Hadoop分布式文件系统的搭建
**
Hadoop
**
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop解决哪些问题?
海量数据需要及时分析和处理
海量数据需要深入分析和挖掘
数据需要长期保存
海量数据存储的问题:
磁盘IO称为一种瓶颈,而非CPU资源
网络带宽是一种稀缺资源
硬件故障成为影响稳定的一大因素
Hadoop 相关技术
Hbase
Nosql数据库,Key-Value存储
最大化利用内存
HDFS
hadoop distribute file system(分布式文件系统)
最大化利用磁盘
MapReduce
编程模型,主要用来做数据分析
最大化利用CPU
**
搭建测试环境
官方帮助文档
http://hadoop.apache.org/docs/r2.7.6/hadoop-project-dist/hadoop-common/SingleCluster.html#Prepare_to_Start_the_Hadoop_Cluster
**
1 需求
使用了三台centos7虚拟机 hadoop版本使用从官网下载的
http://hadoop.apache.org/releases.html 自行选择即可
jdk环境使用rpm安装即可 记得rpm的java路径在/usr下 这个路径需要在hadoop配置文件中使用
2
安装步骤
###################################################################3
hadoop解压目录指定后 将变量添加至配置文件
[root@server1 hadoop]# vim /root/.bash_profile
HADOOP_HOME=/usr/local/hadoop
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
#PATH=$PATH:$HOME/bin:/mnt/tidb-latest-linux-amd64/bin
##################################################################
hadoop初始化文件
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
$ cat output/*3
编辑slave配置文件
编辑 slaves文件 添加slave主机即可
[root@server1 hadoop]# pwd
/usr/local/hadoop/etc/hadoop
[root@server1 hadoop]# vim slaves
node1
node2
4
配置core-site.xml (基本所有的配置文件都添加在configuration之间)
<property>
<name> fs.default.name name>
<value>hdfs://master:9000value>
<description>bobodescription>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
<description>HDFS的URIdescription>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/tmpvalue>
<description>节点上本地的hadoop临时文件夹description>
property>
5
创建hadoop需要使用到
[root@server1 hadoop]# cd hdfs/
[root@server1 hdfs]# ls
data names-site.xml
/usr/local/hadoop/tmp
配置hdfs-site.xml
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/hdfs/namevalue>
<description>namenode上存储hdfs名字空间元数据 description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/hdfs/datavalue>
<description>datanode上数据块的物理存储位置description>
property>
<property>
<name>dfs.replicationname>
<value>1value>
<description>副本个数,默认是3,应小于datanode机器数量description>
property>
6
配置mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<description>指定mapreduce使用yarn框架description>
property>
7
配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
<description>指定resourcemanager所在的hostnamedescription>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
<description>
NodeManager上运行的附属服务。
需配置成mapreduce_shuffle,才可运行MapReduce程序
description>
property>
8
配置完成
scp将hadoop目录发送至node1 node2即可
9
配置ssh的免密登陆
ssh-keygen
ssh-copy-id node1
ssh-copy-id node2
测试
[root@server1 hadoop]# ssh node1
Last login: Sat Aug 25 21:59:17 2018 from server1
[root@server2 ~]#
10
配置地址解析
172.25.254.50 server1 master
172.25.254.1 server2 node1
172.25.254.2 server3 node2
13
初始化hadoop服务
[root@server1 sbin]# hdfs namenode -format
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = server1/172.25.254.50
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.3
STARTUP_MSG: classpath = /usr/local/hadoop/
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
18/08/25 22:03:36 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
18/08/25 22:03:36 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
18/08/25 22:03:36 INFO util.GSet: Computing capacity for map NameNodeRetryCache
18/08/25 22:03:36 INFO util.GSet: VM type = 64-bit
18/08/25 22:03:36 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
18/08/25 22:03:36 INFO util.GSet: capacity = 2^15 = 32768 entries
Re-format filesystem in Storage Directory /usr/local/hadoop/hdfs/name ? (Y or N) y
18/08/25 22:03:38 INFO namenode.FSImage: Allocated new BlockPoolId: BP-579432207-172.25.254.50-1535205818224
18/08/25 22:03:38 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/name has been successfully formatted.
