kubernetes Job的最佳实践and性能调优
背景
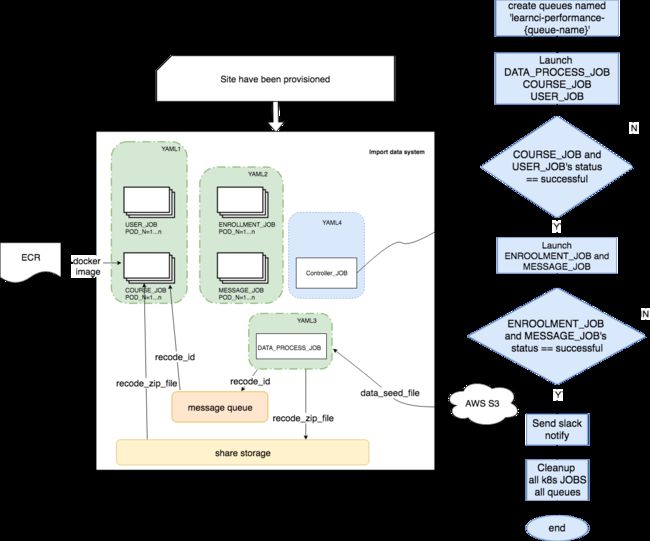
Goal:性能测试的数据准备自动化工具开发
痛点:原有方案,用并行进程操作,site部署完毕后triggle数据准备工作,公司历史包袱,重度依赖jenkins,整个数据准备的工作是由jenkins job组织的,一次导数据要耗时11个小时。
方案
为了找个机会,实践一下kubernetes。
想到进程可以对应到kubernetes中的JOB ,又有并发的特性。该工作特性可以立即抽象成一个Job中多个pod并行。
方案1:主体思想,读写文件进行数据处理,文件存放在共享硬盘
260条course 切分成20份,数据文件放入sharestorage(硬盘)共享,因为job可能被调度到任意的node上,node间数据的共享通过sharestorage。启动20个k8s Job,每个Job处理一份。
健壮性:1,通过配置job的restartPolicy :OnFailure, 将批量重试。
2,在每个job的entrypoint中,增加重试逻辑,每个job,通过写文件,维护一份自己的重试列表。
可扩展性:通过参数化切分份数
优势:方案简单,快速实现。
劣势:一个course导入失败,重试逻辑复杂。
方案2:主体思想,读写queue进行数据处理 ,queue可以是本地service 驻留在内存的进程或者aws的云service (aws queue)。进程间通信。
引入queue,260条course 写入queue,启动一个k8s job ,规定finish 260条course,每批启动20个pod并行执行。
健壮性:任意条course失败,将通过重启pod 重试处理,直到完成260条course处理
可扩展性:queue灵活 存放任意条数据
优势:逻辑简单 充分利用K8S的健壮性机制
劣势:耗费k8s的资源
实现poc的过程踩过的坑
业务逻辑
site 启动要消耗45min 经验证导数据工具将启动一个jvm的进程,不依赖tomcat运转 但会依赖activemq。
启动activemq
启动导数据脚本
K8S相关
activeDeadlineSeconds 时间为整个job运行的时间 超过此时间job将自动结束
backoffLimit 为当restartPolicy设置为 Never时,pod的error次数,当error次数超过该值时,job也会被自动退出。k8s规定默认值是6.调试阶段最好设置大一些。
pod间通信访问共享数据,使用sharestorage(PVC)存放数据
container间通信访问共享数据 ,使用emptyDir:{ }存放数据
container间共用网络,可使用nc命令监听同一个进程
k8s 认证权限管理,在K8s cluster 访问aws queue时,因为整个job是运转在aws ec2上,这样将涉及aws 资源之间互访权限问题。本司,这部分权限管理使用的是开源组件kube2iam,(https://github.com/jtblin/kube2iam),当Job的并发值parallelism设置大于10时,将出现大量的error,
emambp:kubernetes ema$ kubectl get pods --selector=job-name=learnci-performance-consumer-worker-job -n learn-deployments --show-all
NAME READY STATUS RESTARTS AGE
learnci-performance-consumer-worker-job-27bnl 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-6plfh 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-7cxqs 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-87f8x 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-92btc 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-9xc22 0/1 Error 0 3h
learnci-performance-consumer-worker-job-c9d68 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-dvbhw 0/1 Error 0 3h
learnci-performance-consumer-worker-job-h25b9 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-hvxpm 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-k26pb 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-kdfw7 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-l5425 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-ldbk4 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-m89nl 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-pn6qf 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-qvjsw 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-rxkjq 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-tgps6 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-tkqhp 0/1 Error 0 3h
learnci-performance-consumer-worker-job-vpddk 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-xq9vb 0/1 Completed 0 3h
learnci-performance-consumer-worker-job-zlrxj 0/1 Error 0 3h
learnci-performance-consumer-worker-job-zqdct 0/1 Completed 0 3h
kubectl logs learnci-performance-consumer-worker-job-zlrxj -n learn-deployments
config:
cat: /root/.aws/config: No such file or directory
credentials
cat: /root/.aws/credentials: No such file or directory
Unable to locate credentials. You can configure credentials by running "aws configure".通过排查,这是time时序问题,我们提了issue到开源repo,https://github.com/jtblin/kube2iam/issues/136
找到workaround,
while [ $result -ne 200 ];do
