springboot+springdata+elasticsearch+logstash+拼音分词实现全文搜索
elasticsearch安装
下载地址:
https://www.elastic.co/downloads/elasticsearch
解压到d盘software目录下
CMD下:cd D:\software\elasticsearch-6.2.3\bin
执行elasticsearch.bat
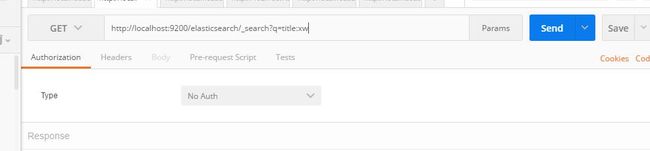
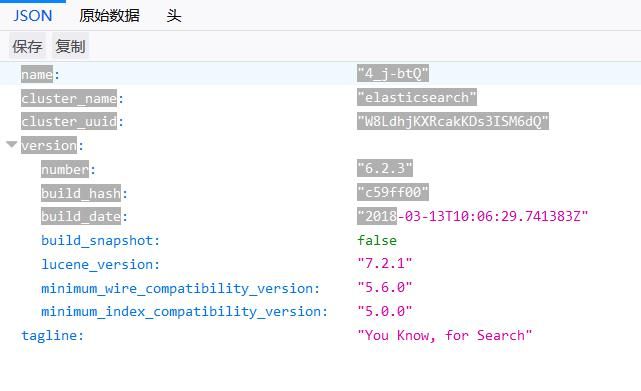
访问9200端口 出现下图即成功
elasticsearch head插件安装
1、安装head插件
下载地址:
https://github.com/mobz/elasticsearch-head,
下载后解压缩。
2、安装node.js
node下载地址
nodejs.org/
$ node -vv6.8.1
npm下载地址
https://www.npmjs.com
$ npm -v3.10.8
使用npm安装grunt:
npm install –g grunt–cli
3、修改elasticsearch配置文件
编辑elasticsearch-6.2.3/config/elasticsearch.yml,加入以下内容
http.cors.enabled: truehttp.cors.allow-origin: "*"
4、修改Gruntfile.js
打开elasticsearch-head-master/Gruntfile.js,找到下面connect属性,新增hostname: ‘0.0.0.0’:
connect: {
server: {
options: {
hostname: '0.0.0.0' ,
port: 9100,
base: '.',
keepalive: true
}
}
}
server: {
options: {
hostname: '0.0.0.0' ,
port: 9100,
base: '.',
keepalive: true
}
}
}
5、启动elasticsearch-head-master
在elasticsearch-head-master/目录下,运行启动命令:
grunt server
访问
http://localhost9100
即可开启
开启elasticsearch服务

集群健康值为绿色或者黄色(能用)即为成功,灰色表示未连接上elasticsearch
拼音分词器安装
可参考
https://blog.csdn.net/napoay/article/details/53907921
pinyin分词器的下载地址:
https://github.com/medcl/elasticsearch-analysis-pinyin
下载,并用maven打包,在项目target文件夹下会生成
elasticsearch-analysis-pinyin-6.2.3.zip
在elasticsearch-6.2.3\plugins目录下新建pinyin文件夹,将
elasticsearch-analysis-pinyin-6.2.3.zip解压放入,如图所示:
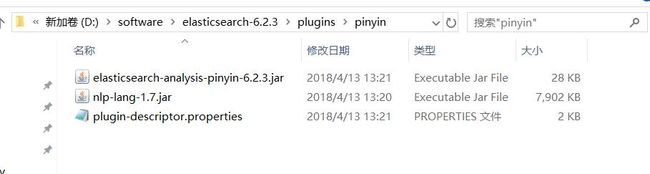
不需要其他配置,启动elasticsearch成功即表示分词器安装成功。
java客户端
采用的springboot+springdata+springcloud 集成
包结构
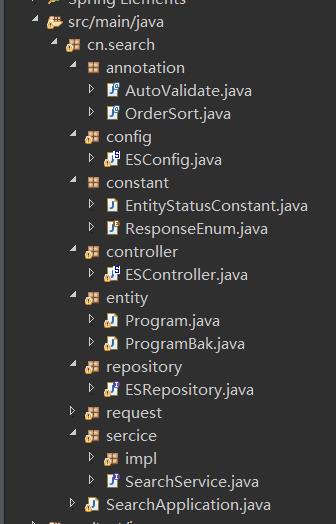
config
package cn.search.config;
import java.net.InetAddress;
import org.elasticsearch.action.admin.indices.mapping.put.PutMappingResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ESConfig {
@Value("${spring.data.elasticsearch.cluster-name}")
private String clusterName;
@Bean
public Client client() throws Exception{
InetSocketTransportAddress node = new InetSocketTransportAddress(
InetAddress.getByName("192.168.7.248"),
9300
);
Settings settings = Settings.builder()
// .put("cluster.name",clusterName)
/**
* 设置client.transport.sniff为true来使客户端去嗅探整个集群的状态,
* 把集群中其它机器的ip地址加到客户端中,这样做的好处是一般你不用手
* 动设置集群里所有集群的ip到连接客户端,它会自动帮你添加,并且自动
* 发现新加入集群的机器。
*/
.put("client.transport.sniff",true)
.put("client.transport.ignore_cluster_name",true)
.build();
TransportClient client = new PreBuiltTransportClient(settings);
client.addTransportAddress(node);
return client;
}
}
实体类
package cn.search.entity;
import lombok.*;
import org.hibernate.annotations.DynamicUpdate;
import org.hibernate.annotations.Type;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.LastModifiedDate;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import cn.search.constant.EntityStatusConstant;
import javax.persistence.*;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
@Getter
@Setter
//指定索引和类型
//elasticsearch中index(索引)相当于数据库,type相当于数据库的表,
//文档相当于数据库的row