18/08/25 22:03:38 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hdfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
18/08/25 22:03:38 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hdfs/name/current/fsimage.ckpt_0000000000000000000 of size 351 bytes saved in 0 seconds.
18/08/25 22:03:38 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/08/25 22:03:38 INFO util.ExitUtil: Exiting with status 0
18/08/25 22:03:38 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at server1/172.25.254.50
************************************************************/
初始化完成14
开启服务
[root@server1 sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-server1.out
node1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-server2.out
node2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-server3.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-server1.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-server1.out
node1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-server2.out
node2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-server3.out15
通过java自带的jsp命令查看是否开启
master端
[root@server1 sbin]# jps
5026 DataNode
4934 NameNode
5718 Jps
5175 SecondaryNameNode
5352 ResourceManager
5452 NodeManager
node端
[root@server2 .ssh]# jps
2625 DataNode
2725 NodeManager
2779 Jps
16
浏览器测试
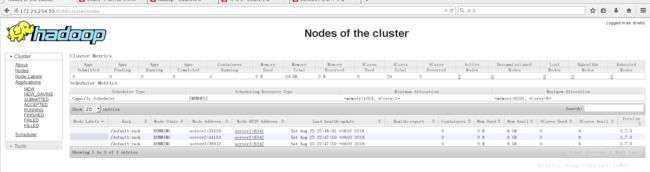
ok
17
上传文件测试
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/root(我使用root用户 也可以使用hadoop用户 但需要重新配置初始化文件 否则至用空目录)
$ bin/hdfs dfs -put input/
浏览器中查看即可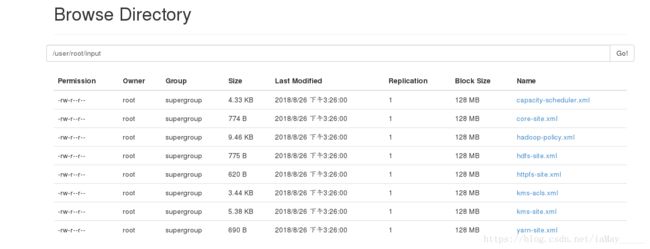
如图 用户指定有误时 没有文件 需要指定用户所拥有的文件才可以(input文件是root建立的)


18
通过共享文件系统来搭建其他的server
根据hadoop所属的用户 建立nfs共享文件
所有主机安装
[root@server2 mnt]# yum install nfs-utils
先开启rpcbind 再开启nfs
##########################################3
master端 编辑配置文件 (我使用root用户 所以规定root用户 自行选择)
[root@server1 hadoop]# cat /etc/exports
/usr/local/hadoop *(rw,anonuid=0,anongid=0)
共享成功
[root@server1 hadoop]# showmount -e 172.25.15.6
Export list for 172.25.15.6:
/usr/local/hadoop *
##################################################3
server端直接挂载即可 挂载与master相同目录下
没有可以自己创建
[root@server2 mnt]# mount 172.25.15.6:/usr/local/hadoop /usr/local/hadoop
[root@server2 mnt]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1902572 16259780 11% /
tmpfs 380152 0 380152 0% /dev/shm
/dev/sda1 495844 33453 436791 8% /boot
172.25.15.6:/usr/local/hadoop 19134336 4882560 13279872 27% /usr/local/hadoop
###################################################################
查看jps
master端
[root@server1 hadoop]# jps
3636 Jps
2437 SecondaryNameNode
1079 Main
2171 NameNode
2287 DataNode
###########################################
server端
[root@server2 mnt]# jps
1670 DataNode
905 Main
1785 Jps
可以看到 server只作为数据节点使用19
上传文件测试服务是否正常
[root@server1 hadoop]# bin/hdfs dfs -put /etc/passwd
上传ok
[root@server1 hadoop]# bin/hdfs dfs -ls passwd
-rw-r--r-- 2 root supergroup 1632 2018-08-26 16:12 passwd
##############################################################
可以在使用 -get 将文件down下来
[root@server1 hadoop]# bin/hdfs dfs -get passwd
[root@server1 hadoop]# ll passwd
-rw-r--r-- 1 root root 1632 Aug 26 16:20 passwd在浏览器中查看
