【学习笔记】High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection/CSP
论文地址:https://arxiv.org/abs/1904.02948v1
代码地址:https://github.com/liuwei16/CSP
1、概述
传统的目标检测大多基于滑动窗体或者先验框方式,而无论哪个方法都需要繁杂的配置。本文中所介绍的检测器(CSP--Center and Scale Prediction),以行人检测为例,提出了一个高级语义特征检测的新视角。CSP放弃传统的窗体检测方式,通过卷积操作直接预测行人的中心位置和维度大小。结果显示CSP在准确率和速度上都有显著提高。
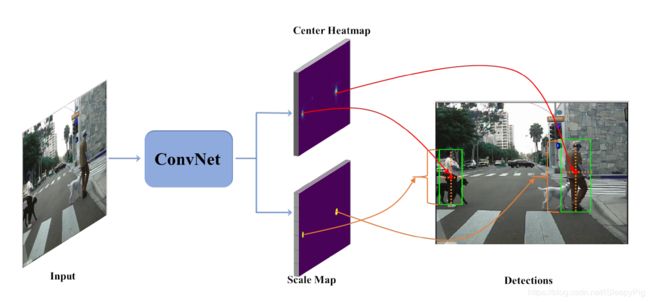 图1 CSP过程图
图1 CSP过程图
2、结构设计
 图2 CSP整体结构
图2 CSP整体结构
CSP整体结构如图一所示,其中主干网络部分缩减自一个标准的网络结构(如:ResNet-50 和 MobileNet),并且在ImageNet上预训练过。主要分成两部分:Feature Extraction和Detection Head。
2.1 Feature Extraction
以ResNet-50为例,以每次下采样为界将其卷积层分为五个阶段,每个阶段的大小是原图以缩减因子分别为2,4,8,16,32得到的缩略特征图。并且在第五步采用孔洞卷积,最终得到的特征图大小与第四阶段一致,是原图的1/16。因为浅层含有更加准确的位置信息,深层拥有更多的语义信息,所以作者将不同阶段的特征图串联成一个。又因为图片特征图大小不一,所以采用反卷积方式将图片转换成相同大小后再做串联操作。因为不同的特征图含有的数据维度也是不相同的,所以我们还要先使用L2标准化将其标准差变更为10。
2.2 Detection Head
在这个部分中,作者首先对Feature Extraction部分得到的特征图做卷积操作,将其通道数缩减至256,然后添加两个并行的卷积层,卷积核大小是1x1,分别生成中心点热力图和维度大小预测图。
下采样特征图的缺点就是位置信息不准确,为了减少误差,可选择稍微调整中心位置,在上述两个并行的分支加上额外的偏移量预测分支。
3、训练
3.1 Ground Truth
最终得到的预测图与Feature Extraction部分得到的特征图大小一致(H/r X W/r),所以我们训练数据也要做相应的压缩。实际的训练数据如图3(a)所示,给出了标记行人的bounding boxes,但是CSP并没有采用滑动窗体或者先验框的方式来预测物体,所以这种标记方式不适用与CSP,所以作者对原数据做了一些调整。
对于位置信息,作者将bounding boxes中心像素点标记为positive,其他点则标记为negative。对于维度大小信息,因为bounding boxes采用了固定的纵横比0.41,所以此处用高度信息代表bounding boxes的维度大小,这样在预测中也只需要预测高度信息。其中第k个标记为positive的点,还会分配到一个log(hk)值,代表第k个bounding box的高度。同时,为了降低不确定性,将该点半径两个像素值以内的negative点都指派为log(hk)值。如图3(b)所示。
 图3 训练数据
图3 训练数据
如果加上了偏移量预测分支,这些中心点的偏移量可以定义成:

3.2 Loss Function
损失函数包含两个部分,第一部分是预测中心点位置的损失,第二部分是预测维度大小的损失。
在预测中心点位置时,作者将其视为一个分类问题。由于很难预测到一个准确的像素点,这样在训练中,positive点附近的点就会带来较多的误差,不利于网络的训练。为了减少这种不确定性带,作者采用了在positive点上添加二维高斯掩膜。如图3(c)所示,具体计算方式如下:

其中,K代表图片中目标数量, (xk,yk,wk,hk)代表k物体的中心点坐标、宽度和高度。方差(![]() ,
, ![]() )与物体的宽和高对应成比例。如果掩膜有重叠,则选值高的那个。
)与物体的宽和高对应成比例。如果掩膜有重叠,则选值高的那个。
因此,中心点预测损失函数是:

其中:
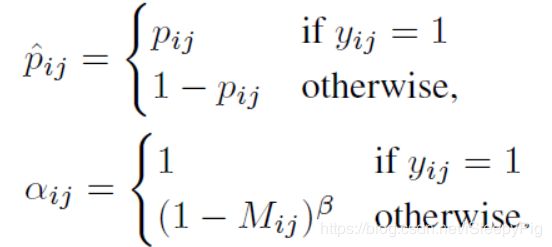
在上述公式里,pij∈[0,1]是预测当前像素点是中心点的可能性,yij∈{0,1}是ground truth标签,yij=1代表该像素点被标记为positive,yij=0表示该点为negative。通过参数αij减少positive附近的negative点对总体损失函数的影响,经过多次实验将γ设置为2,将β设置为4。(这里我认为是在中心点预测时,很难准确找到该点,所以网络把positive点附近的各个negative预测为positive的可能性很大,这样所有点加起来就会贡献较大的误差,网络的拟合效果不佳。而使用高斯掩膜之后会减少附近negative点所带来的误差影响,有利于网络训练。)
对于维度大小的预测,作者将其视为回归任务,具体损失计算如下:

其中,sk和tk分别代表每个positive点的预测值和真实值。(上文有提到将positive附近半径在2以内的negative都赋值log(hk),我认为理由同上,减少中心点不确定所带来的影响)
如果添加了偏移量预测分支,其损失计算也是使用SmoothL1损失函数,标记为Loffset。
最终的损失函数为:

其中λc设置为0.01,λs设置成1,λo设置成0.1。
3.3 Inference
在测试时,CSP只运行一次前向的FCN,得到多个预测值,具体而言,保持中心点预测热力图中置信度大于0.01的点,以及在维度预测图中的相应维度,然后自动生成边界框并且映射到原始图像大小。接着使用NMS(非极大值抑制)算法,阈值设置为0.5。
4、实验
这部分内容作者进行了一系列对比实验,主要对比预测点的选择(中心点、上顶点、下顶点):
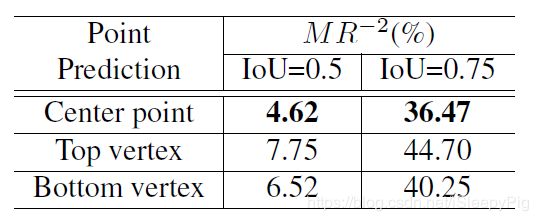 图4 预测点选择
图4 预测点选择
框体维度值预测(高度、宽度、高加宽):
 图5 维度值选择
图5 维度值选择
特征值分辨率(r=2,4,8,16):
 标图6 分辨率选择题
标图6 分辨率选择题
特征图的组合(Φ2、Φ3、Φ4、Φ5的搭配组合):
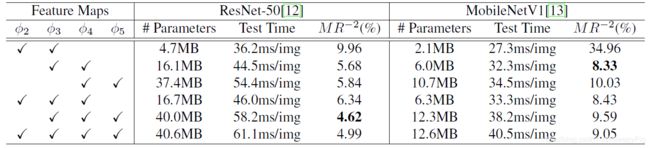 图7 特征图组合
图7 特征图组合
最后,作者给出了在Caltech数据集上的实验结果对比图:
 图8 Caltech结果对比图
图8 Caltech结果对比图
在CityPersons数据集上的结果对比图(红色和绿色分别表示结果最优和其次的值):
 图9 CityPersons结果对比图
图9 CityPersons结果对比图
OK,这只是我个人学习心得。作为刚入坑的博客小白,诚惶诚恐,还请各位大佬不吝赐教。