//shards 设置分片 replicas设置备份 也可以通过put创建索引时指定
@Document(indexName="elasticsearch",type="doc")//shards=8,replicas=2
public class Program{
@Id
private Long id;
@Field(type = FieldType.Date)
private LocalDateTime createdDate;
@Field(type = FieldType.Date)
private LocalDateTime modifiedDate;
@Field(type = FieldType.Integer)
private Integer status;
@Field(type = FieldType.Integer)
private Integer softDeleted= EntityStatusConstant.ENTITY_IS_DELETED_FALSE;
@Field(type = FieldType.text)
private String programId;
@Field(type = FieldType.text)
private String area;
@Field(type = FieldType.text)
private String description;
@Field(type = FieldType.text)
private String episodeNo;
@Field(type = FieldType.text)
private String genre;
@Field(type = FieldType.text)
private String language;
@Field(type = FieldType.text)
private String rating;
@Field(type = FieldType.text)
private String releaseYear;
@Field(type = FieldType.text)
private String season;
@Field(type = FieldType.text)
private String SeriesType;
@Field(type = FieldType.text)
private String subGenre;
@Field(type = FieldType.text, searchAnalyzer="pinyin_analyzer",analyzer="pinyin_analyzer")
//指定分词器
private String title;
@Field(type = FieldType.text)
private String type;
@Field(type = FieldType.text)
private String directors;
@Field(type = FieldType.text)
private String writers;
@Field(type = FieldType.text)
private String casts;
@Field(type = FieldType.text)
private String channelName;
@Field(type = FieldType.text)
private String channelId;
}
注:elasticsearch5.x版本开始type类型没有string,用keyword和text替代
Repository
package cn.search.repository;
import java.util.List;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import cn.search.entity.Program;
import cn.search.entity.ProgramBak;
public interface ESRepository extends ElasticsearchRepository{
//Page findByChannelName(String channelName,Pageable pageable);
Page findByTitle(String title,Pageable pageable);
List findByTitle(String title);
}
和springJPA用法一致
service
接口:
package cn.search.sercice;
import java.util.List;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Sort;
import cn.search.entity.Program;
public interface SearchService {
Page getProgramBykeyWord(String keyWord,Integer offset, Integer limit, Sort sort);
List getProgramBykeyWord(String keyWord);
}
实现类:
package cn.search.sercice.impl;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.stereotype.Service;
import cn.search.entity.Program;
import cn.search.entity.ProgramBak;
import cn.search.repository.ESRepository;
import cn.search.sercice.SearchService;
@Service("SearchService")
public class SearchServiceImpl implements SearchService {
private ESRepository esRepository;
@Autowired
public SearchServiceImpl(ESRepository esRepository){
this.esRepository = esRepository;
}
@Override
public Page getProgramBykeyWord(String keyWord, Integer offset, Integer limit, Sort sort) {
// TODO Auto-generated method stub
Pageable pageable=PageRequest.of(offset/limit,limit,sort);
