深度学习(十一):卷积神经网络CNN
这是一系列深度学习的介绍,本文不会涉及公式推导,主要是一些算法思想的随笔记录。
适用人群:深度学习初学者,转AI的开发人员。
编程语言:Python
参考资料:吴恩达老师的深度学习系列视频
吴恩达老师深度学习笔记整理
唐宇迪深度学习入门视频课程
深度学习500问
笔记下载:深度学习个人笔记完整版
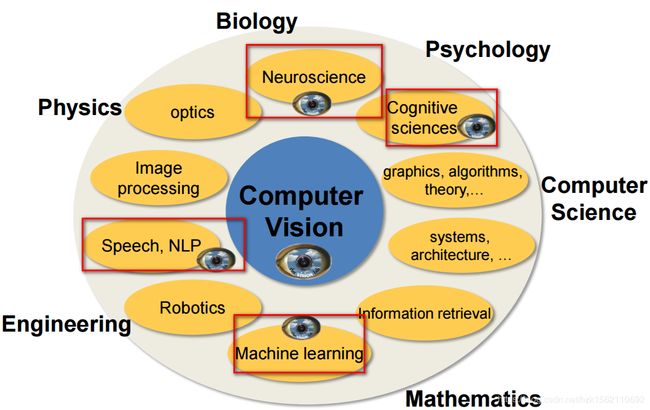
计算机视觉(Computer Vision)
计算机视觉(Computer vision)是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成更适合人眼观察或进行仪器检测的图像。
计算机视觉技术是一种典型的交叉学科研究领域,包含了生物、心理,物理,工程,数学,计算机科学等领域,存在与其他许多学科或研究方向之间相互渗透、相互支撑的关系。在概念的理解中我们常常听到AI、图像处理、模式识别、机器视觉等词语,那么他们和计算机视觉之间是怎样的关系呢?
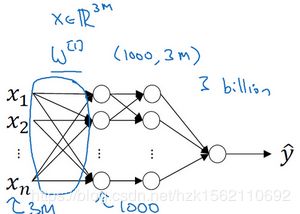
在应用计算机视觉时要面临一个挑战,就是数据的输入可能会非常大。
比如一张1000×1000的图片,它足有1兆那么大,但是特征向量的维度达到了1000×1000×3,因为有3个RGB通道,所以数字将会是300万。这就意味着,特征向量的维度高达300万。所以在第一隐藏层中,你也许会有1000个隐藏单元,而所有的权值组成了矩阵 W1。如果你使用了标准的全连接网络,这个矩阵的大小将会是1000×300万,即30亿个参数,这是个非常巨大的数字。
CNN的应用
1.Image Classification 图像分类
2.Retrieval 检索\推荐
3.Detection 检测
4.Image Segmentation 图像分隔
5.Self-driving cars 无人驾驶汽车
6.人脸识别
7.姿势识别
8.标志识别(车牌识别、手写识别)
9.Image Captioning 看图说话 (CNN+LSTM)
10.Style Transfer 风格转换
CNN的组成
CNN主要实现的就是特征提取,最经典的应用就是从多个图片中提取出有用的信息。这个过程对于人来说是个黑盒的过程,人们并不能很确切的知道里面发生了什么。结果也是非常抽象的,但是却能学习到很好的效果。
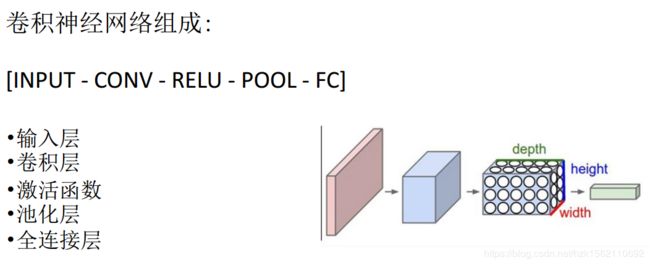
如上图所示,一个CNN会有三个基本层:
- 卷积层
- 池化层
- Flatten层 & 全连接层
卷积与池化往往要进行多次,一个或多个卷积后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个softmax。所以一个CNN的结构大致可以描述为: 输入→卷积→ReLU→卷积→ReLU→池化→ReLU→卷积→ReLU→池化→全连接。一般进行卷积操作后面都要紧接着加上非线性的激活函数操作,如上的Conv+ReLU。
过滤器(Filter)
Filter(过滤器)也被称为卷积核(Kernal) ,过滤器可以被看成是特征标识符(feature identifiers)。这里的特征指的是例如直边缘、原色、曲线之类的东西。
一个Filter扫过整个图片可以得到一个/层特征图(Feature map)。
如下,两个Filters得到两个特征图。

卷积层(Convolutional Layer)
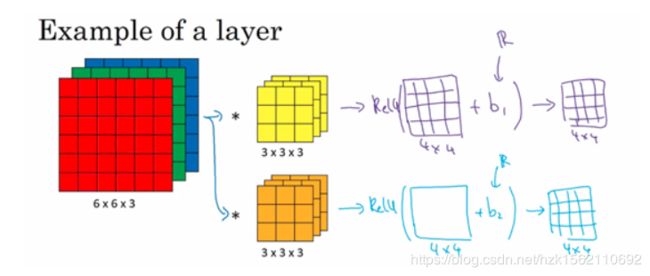
深度(Depth):Filter的深度和输入的深度保持一致。
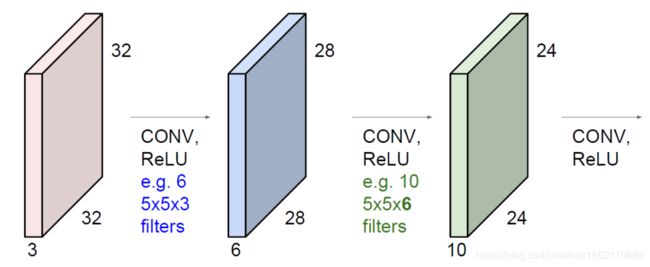
如上图所示,一个原始32x32x3的图像,先经过6个5x5x3的filter进行卷积运算,会得到6层28x28的特征图,在此基础上,再经过10个5x5x6的filter卷积计算,会得到10层24x24的特征图,。注意,每次卷积的深度总与输入的深度保持一致,即channels一样。
随着层数增加,高度和宽度都会减小,而通道数量会增加。
在python中,你会使用一个叫conv_forward的函数。
如果在tensorflow下,这个函数叫tf.conv2d。
在Keras这个框架,在这个框架下用Conv2D实现卷积运算。
卷积的计算
卷积运算用“*”来表示,这是数学中的标准标志。
对应位置相乘的和作为新的像素点,然后移动Filter,扫过整个图片形成新的特征图。
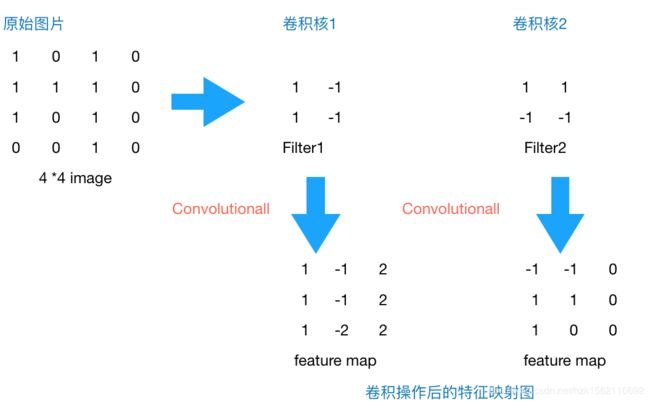
如上图,4x4 image与两个2x2的卷积核操作结果(灰度图像为例)。
注意,在数学中,卷积的运算会在上述运算前先进行翻转操作,准确地说,上述操作在数学中称为互相关(cross-correlation)而不是卷积(convolution),但是在机器学习文献的话,你会发现许多人都把它叫做卷积运算,不需要用到这些翻转。
卷积核参数分析
stride:滑动的步长 ,stride越小,保留的信息越多,但计算量会越多,故stride选择的要适中
由于有些像素值会被多个卷积包含在内计算,有些只能被计算一次,为了防止信息丢失,我们就需要对原来的图片四周进行填充
padding,例如padding=1:在原始的输入上加上一层0,当作边缘,防止原始数据作为边缘值。
padding通常有两个选择,分别叫做Valid卷积和Same卷积。
- Valid卷积:意味着不填充,padding=0。
- Same卷积:意味着填充后,输出大小和输入大小是一样的。
计算机视觉中,Filter size通常是奇数,甚至可能都是这样。吴恩达老师提到两种可能,一是如果Filter size是偶数,那么会使用一些不对称填充;二是若有一个奇数维过滤器,比如3×3或者5×5的,它就有一个中心点。有时在计算机视觉里,如果有一个中心像素点会更方便,便于指出过滤器的位置。
输出的height Ho
输入的height Hi
Filter的size(height) f
Ho = (Hi-f+2*pad)/stride + 1

注意,只在Filter完全包括在图像或填充完的图像内部时,才对它进行运算。即Ho = (Hi-f+2*pad)/stride + 1的结果不能整除的时候,要进行向下取整,对应的函数是floor()。
可参照:卷积层的计算细节
卷积核大小的选定
AlexNet 中用到了一些非常大的卷积核, 比如 11×11、 5×5 卷积核, 之前人们的观念是,卷积核越大, receptive field(感受野) 越大, 看到的图片信息越多, 因此获得的特征越好。 虽说如此, 但是大的卷积核会导致计算量的暴增, 不利于模型深度的增加, 计算性能也会降低。
于是在 VGG(最早使用)、 Inception 网络中, 利用 2 个 3×3 卷积核的组合比 1 个 5×5 卷积核的效果更佳, 同时参数量(3×3×2+1 VS 5×5×1+1) 被降低, 因此后来 3×3 卷积核被广泛应用在各种模型中。
多个小的卷积核叠加使用要远比一个大的卷积核单独使用效果要好的多, 在连通性不变的情况下, 大大降低了参数个数和计算复杂度。 当然, 卷积核也不是越小越好, 对于特别稀疏的数据, 当使用比较小的卷积核的时候可能无法表示其特征, 如果采用较大的卷积核则会导致复杂度极大的增加。 总而言之, 我们应该选择多个相对小的卷积核来进行卷积。
图解 12 种不同类型的 2D 卷积
http://www.sohu.com/a/159591827_390227
局部连接与权值共享
如果采用卷积层和神经元之间采用全连接,则参数过于庞大,所以CNN会采用局部连接的方式。
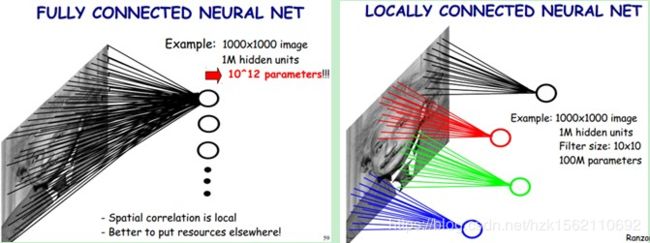
这个重要特性使卷积神经网络具有以下两个有趣的性质。
- 卷积神经网络学到的模式具有平移不变性(translation invariant)。卷积神经网络在图像右下角学到某个模式之后,它可以在任何地方识别这个模式,比如左上角。对于密集连接网络来说,如果模式出现在新的位置,它只能重新学习这个模式。这使得卷积神经网络在处理图像时可以高效利用数据(因为视觉世界从根本上具有平移不变性),它只需
要更少的训练样本就可以学到具有泛化能力的数据表示。 - 卷积神经网络可以学到模式的空间层次结构(spatial hierarchies of patterns)。第一个卷积层将学习较小的局部模式(比如边缘),第二个卷积层将学习由第一层特征组成的更大的模式,以此类推。这使得卷积神经网络可以有效地学习越来越复杂、越来越抽象的视觉概念(因为视觉世界从根本上具有空间层次结构)。
尽管采用了局部连接,可参数还是很多,让每个特征图的点的权重参数是一样的(共享的),即权值共享。
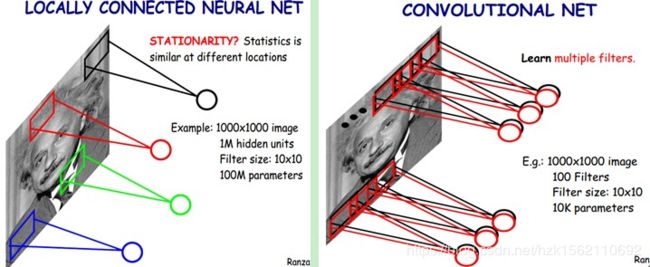
可参照:局部连接与权值共享
神经网络可以通过这两种机制减少参数,以便我们用更小的训练集来训练它,从而预防过度拟合。同时,卷积神经网络善于捕捉平移不变。
池化层(Pooling Layer)
Pooling:对特征图进行压缩,进行特征的浓缩 ,类似于下采样(downsampling)的操作。
池化层不带有参数,只是简简单单地压缩。
池化层压缩的两种方式:
1.Max Pooling
2.Mean Pooling
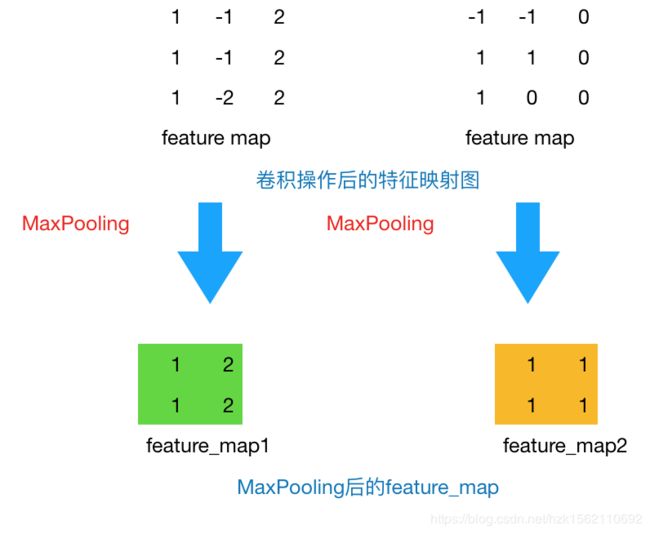
在神经网络中,最大池化要比平均池化用得更多。
池化的超级参数包括过滤器大小f和步幅s,常用的参数值为f=2,s=2,应用频率非常高,其效果相当于高度和宽度缩减一半。大部分情况下,最大池化很少用padding,即p=0。
池化只是计算神经网络某一层的静态属性,没有什么需要学习的,它只是一个静态属性。池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于池化。
人们在计算神经网络有多少层时,通常只统计具有权重和参数的层。因为池化层没有权重和参数,只有一些超参数。所以经常把CONV和POOL共同作为一个层,如标记为Layer1。
为什么可以通过池化降低维度?
因为图像具有一种“静态性”的属性, 这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。 因此, 为了描述大的图像, 一个很自然的想法就是对不同位置的特征进行聚合统计, 例如, 人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)来代表这个区域的特征。视觉世界从根本上具有平移不变性。
Flatten层 & Fully Connected Layer
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层(Dense)的过渡。
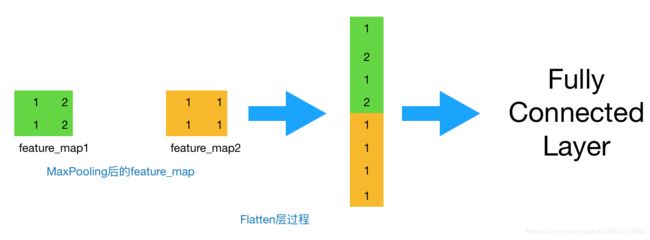
超参数的设定
尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,选一个在别人任务中效果很好的架构,那么它也有可能适用于你自己的应用程序。
偏置
经过Filter后得到特征图,要对特征图添加偏置,即特征图中每个值都加上偏置b。
Pooling和ReLU的顺序问题
在用CNN做图像的时候,都是在ReLU层之后再做Max Pooling,ReLU层是每一层conv层后必加的非线性激励,Pooling层是间或需要的降维手段,是不能交换的。但是由于Max Pooling和ReLU都是求最大值(每个通道取值范围0~255,可参照二值图像、灰度图像、彩色图像),所以ReLU和Max Pooling可以交换。
全卷积与 Local-Conv 的异同点
如果每一个点的处理使用相同的 Filter, 则为全卷积, 如果使用不同的 Filter, 则为Local-Conv。
几点思考
- 原始图像的width、height不一定相等,Filter的width、height也不一定相等,因此公式需要更新;
- 同一个卷积层的多个Filter形状必须保持一致吗?比如一个用3x3x3,一个用2x2x3?
传统的层叠式网络, 基本上都是一个个卷积层的堆叠, 每层只用一个尺寸的卷积核, 例如VGG 结构中使用了大量的 3×3 卷积层。 事实上, 同一层 feature map 可以分别使用多个不同尺寸的卷积核, 以获得不同尺度的特征, 再把这些特征结合起来, 得到的特征往往比使用单一卷
积核的要好, 谷歌的 GoogLeNet, 或者说 Inception 系列的网络, 就使用了多个卷积核的结构: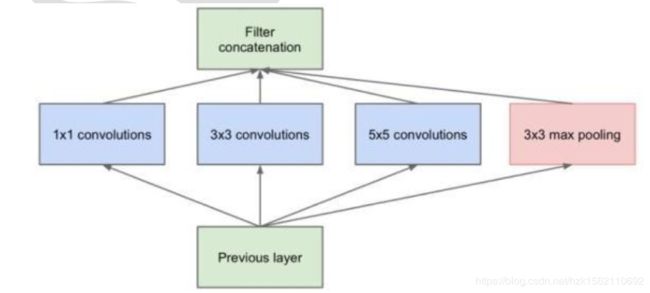
如上图所示, 一个输入的 feature map 分别同时经过 1×1、 3×3、 5×5 的卷积核的处理,得出的特征再组合起来, 获得更佳的特征。
所以,每层卷积可以使用不同尺寸的卷积核。
图像分类(Image Classification)
下图为 CIFAR-10 数据集构建的一个卷积神经网络结构示意图:

边缘检测(Edge detection)
卷积运算是卷积神经网络最基本的组成部分, 神经网络的前几层首先检测边缘, 然后, 后面的层有可能检测到物体的部分区域, 更靠后的一些层可能检测到完整的物体。
在边缘检测中,Filter经常被称为滤波器,或者算子。

如上,是水平边缘检测器、垂直边缘检测器。
除此之外,还有Sobel滤波器、Scharr滤波器等,可参考:
OpenCV 边缘检测:Canny算子,Sobel算子,Laplace算子,Scharr滤波器
也可以以将滤波器矩阵的所有数字都设置为参数,通过数据反馈,让神经网络自动去学习它们。
图像识别、视频分析的一般流程
