Spark2.2,IDEA,Maven开发环境搭建附测试
Spark2.2,IDEA,Maven开发环境搭建附测试
前言:
停滞了一段时间,现在要沉下心来学习点东西,出点货了。
本文没有JavaJDK ScalaSDK和 IDEA的安装过程,网络上会有很多文章介绍这个内容,因此这里就不再赘述。
一、在IDEA上安装Scala插件
首先打开IDEA,进入最初的窗口,选择Configure -——>Plugins

然后会看到下面的窗口:

此时我们选择‘Browse Repositories …’,然后输入Scala,

找到下图这一项,点击“install”即可
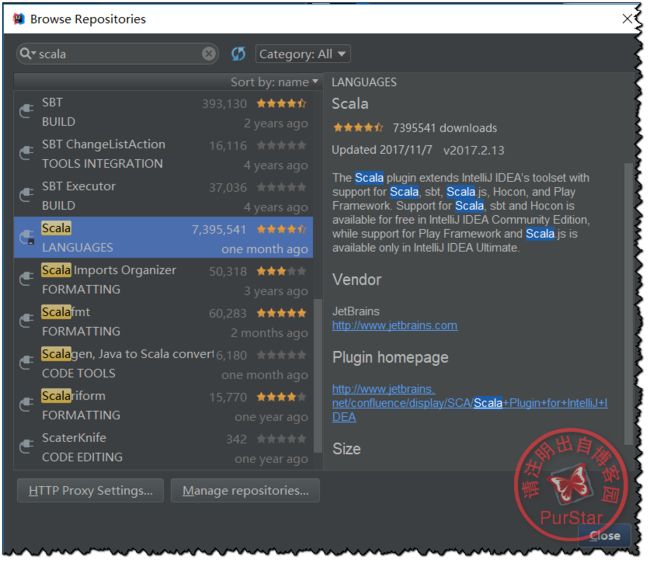
安装完成后,请重启IDEA。
二、创建一个Scala工程
依次点击Create New Project ——>Scala——>IDEA——>Next
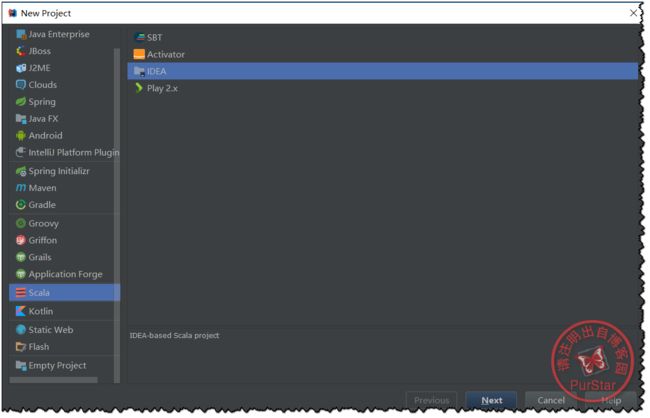
然后我们需要点击create,增加相应的SDK版本及位置。
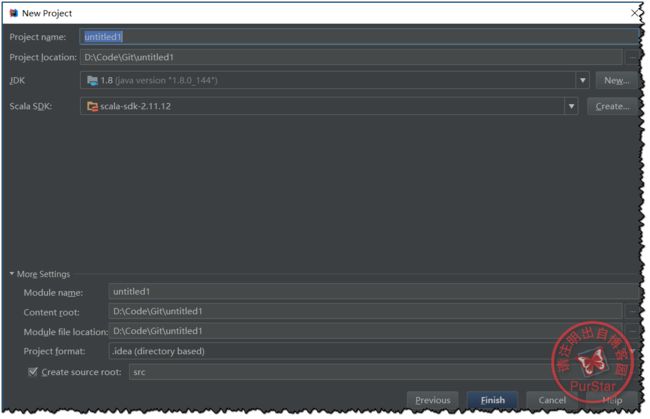
自己填写好其他信息后就可以,点击Finish了。
三、添加Maven框架以及编写pom.xml
首先右键项目名然后选择Add Framework Support...

然后找到maven打钩,点击Ok即可.
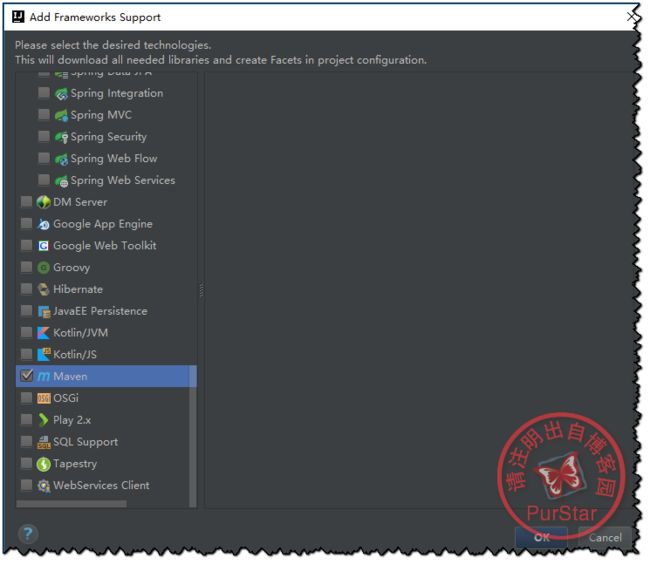
接下来,编写Pom.xml,如下:
![]()
4.0.0 com.sudy SparkStudy 1.0-SNAPSHOT 2.2.0 2.11 org.apache.spark spark-core_${scala.version} ${spark.version} org.apache.spark spark-streaming_${scala.version} ${spark.version} org.apache.spark spark-sql_${scala.version} ${spark.version} org.apache.spark spark-hive_${scala.version} ${spark.version} org.apache.spark spark-mllib_${scala.version} ${spark.version} org.scala-tools maven-scala-plugin 2.15.2 compile testCompile maven-compiler-plugin 3.6.0 1.8 1.8 org.apache.maven.plugins maven-surefire-plugin true
![]()
四、添加winutils.exe文件
winutils.exe下载地址:
https://codeload.github.com/srccodes/hadoop-common-2.2.0-bin/zip/master
解压后,记住放入的路径就好。
五、使用local模式测试环境是否搭建成功?
右键java文件夹,依次点击New——>Scala Class

然后选择Object,输入名称即可。

写入测试代码:
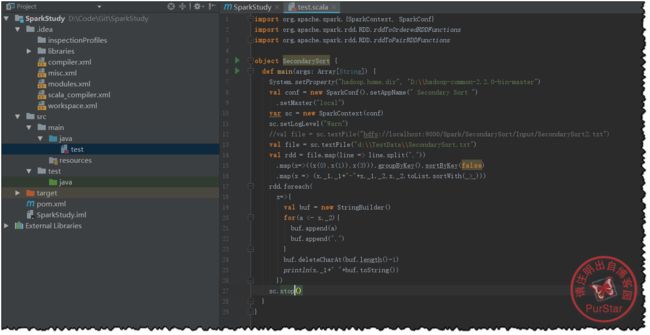
测试代码部分可以参照我之前写的一篇博客的后半部分:
分别使用Hadoop和Spark实现二次排序
为了大家方便这里复制出代码和测试文本:
![]()
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.rdd.RDD.rddToOrderedRDDFunctions
import org.apache.spark.rdd.RDD.rddToPairRDDFunctions
object SecondarySort {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master")
val conf = new SparkConf().setAppName(" Secondary Sort ")
.setMaster("local")
var sc = new SparkContext(conf)
sc.setLogLevel("Warn")
//val file = sc.textFile("hdfs://localhost:9000/Spark/SecondarySort/Input/SecondarySort2.txt")
val file = sc.textFile("d:\\TestData\\SecondarySort.txt")
val rdd = file.map(line => line.split(","))
.map(x=>((x(0),x(1)),x(3))).groupByKey().sortByKey(false)
.map(x => (x._1._1+"-"+x._1._2,x._2.toList.sortWith(_>_)))
rdd.foreach(
x=>{
val buf = new StringBuilder()
for(a <- x._2){
buf.append(a)
buf.append(",")
}
buf.deleteCharAt(buf.length()-1)
println(x._1+" "+buf.toString())
})
sc.stop()
}
}
![]()
测试文本如下:
![]()
2000,12,04,10 2000,11,01,20 2000,12,02,-20 2000,11,07,30 2000,11,24,-40 2012,12,21,30 2012,12,22,-20 2012,12,23,60 2012,12,24,70 2012,12,25,10 2013,01,23,90 2013,01,24,70 2013,01,20,-10
![]()
注意:
D:\\hadoop-common-2.2.0-bin-master 是我解压后放入的路径。
d:\\TestData\\SecondarySort.txt 是测试数据的位置,用于程序的运行。 好了,这篇文章结束了,剩下就是你的动手操作了。
参考:
2017.10最新Spark、IDEA、Scala环境搭建
【spark】创建一个基于maven的spark项目所需要的pom.xml文件模板
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries
作者:PurStar 出处:www.cnblogs.com/purstar