Page page = esRepository.findByTitle(keyWord, pageable);
return page;
}
@Override
public List getProgramBykeyWord(String keyWord) {
// TODO Auto-generated method stub
return esRepository.findByTitle(keyWord);
}
}
controller层
package cn.search.controller;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import cn.search.entity.Program;
import cn.search.entity.ProgramBak;
import cn.search.repository.ESRepository;
import cn.search.request.ProgramPageRequest;
import cn.search.sercice.SearchService;
@RestController
public class ESController {
private SearchService esService;
@Autowired
private ESRepository repository;
@Autowired
public ESController(SearchService esService){
this.esService = esService;
}
@GetMapping("/es/search")
public Page findProgramByKeyWord(ProgramPageRequest pageRequest){
Page page = esService.getProgramBykeyWord(pageRequest.getKeyword(), pageRequest.getOffset(), pageRequest.getLimit(),pageRequest.getSort(pageRequest.getOrderSort(),pageRequest.getFieldConvert()));
return page;
}
@GetMapping("/es/find")
public List getProgramByKeyWord(@RequestParam(value="keyword") String keyWord){
List list = esService.getProgramBykeyWord(keyWord);
return list;
}
@GetMapping("/es/save")
public String save(){
Program p = new Program();
p.setTitle("晚间新闻");
p.setChannelName("江苏卫视");
p.setProgramId("code");
p.setGenre("新闻");
// p.setPictureUrl("111");
// p.setThumbUrl("222");
repository.save(p);
return "OK";
}
}
yml文件
spring:
application:
name: search-service
data:
elasticsearch:
cluster-name: elasticsearch
local: false
repositories:
enabled: true
server:
port: 8080
eureka:
client:
service-url:
defaultZone: http://register-server1/eureka/
instance:
prefer-ip-address: true
pom依赖:
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
注:如果要单独启动
将pom文件中的spring-cloud-starter-netflix-eureka-client依赖、yml文件的eureka-Client、启动类上的@EnableEurekaClient注释掉,并在@SpringBootApplication后添加(exclude= {DataSourceAutoConfiguration.class})
logstash
下载地址
https://www.elastic.co/downloads/logstash
安装(略)
sql:需要导入elasticsearch的字段
全文搜索
使用logstash从mysql同步数据到elasticsearch,由java客户端实现全文搜索。
1、开启elasticsearch和elasticsearch head插件
2、 在9200端口下 创建索引 发送put请求(也可以在lunix环境下使用curl命令)
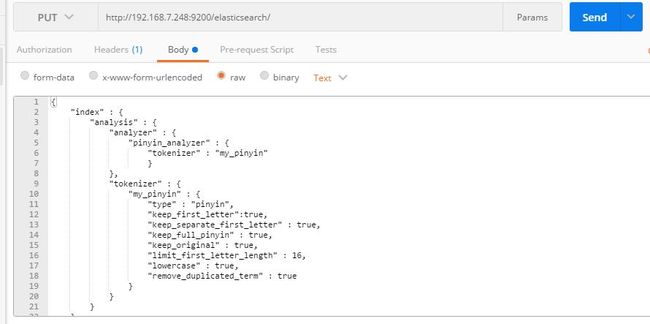
{
"index" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin",
"keep_first_letter":true,
"keep_separate_first_letter" : true,
"keep_full_pinyin" : true,
"keep_original" : true,
"limit_first_letter_length" : 16,
"lowercase" : true,
"remove_duplicated_term" : true
}
}
}
}
}
注: "keep_separate_first_letter" : true(根据情况选择true或false)
false:首字母搜索只有两个首字母相同才能命中,全拼能命中
true:任何情况全拼,首字母都能命中
出现索引
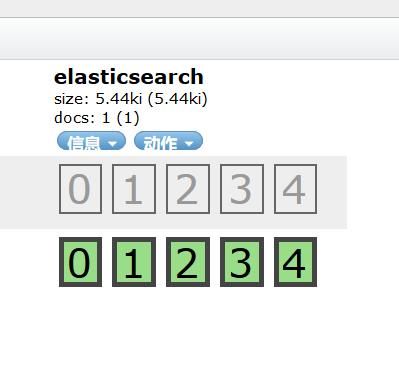
点击信息--索引信息 上面有分词器analysis配置如下图所示即为成功

3、启动springboot项目
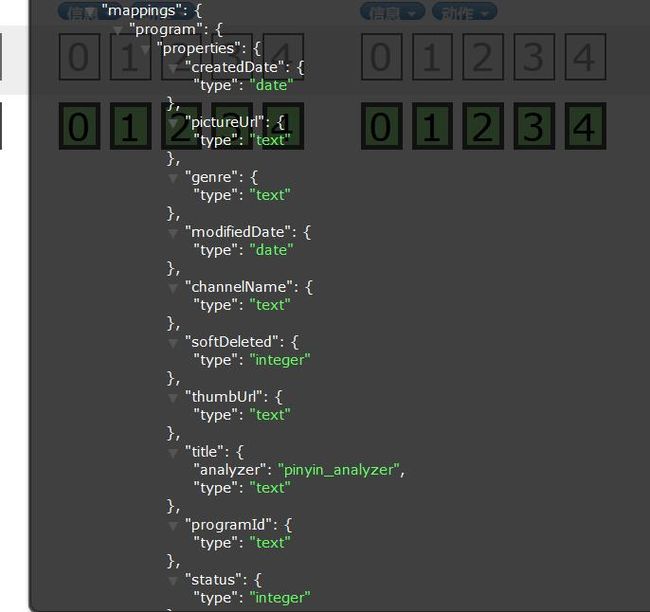
点击信息发现 实体属性已经全部注入,title属性也 已经指定分词器(“annlyzer”:“pinyin_analyzer”) 即为成功
4、开启logstash,sql为需要导入的字段,导入数据到elasticsearch
5、测试:通过传入的参数搜索到内容(比如传入xw搜索到title为“新闻”,“晚间新闻”、“下午”的节目)
通过8080端口:

通过9200端口: