最好的语义,基础是至少一次语义。实现的通用思想是为每条数据发送时,分配一个全局唯 一且递增的id,kafka根据此id实现幂等性(是指代码运行多次的结果和运行一次的结果是一样的)操作。
——递增的作用是为了确保数据处理的顺序性。
通过代码来设置消息系统语义
Producer的至多一次:
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"zkp1:9092,zkp2:9092,zkp3:9092");
props.put("acks", 0);
Producer的至少一次:
props.put("acks", all);
Producer的精确一次:
props.put("acks","all");
props.put("enable.idempotence","true");
kafka consumer是默认至多一次,consumer的配置是:
- 设置enable.auto.commit 为 true.
- 设置 auto.commit.interval.ms为一个较小的值.
- consumer不去执行 consumer.commitSync(), 这样, Kafka 会每隔一段时间自动提交offset。
Consumer的至多一次:
props.put("enable.auto.commit", "true");//自动提交 props.put("auto.commit.interval.ms", "101");//自动提交的间隔
Consumer的至少一次:
props.put("enable.auto.commit", "false");
//--处理完成后,用户自己手动提交offset
consumer.commitAsync();
Consumer的精确一次:
props.put("enable.auto.commit", "false");//至少一次的基础上
props.put("processing.guarantee","exact_once");//全局唯一且递增的id
//--处理完成后,用户自己手动提交offset
consumer.commitAsync();
七、Kafka的索引机制
1.概述
· Kafka解决查询效率的手段之一是将数据文件分段,可以配置每个数据文件的最大值,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。
每个log文件默认是1GB生成一个新的Log文件,比如新的log文件中第一条的消息的offset 16933,则此log文件的命名为:000000000000000016933.log,此外,每生成一个log文件,就会生成一个对应的索引(index)文件。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引——Offset与position(Message在数据文件中的绝对位置)的对应关系。
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
索引文件被映射到内存中,所以查找的速度还是很快的。
八、Zero Copy零拷贝技术
` “Zero-copy” describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
zero copy(零复制)是一种特殊形式的内存映射,它允许你将Kernel内存直接映射到设备内存空间上。其实就是设备可以通过直接内存访问(direct memory access,DMA)方式来访问Kernal Space。
kernal把数据从disk读出来,然后把它传输给user级的application,然后application再次把同样的内容再传回给处于kernal级的socket。这种场景下,application实际上只是作为一种低效的中间介质,用来把disk file的data传给socket。
所以,当我们通过网络传输数据时,尽管看起来很简单,但是在OS的内部,这个copy操作要经历四次user mode和kernel mode之间的上下文切换,而数据都被拷贝了四次!
此外,data每次穿过user-kernel boundary,都会被copy,这会消耗cpu,并且占用RAM的带宽。
Zero Copy的具体实现
Zero Copy的模式中,避免了数据在用户空间和内存空间之间的拷贝,从而提高了系统的整体性能。Linux中的sendfile()以及Java NIO中的FileChannel.transferTo()方法都实现了零拷贝的功能,而在Netty中也通过在FileRegion中包装了NIO的FileChannel.transferTo()方法实现了零拷贝。
这样把context switch的次数从4次减少到了2次,同时也把data copy的次数从4次降低到了3次(而且其中只有一次占用了CPU,另外两次由DMA完成)。
真正的零拷贝:
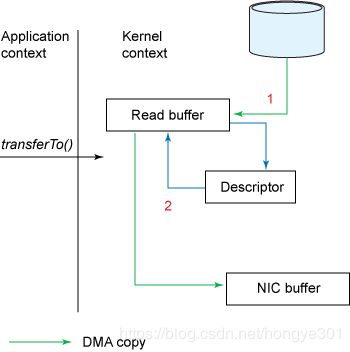
· 最新的Zero Copy的机制是追加了一些descriptor的信息,包括data的位置和长度。然后DMA 直接把data从kernel buffer传输到protocol engine,这样就消除了唯一的一次需要占用CPU的拷贝操作。