sleep 2
result=`curl -I -m 10 -o /dev/null -s -w %{http_code} http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::{instancename}:role/{rolename}`
echo $result
done代码
apiVersion: batch/v1
kind: Job
metadata:
name: learnci-performance-course-consumer-job
spec:
completions: 260
parallelism: 50
activeDeadlineSeconds: 36000 backoffLimit: 400
template:
metadata:
name: job-wq-1
annotations:
iam.amazonaws.com/role: arn:aws:iam::aws-{accountid}:role/{rolename}
spec:
containers:
- name: learn
image: {awsaccount}.dkr.ecr.us-east-1.amazonaws.com/learn/develop/{learnsiteimage} resources:
requests:
cpu: 1
memory: 2Gi
command: [ "/bin/bash"]
args: [ "-c", "/mnt/bbcontent/perfdata/start-import-job.sh server"]
volumeMounts:
- name: bbcontent
mountPath: /mnt/bbcontent
subPath: instance/{instancename}
- name: course
mountPath: /usr/local/blackboard/course
- name: worker
image: {awsaccountid}.dkr.ecr.us-east-1.amazonaws.com/aws-nc:v1
env:
- name: BROKER_URL
value: https://sqs.us-east-1.amazonaws.com/{awsaccountid}/learnci-performance-test
command: [ "/bin/bash"]
args: ["-c", "/mnt/bbcontent/perfdata/start-import-job.sh client"]
#args: ["-c", "sleep 5; /mnt/bbcontent/perfdata/start-import-job.sh client;sleep 600; message=$(aws sqs receive-message --visibility-timeout 3600 --queue-url $BROKER_URL --region us-east-1); echo $message; if [ -n \"$message\" ]; then handle=$(echo $message | jq -r '.Messages[0].ReceiptHandle'); body=$(echo $message | jq -r '.Messages[0].Body'); echo $body>/usr/course/courseid.txt; sleep 6000; else exit -1; fi" ]
volumeMounts:
- name: bbcontent
mountPath: /mnt/bbcontent
subPath: instance/{instancename}
- name: course
mountPath: /usr/course
volumes:
- name: bbcontent
persistentVolumeClaim:
claimName: {claimname}
- name: course
emptyDir: {}
restartPolicy: OnFailure#!/bin/bash
###
### This script performs the data importing. It will be run in two different
### containers within one job pod, acting different roles:
### 1. In learn container(Role: server).
### When running in learn container, it will first listen to a local port(4444),
### waiting a course to be available for processing.
### * If a course received, it will invoke data importing and then quit.
### * If a quit message received, it will quite directly. This is for signaling
### some problematic situations, like aws queue fetch failure, etc.
### 2. In aws toolkit container(Role: client).
### When running in this container, it will send a message to local port 4444,
### (which is listened by the learn container).
### * If it grabs course info from SQS, then the course id will be published to 4444.
### * If it fails to grab the course info, it will send a 'quit' message.
###
### How to use
### Start as server:
### ./start-import-job.sh server
### Start as client:
### ./start-import-job.sh client
set -x
# Role of running, server or client
role=$1
# Working directory
# Where below files should be found in the working dir:
# ArchiveFile_xxx.zip
# bb-config.properties
# stage1_Course_half.txt (for learn?)
# start-import-job.sh (this script)
WORKING_DIR=/mnt/bbcontent/perfdata
WRITE_SHARE=/usr/course/cmd.txt
READ_SHARE=/usr/local/blackboard/course/cmd.txt
cd $WORKING_DIR
echo "Working dir:"
pwd
# SQS Broker
BROKER_URL=https://sqs.us-east-1.amazonaws.com/{awsaccountid}/learnci-performance-test
# Message constants
MSG_QUIT=quit
ROLE_SERVER=server
ROLE_CLIENT=client
function invoke_import()
{
## Things going here.
# 1. Prepare config file
# Copy config files to /usr/local/blackboard/config/
# 2. Prepare course list file
# Create a temp course list file containing the course to import,
# or grep it from the original course list file
# 3. Invoke batch import
# Run /usr/local/blackboard/apps/content-exchange/bin/batch_ImportExport.sh
# with course list file passed in generated in
# 4. Exit
# If everything goes smoothly, exit 0 to signal that the importing succeeds.
course_id=$1
cd $WORKING_DIR
echo 'Current dir:'
pwd
echo 'Copy bb-config.properties'
#cp ./bb-config.properties /usr/local/blackboard/config/
cp -r ./* /usr/local/blackboard/
echo 'Prepare course list file'
grep $course_id stage1_Course_half.txt > $course_id-list.txt
if [ $? != 0 ]; then
echo "Course does not exist: $course_id"
exit 0
fi
echo 'Start importing data'
START_TIME=$(date '+%Y-%m-%d %H:%M:%S')
echo "Start import at: $START_TIME"
ps -ef|grep java|grep -v grep
while [ $? -ne 0 ];do
echo "check whether java process has started up"
/usr/local/blackboard/apps/content-exchange/bin/batch_ImportExport.sh -f $course_id-list.txt -l 1 -t restore >> $course_id-list.txt.log &
sleep 2
ps -ef|grep java|grep -v grep
done
count=0
while :
do
sleep 5
((count++));
echo "check processing notifications"
grep -o "Start processing notifications" /usr/local/blackboard/logs/content-exchange/BatchCxCmd_restore_$course_id.txt
if [ $? -eq 0 ]; then
kill -s 9 `ps -aux | grep $course_id-list.txt| awk '{print $2}'`
break
#elif [ $count -gt 1800 ]; then
#echo "importing data timeout "
#exit 1
fi
done
rc=$?
END_TIME=$(date '+%Y-%m-%d %H:%M:%S')
echo "End import at: $END_TIME"
exit $rc
}
function send_message()
{
echo $1 > $WRITE_SHARE
}
function start_server()
{
echo 'Running as server'
echo 'Checking cmd file existence'
while :
do
if [ -f $READ_SHARE ]; then
sleep 10
break
fi
echo "Sleep 10s..."
sleep 10
done
# Empty message, or quit, exit
msg=`cat $READ_SHARE`
echo "Received message: $msg"
if [ "$msg" == "" ] || [ "$msg" == "$MSG_QUIT" ]; then
echo "Quit!"
exit 1
fi
# assume this is a course id
echo 'Invoke course data importing'
invoke_import $msg
}
function start_client()
{
echo 'Running as client'
echo 'Quiet peroid: 5 seconds'
echo "Receiving message from queue: $BROKER_URL"
# Fetch queue item
result=0
while [ $result -ne 200 ];do
sleep 2
result=`curl -I -m 10 -o /dev/null -s -w %{http_code} http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::{awsaccountid}:role/{rolename}`
echo $result
done
message=$(aws sqs receive-message --visibility-timeout 3600 --wait-time-seconds 15 --queue-url $BROKER_URL --region us-east-1)
# Need to check http return code when call receive-message
# ...
echo "Message received: $message"
if [ -n "$message" ]; then
body=$(echo $message | jq -r '.Messages[0].Body')
handle=$(echo $message | jq -r '.Messages[0].ReceiptHandle')
echo "Send message body to server: $body"
send_message $body
aws sqs delete-message --queue-url $BROKER_URL --receipt-handle $handle --region us-east-1
exit 0
else
echo "Empty message, signal quit"
send_message $MSG_QUIT
exit 1
fi
}
echo "Starting as role: $role"
# main
if [ $role == $ROLE_SERVER ]; then
start_server
elif [ $role == $ROLE_CLIENT ]; then
start_client
else
echo 'Quit due to unknown role: $role'
send_message $MSG_QUIT
exit 1
fi
测试结果
| completions | 50 | 260 | 260 | |
| parallelism | 50 | 50 | 100 | |
| time cost | 8min | 5.5h | 超过6个小时,还出现了大量导数据进程退出的现象 |
性能调优
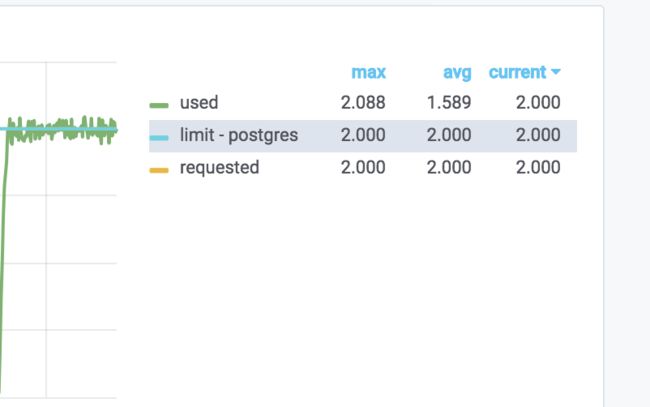
思考分析,为什么测试的结果没有按照预期的趋势,并发越大,时间越短,分析中间出现了什么问题?
通过观察此时被导数据site的监控数据,观察数据库的container 的cpu/memory, 发现cpu已经被耗尽,连接建立变慢,这样可以解释为啥当数据量变大的时候,导数据时间已经不是线性的。
site 部署时的配置 :postgres_cpu_request 2 postgres_mem_request 4Gi

参考: